python爬彩票大乐透历史数据+预测测试...
好久没用python练手爬虫这次再试下爬大乐透,一般来说爬东西找对网页很关键,因为数据在一些网页是动态加载什么很多,而有些网页直接是以Json格式的,这样就相当好爬了,这次想找个好爬点的网页找了半天没找到,算了直接去体彩官网http://www.lottery.gov.cn/historykj/history.jspx?_ltype=dlt爬去,上代码
from bs4 import BeautifulSoup as bs
import requests
import os
def get_url():
data_1 = []
for i in range(1,91):
url = 'http://www.lottery.gov.cn/historykj/history_'+ str(i) +'.jspx?_ltype=dlt'
data = requests.get(url).text
data = bs(data,'lxml')
data = data.find('tbody').find_all('tr')
for content in data:
number = content.get_text().strip().replace('\r','').replace('\t','').replace('\n',' ')
with open('data_recent','a') as f:
f.write(number+'\n')
f.close()
if __name__ == '__main__':
get_url()
结果如图:

这个我以前尝试过,但是代码没找到了,有时想把数据更新更新还是在写一遍,但是原来用的是urllib,最近发现requests有时更方便简单啊,这里直接get就可以了,urllib还得加header 啥,光给个网址还打不开,多说一句 因为我一开始学的BeautifulSoup用习惯了,但是觉得lxml更简单方便,直接开发者工具里面右键copy xpath就可以了,接着就是个人想法了:先画个图看看!
import os
import pandas as pd
import numpy as np
data = pd.read_csv(r'C:\Users\Administrator\jupyter\dale1.csv',sep= ' ',header=None,error_bad_lines=False).values
data = data[:,2:]
import matplotlib as mpl
from mpl_toolkits.mplot3d import Axes3D
import matplotlib.pyplot as plt
fig = plt.figure(figsize=(10,10))
ax = fig.gca(projection='3d')
a = np.random.randint(0,5,size=100)
for i in range(1,8):
z = data[:100,i-1]
y = np.full_like(a,i)
x = range(100)
ax.plot(x, y, z)
ax.legend()
#ax.set_xlim=[0,8]
plt.tight_layout()
plt.savefig('img_3d.png')
plt.show()
注意这段代码用的数据是原来的数据,要把刚爬的数据稍微处理一下就和上面一样了,不多说效果如图:
3D图还可以旋转,看图像或代码也就知道我这里是取得最开始的100期,根据7个球每个球的波动画出来的,这里很好辨认,第一个数字永远比第二个数字小,依次内推,很有层次感,如果用每一期7个数画线,它会上下波动难以辨认,如图:
图画了很多没看出个啥,接着用统计吧!基于任一期的数字,统计这一期之前的所有期第几个球出现这个数字时是增大还是减小的概率,结果是这样(PS:这是以前双色球的,大乐透我直接整在下面代码里,当然也可以输出来):

