Bilibili 《后浪》短视频评论递归爬取极简教程
Bilibili 《后浪》短视频评论递归爬取极简教程
背景
短视频《后浪》这两天引起了很多网友的讨论,正负面皆有,但是我们必须用“科学地”眼光取看待问题,所以获取大量数据来支撑我们的分析是必要的,所以本次的探索主题就是获取Bilibili上《后浪》的全部评论数据。

说明
虽然现在爬虫教程真的很多,但是这次爬取Bilibili评论主要是介绍编程中递归处理数据手法的运用,所以还是有些意义的。
环境准备
编程语言: python 3.6
第三方模块:requests
编辑器:pycharm
浏览器:chrome
网络请求分析:
1.打开chrome,进入Bilibili,搜索关键字 后浪:
2. 滑到评论区:
3. F12打开控制台,清空全部网络请求:
4. 点击第2页评论,观察网络请求数据:
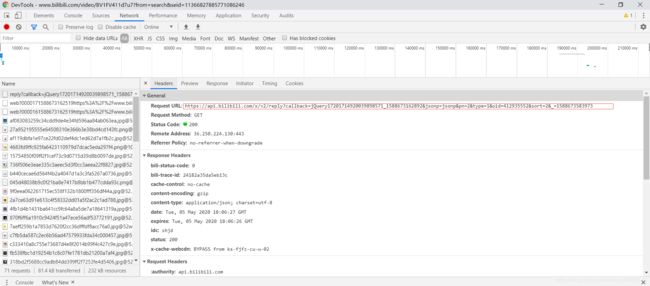
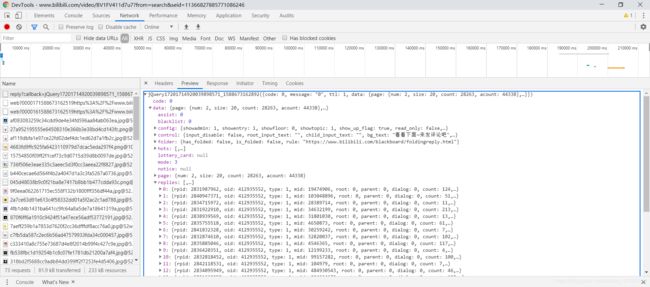
通过对比请求/响应数据定位评论请求URL为:
https://api.bilibili.com/x/v2/reply?callback=jQuery17201714920039898571_1588673162892&jsonp=jsonp&pn=2&type=1&oid=412935552&sort=2&_=1588673583973
5.解析URL请求参数
- callback:请求返回数据后的回调函数,用于渲染返回数据
- jsonp:jsonp指定服务器返回的数据类型为jsonp格式,配合回调函数使用
- pn:多次点击翻页后可以发现 pn是page number的缩写,代表当前所在评论页序号
- type:未知
- oid:经过分析认为是当前视频ID代码
- sort: 数据排序方式,具体未知
- &_:未知
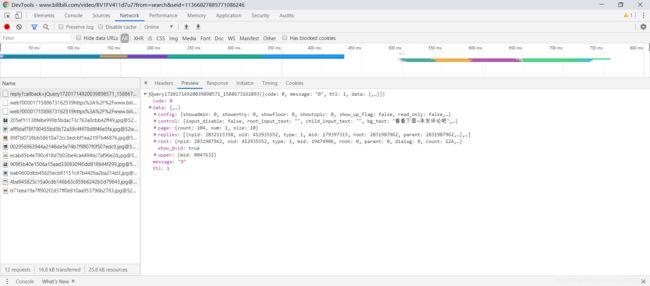
6.解析评论数据格式:
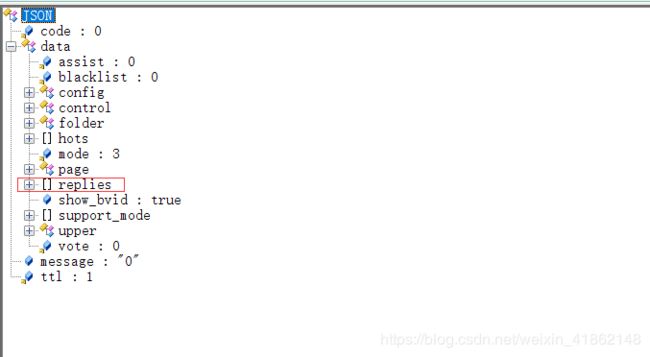
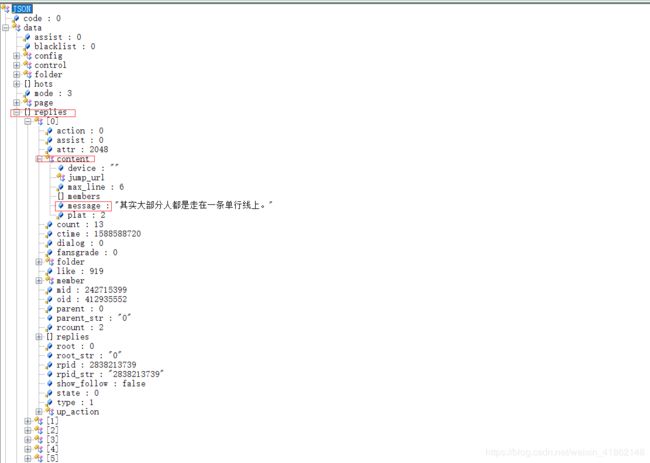
从相应数据可以看出Bilibili评论的数据格式封装的很复杂,包括了评论人账号信息以及评论内容主体和一些用于构造父-子结构的标识信息。不过这里面对我们有用的字段只是评论主体,我们需要关注的字段:
- data:存储评论数据的Key
- content:存储评论内容的Key
- message:评论字面量,也就是我们要提取的数据
从数据结构以及页面可以看出,评论主体是层级结构的,因为里面还有评论的评论,也就是子评论主体,那么,这部分评论该如何获取呢?
