Neural Collaborative Filtering(NCF) 代码实战(Keras)
博客主要分为两部分。第一部分为论文简介,第二部分为代码实战。
论文简介:
1. 通用框架
下图是作者提出的用神经网络解决推荐系统问题的通用框架。论文先将用户与物品分别进行one-hot编码,然后通过一个Embedding层映射得到对应的向量,这就类似于矩阵分解(MF)中用户与物品的潜在相量。通过此操作可以使网络自己训练调整参数,还可以降低以及控制输入神经网络的维度。
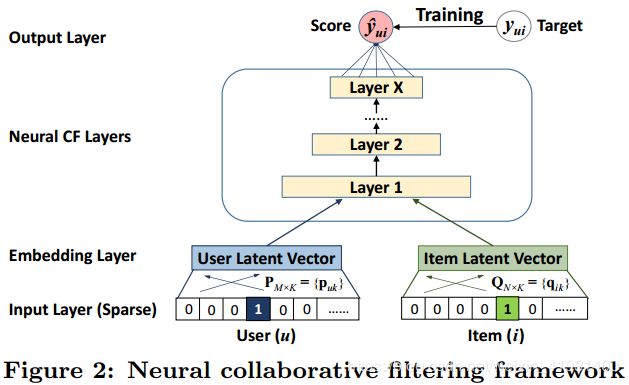
2. GMF

GMF被称为广义矩阵分解,其原理图如上图所示(图片取自如雨星空的博文,链接在最后给出)。使用用户与物品Embedding后的潜在向量作为输入,输出层的计算公式为:
![]()
3. MLP
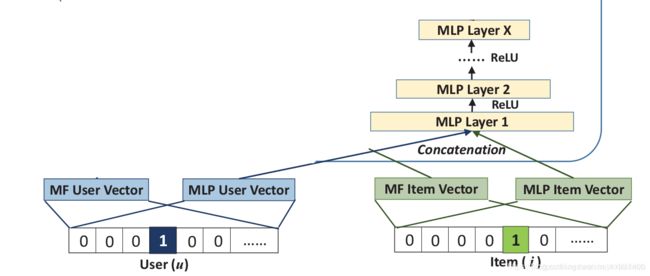
论文使用MLP(多层感知机)来学习用户和物品潜在向量之间的相互作用。网络示意图如上所示。MLP的计算公式:

4. NeuMF
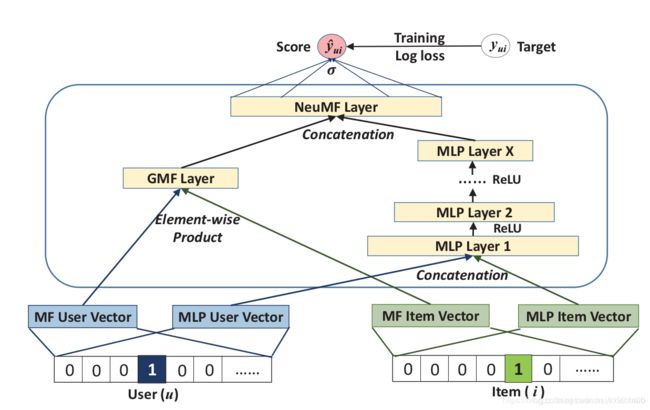
将前面介绍的GMF与MLP相融合就得到了论文所提出的NeuMF,即NCF。作者让GMF和MLP共享相同的嵌入层(Embedding Layer),为了使得融合模型具有更大的灵活性,允许GMF和MLP学习独立的嵌入,并通过拼接它们最后的隐层输出使两种模型融合。具体公式如下:

5. 几个实验重点
- 论文采用leave-one-out。即,将每个用户最近的一次交互作为测试集(时间戳),将剩余记录作为训练集。为节省时间,随机抽取100个用户没有评分记录的物品,将测试物品与这100个物品一同评分然后排列。命中率(HR)和归一化折扣累积增益(NDCG)作为评估标准,且截取长度为10。因此,HR衡量测试项目是否存在于前10名列表中,而NDCG确定其位置。将这两个指标求取平均分作为衡量指标。
- 负采样。隐性反馈为1时代表此用户与该物品有交互记录,但不代表此用户真的喜欢该物品。值为0时也不能反应用户不喜欢该物品,也有可能是用户没有遇到该物品。对此作者从用户没有评分记录的物品中进行抽样来作为负反馈。
- 预训练。权重的初始化(initialization)在深度学习模型的收敛性和性能的方面起到了重要的作用。由于 NeuMF 是 GMF 和 MLP 的组合,作者建议使用 GMF 和 MLP 的预训练模型来初始化NeuMF。在输出的权重采用参数来将两者的权重进行初始化:
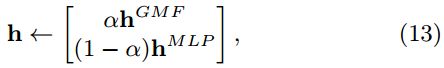
代码实战
论文作者原代码:https://github.com/hexiangnan/neural_collaborative_filtering
由于这份代码使用的python2.,keras的版本也是1.0.7,一直配置不好,总报错。使用Docker也没有成功的运行,自己动手改完GMF部分的代码后才发现已经有哥们改好了,于是clone下来看了下与原作者代码没有大的出入,也跑了一下没有出错,遂使用他的代码,代码链接:点这里。博客链接:如雨星空。
1. GMF
核心代码如下:
user_input = Input(shape=(1,), dtype='int32', name='user_input')
item_input = Input(shape=(1,), dtype='int32', name='item_input')
MF_Embedding_User = Embedding(input_dim=num_users, output_dim=latent_dim, name='user_embedding',
embeddings_regularizer = l2(regs[0]), input_length=1)
MF_Embedding_Item = Embedding(input_dim=num_items, output_dim=latent_dim, name='item_embedding',
embeddings_regularizer = l2(regs[1]), input_length=1)
user_latent = Flatten()(MF_Embedding_User(user_input))
item_latent = Flatten()(MF_Embedding_Item(item_input))
predict_vector = Multiply()([user_latent, item_latent])
#predict_vector = Add()([user_latent, item_latent])
prediction = Dense(1, activation='sigmoid', kernel_initializer='lecun_uniform', name = 'prediction')(predict_vector)
model = Model(inputs=[user_input, item_input], outputs=prediction)
Embedding只能作为模型的第一层,其重要参数:
- input_dim:大或等于0的整数,取值的可能数。比如ID类特征取值为0到5,则input_dim应该设为6
- output_dim:大于0的整数,代表全连接嵌入的维度
- input_length:输入序列的长度固定时,该值为其长度
Embedding层后如果需要接Dense层进行训练,必须使用Flattern层将Embedding层的二维输出矩阵平铺为一维。
2. MLP
核心代码如下:
assert len(layers) == len(reg_layers)
num_layer = len(layers) #Number of layers in the MLP
# Input variables
user_input = Input(shape=(1,), dtype='int32', name = 'user_input')
item_input = Input(shape=(1,), dtype='int32', name = 'item_input')
MLP_Embedding_User = Embedding(input_dim = num_users, output_dim = int(layers[0]/2), name = 'user_embedding',
embeddings_regularizer = l2(reg_layers[0]), input_length=1)
MLP_Embedding_Item = Embedding(input_dim = num_items, output_dim = int(layers[0]/2), name = 'item_embedding',
embeddings_regularizer = l2(reg_layers[0]), input_length=1)
# Crucial to flatten an embedding vector!
user_latent = Flatten()(MLP_Embedding_User(user_input))
item_latent = Flatten()(MLP_Embedding_Item(item_input))
# The 0-th layer is the concatenation of embedding layers
vector = Concatenate(axis=-1)([user_latent, item_latent])
# MLP layers
for idx in range(1, num_layer):
layer = Dense(layers[idx], W_regularizer= l2(reg_layers[idx]), activation='relu', name = 'layer%d' %idx)
vector = layer(vector)
# Final prediction layer
prediction = Dense(1, activation='sigmoid', init='lecun_uniform', name = 'prediction')(vector)
model = Model(input=[user_input, item_input],
output=prediction)
return model
-
用户与物品经embedding后的长度均为第一层全连接网络的1/2,将其拼接输入全连接网络。
-
使用for循环生成全连接层,代码更加简洁,可读性强。
3. NCF
核心代码如下:
assert len(layers) == len(reg_layers)
num_layer = len(layers) #Number of layers in the MLP
# Input variables
user_input = Input(shape=(1,), dtype='int32', name = 'user_input')
item_input = Input(shape=(1,), dtype='int32', name = 'item_input')
# Embedding layer
MF_Embedding_User = Embedding(input_dim = num_users, output_dim = mf_dim, name = 'mf_embedding_user',
embeddings_regularizer = l2(reg_mf), input_length=1)
MF_Embedding_Item = Embedding(input_dim = num_items, output_dim = mf_dim, name = 'mf_embedding_item',
embeddings_regularizer = l2(reg_mf), input_length=1)
MLP_Embedding_User = Embedding(input_dim = num_users, output_dim = int(layers[0]/2), name = "mlp_embedding_user",
embeddings_regularizer = l2(reg_layers[0]), input_length=1)
MLP_Embedding_Item = Embedding(input_dim = num_items, output_dim = int(layers[0]/2), name = 'mlp_embedding_item',
embeddings_regularizer = l2(reg_layers[0]), input_length=1)
# MF part
mf_user_latent = Flatten()(MF_Embedding_User(user_input))
mf_item_latent = Flatten()(MF_Embedding_Item(item_input))
mf_vector = Multiply()([mf_user_latent, mf_item_latent]) # element-wise multiply
# MLP part
mlp_user_latent = Flatten()(MLP_Embedding_User(user_input))
mlp_item_latent = Flatten()(MLP_Embedding_Item(item_input))
mlp_vector = Concatenate(axis = 1)([mlp_user_latent, mlp_item_latent])
for idx in range(1, num_layer):
layer = Dense(layers[idx], W_regularizer= l2(reg_layers[idx]), activation='relu', name="layer%d" %idx)
mlp_vector = layer(mlp_vector)
# Concatenate MF and MLP parts
predict_vector = Concatenate(axis = -1)([mf_vector, mlp_vector])
# Final prediction layer
prediction = Dense(1, activation='sigmoid', init='lecun_uniform', name = "prediction")(predict_vector)
model = Model(input=[user_input, item_input],
output=prediction)
return model
- 将GMF与MLP相结合,最后进行拼接输入至Dense层。
数据处理读取与结果的评价具体参考完整代码:https://github.com/wyl6/Recommender-Systems-Samples/tree/master/RecSys%20And%20Deep%20Learning/DNN/ncf
参考:
- https://blog.csdn.net/xxiaobaib/article/details/99116755
- https://blog.csdn.net/livan1234/article/details/85057936