这是统计这一期之前所有期第1-7(行0-6)个球分别是1-36(列0-35)时它会增大的概率,减小或相等与之类似,先对爬下来的数据进行处理,将近期的数据放最后面,也就是将索引反过来排列用pandas读了好久读不出来,仔细一看数据不规范:
还好后面的数据没用那就换个方法吧:
import os
with open (r"C:\Users\Administrator\jupyter\data_recent.csv",'r',encoding='utf-8') as f:
with open('.\simple_data.csv','a') as file:
for line in f:
file.write(line[:26]+'\n')
f.close()
file.close()
现在可以统计了:
import numpy as np
import pandas as pd
import os
data = pd.read_csv(r"C:\Users\Administrator\jupyter\simple_data.csv",sep=' ',header=None)
data=data.sort_index(ascending=False).values#数据反过来
data = data[:,1:]
def fengbu(i):
abb={}
for l in range(7):
for n in range(1,36):
abb[l,n]=[]
for qiu in range(i-1):
if data[qiu][l] ==n:
a = data[qiu+1][l] - data[qiu][l]
abb[l,n].append(a)#一个大字典为{(l,n):a}
dict1={}
dict2={}#每个数字增大的概率
add1={}#增大的次数
reduce={}#减小的次数
da={}
jian={}
da1 =[]
jian1=[]
dict21=[]
for n,l in abb.items():
add1[n]=0
reduce[n]=0
da[n] =0
jian[n]=0
for m in l:
if m > 0 :
add1[n]+=1#统计往期为这个数字时下次增大次数
elif m <0:
reduce[n]+=1#减小次数
dict2[n] = round(add1[n] / (reduce[n]+ add1[n]+1),4)
#得到前面那张概率图 减小和它相反
for m in set(l):
if m >0:
dict1[n,m]=(round(l.count(m) / add1[n],4))* m
da[n]+=dict1[n,m]
'''
这是基于首先判断当前期每个数字增大或减小概率哪个大
数值大的进一步细化,即将具体增大或减小的值得概率当
成权重再分别与之对应值相乘,在全部相加为下一次预测值
'''
elif m<0:
dict1[n,m]=(round(l.count(m) / reduce[n],4))* m
jian[n]+=dict1[n,m]
elif m ==0:
dict1[n,m]=0#两次数字不变
for n,m,l in zip(da.values(),jian.values(),dict2.values()):
da1.append(n)#原来是字典现在要将其弄成矩阵
jian1.append(m)
dict21.append(l)
da1=np.array(da1).reshape(7,35)
jian1=np.array(jian1).reshape(7,35)
dict21=np.array(dict21).reshape(7,35)
#shuan
return da1,jian1,dict21
def predict(i):
for red in range(7):
print(round(data[:,red].mean(),4),round(data[:,red].std(),4))
当前均值 方差
da1,jian1,dict21 = fengbu(i)
predict =np.zeros(7)
for l in range(7):
for m in range(1,34):
if data[i][l]==m:
if dict21[l][m-1]>0.5:
print(dict21[l][m-1],da1[l][m-1],data[i][l])
#每期每个数字增大或减小概率,权重和,每个数字值
predict[l]=data[i][l]+ da1[l][m-1]
elif dict21[l][m-1]<0.5:
print(dict21[l][m-1],jian1[l][m-1],data[i][l])
predict[l] =data[i][l]+jian1[l][m-1]
print("第 %d 次,结果是:%s" % (i,data[i]))
print("所以预测下一次是:%s" % predict)
print("真正下一次是:%s" % data[i+1])
print('*'*50)
if __name__ =='__main__':
predict(1641)

双色球也一样,把range(1,36)改为range(1,33),reshape(7,33)改为reshape(7,35)就行,这个还有点意思,最好见过对5个,两个相差2以内,但大多数都。。,毕竟这个是基于统计如果概率大的就对,那概率应该趋向于1才对,所以有时个别值过大或者过小,以前从没有出现过这个数,那将没有预测值即为0,有时预测的两个值相等。可以将最后面代码改一下只看结果不要均值方差多来几组:

尝试用神经网络预测一下会是什么结果?贴出来看看:
import pandas as pd
import numpy as np
import os
data = pd.read_csv(r'C:\Users\Administrator\jupyter\dale1.csv',sep=' ',header=None,error_bad_lines=False).values
data = data[:,2:]
mean = data[:1500].mean(axis=0)
std = data[:1500].std(axis=0)
data1 = data.copy()
data1 -= mean
data1 /= std
train_data = data1[:1400]
train_data= np.expand_dims(train_data,axis=1)
val_data = data1[1400:1550]
val_data = np.expand_dims(val_data,axis=1)
test_data = data1[1550:len(data)-1]
test_data = np.expand_dims(test_data,axis=1)
red1_labels = data[:,0]
red2_labels = data[:,1]
red3_labels = data[:,2]
red4_labels = data[:,3]
red5_labels = data[:,4]
blue1_labels = data[:,5]
blue2_labels = data[:,6]
train_labels_1 = red1_labels[1:1401]
train_labels_2 = red2_labels[1:1401]
train_labels_3 = red3_labels[1:1401]
train_labels_4 = red4_labels[1:1401]
train_labels_5 = red5_labels[1:1401]
train_labels_6 = blue1_labels[1:1401]
train_labels_7 = blue2_labels[1:1401]
val_labels_1 = red1_labels[1401:1551]
val_labels_2 = red2_labels[1401:1551]
val_labels_3 = red3_labels[1401:1551]
val_labels_4 = red4_labels[1401:1551]
val_labels_5 = red5_labels[1401:1551]
val_labels_6 = blue1_labels[1401:1551]
val_labels_7 = blue2_labels[1401:1551]
test_labels_1 = red1_labels[1551:]
test_labels_2 = red2_labels[1551:]
test_labels_3 = red3_labels[1551:]
test_labels_4 = red4_labels[1551:]
test_labels_5 = red5_labels[1551:]
test_labels_6 = blue1_labels[1551:]
test_labels_7 = blue2_labels[1551:]
from keras import layers
from keras import Model
from keras import Input
from keras.optimizers import RMSprop
post_input = Input(shape=(None,7),name='post_input')
lstm = layers.LSTM(150,dropout=0.2,recurrent_dropout=0.2,activation='relu',return_sequences=True)(post_input)
lstm1=layers.LSTM(250,dropout=0.2,recurrent_dropout=0.2,activation='relu')(lstm)
x= layers.Dense(360,activation='relu')(lstm1)
x=layers.Dense(250,activation='relu')(x)
x=layers.Dense(250,activation='relu')(x)
x= layers.Dense(250,activation='relu')(x)
x= layers.Dense(250,activation='relu')(x)
x= layers.Dense(250,activation='relu')(x)
x= layers.Dense(140,activation='relu')(x)
x= layers.Dense(70,activation='relu')(x)
#x=layers.Dropout(0.3)(x)
red1_predict = layers.Dense(1,name='red1')(x)
red2_predict = layers.Dense(1,name='red2')(x)
red3_predict = layers.Dense(1,name='red3')(x)
red4_predict = layers.Dense(1,name='red4')(x)
red5_predict = layers.Dense(1,name='red5')(x)
blue1_predict = layers.Dense(1,name='blue1')(x)
blue2_predict = layers.Dense(1,name='blue2')(x)
model = Model(post_input,[red1_predict,red2_predict,red3_predict,red4_predict,red5_predict,blue1_predict,blue2_predict])
model.compile(optimizer = RMSprop(1e-4),loss=['mse','mse','mse','mse','mse','mse','mse'],metrics=['acc','acc','acc','acc','acc','acc','acc'])
history= model.fit(train_data,[train_labels_1,train_labels_2,train_labels_3,train_labels_4,train_labels_5,train_labels_6,train_labels_7],
batch_size=20,epochs=50,validation_data=(val_data,[val_labels_1,val_labels_2,val_labels_3,val_labels_4,val_labels_5,
val_labels_6,val_labels_7]))
import matplotlib.pyplot as plt
loss = history.history['loss']
loss = loss[3:]
val_loss = history.history['val_loss']
val_loss = val_loss[3:]
epochs = range(1,len(loss)+1)
plt.figure()
plt.plot(epochs, loss, 'b',color='r', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()
损失图像如图:
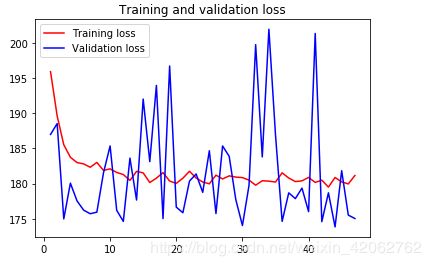

果然和想的一样,根据损失函数它只会趋向某一固定值以确保数值无论如何变换它的损失一直稳定减小的,而验证数据会有使其损失很大的时候,所以它的任何预测结果也是一直在固定数值附近波动,(将目标值采用one-hot编码,结果也是只是一样,只不过是另一组固定值)所以感觉原来那个还好点,但会不会存在更好的损失函数符合这种波动,而不是mse呢。。欢迎留言!也算将python实操一遍吧。