子评论网络请求分析
1.清空控制台全部网络请求
2.回到评论页面,选中一条有子评论的评论,点击点击查看,观察网络请求:
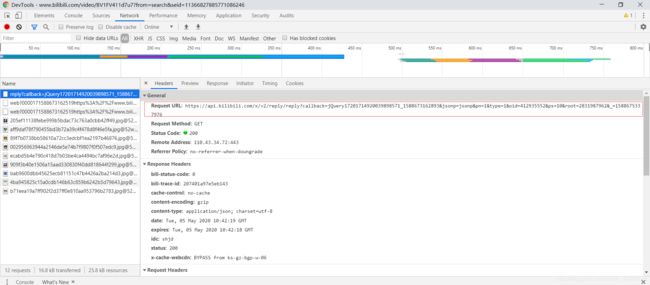
通过对比请求/响应数据可以定位到子评论请求URL为:
https://api.bilibili.com/x/v2/reply/reply?callback=jQuery17201714920039898571_1588673162893&jsonp=jsonp&pn=1&type=1&oid=412935552&ps=10&root=2831987962&_=1588675337976
可以发现,与直接评论相比,子评论增加了查询参数:
- ps:返回数据长度参数
- root:经过分析,root参数就是父评论的唯一识别号,key值为rpid,可以认为是reply_id的缩写
思路
1.将主评论请求URL与子评论请求URL抽象为模板字符串,将当前所在页参数和 root 参数模板化,去除不需要的回调函数参数
- 主评论请求URL字符串模板
parent_url_template = 'https://api.bilibili.com/x/v2/reply?pn={}&type=1&oid=412935552&sort=2'
- 子评论请求URL字符串模板
sub_url_template = 'https://api.bilibili.com/x/v2/reply/reply?pn={}&type=1&oid=412935552&ps=20&root=%(root)s'
2.构建get_replies函数,利用while构造循环结构,设置page_number计数器,每循环一次,请求页数增加 1,直到请求内容错误为止
3.构造 exact_reply函数,提取所有评论内容,写入磁盘文件 replies.txt
4.在遍历评论时,如果发现其存在子评论,则递归调用get_reply函数。直到全部数据获取完毕。
代码编写
本程序代码量很少,首先给出整体代码:
# -*- coding: UTF-8 -*-
"""
获取Bilibili《后浪》 短视频评论数据集
"""
import json
from util.data_fetch import fetch_data
parent_url_template = 'https://api.bilibili.com/x/v2/reply?pn={}&type=1&oid=412935552&sort=2'
sub_url_template = 'https://api.bilibili.com/x/v2/reply/reply?pn={}&type=1&oid=412935552&ps=20&root=%(root)s'
reply_save_file = open('replies.txt', 'w+', encoding='UTF-8')
def get_replies(data_url_template):
"""
获取评论数据
"""
page_number = 0
while True:
request_url = data_url_template.format(page_number)
print('URL:==> ' + request_url)
response_data = fetch_data(request_url)
if response_data is None:
break
reply_data = json.loads(str(response_data, 'UTF-8'))
if reply_data.get('data') is None or reply_data.get('data').get('replies') is None:
break
else:
exact_reply(reply_data.get('data').get('replies'))
page_number += 1
def exact_reply(replies):
"""
提取评论内容
"""
for reply in replies:
reply_save_file.write(reply.get('content').get('message') + "\n")
# 判断是否存在子评论
if reply.get('replies') is not None:
rpid = reply.get('rpid')
_data_url_template = sub_url_template % {'root': rpid}
get_replies(_data_url_template)
if __name__ == '__main__':
get_replies(parent_url_template)
reply_save_file.close()
data_fecth是一个简单工具类,用于判断请求是否成功并返回请求数据,源码如下:
# -*- coding: UTF-8 -*-
import requests
def fetch_data(data_url):
"""
数据请求工具
:param data_url: 数据地址
:return: 响应数据
"""
res = requests.get(data_url)
if res.status_code != 200:
return None
else:
return res.content
代码解释
- 在
get_replies中循环请求评论数据,直到响应为None。但是当请求的数据不存在时,Bilibili也不会返回404,而是返回一些提示信息。所以要利用以下代码来判断响应数据中是否还包含评论信息,否则跳出循环请求
reply_data.get('data') is None or reply_data.get('data').get('replies') is None
- 当数据成功返回时,调用
exact_reply提取评论数据,并写入replies.txt文件 - 在
exact_reply处理主评论数据时,如果发现其下面存在子评论,则取出主评论的rpid值作为root参数值并调用get_replies获取子评论数据
运行结果
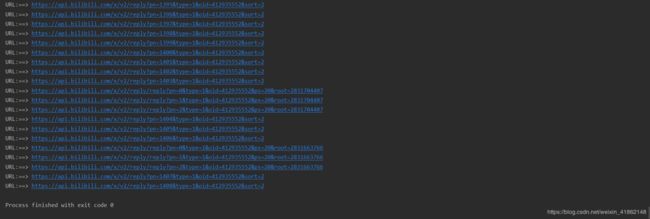
主程序总计运行40min,因为评论数据量很大,有7w多条,中间并未出现异常。部分评论数据如下:
完整数据并没有上传,大约4.28M。如文中有错误之处,还望指出。
