第一部分讲完之后,有读者提出意见,说关于函数部分讲的太少,对于函数该如何设计和使用还缺少体会。因此,这里再补充一节课,说明一下,函数的一些更多知识和经验。
1.函数的定义
def function(params):
block
return expression/value
这个样式大家已经清楚,需要特别说明一下:
(1)采用def定义函数,无需指明返回值的类型
(2)函数参数params可以是0个、1个或者多个,参数也无需指明类型
(3)return语句可写可不写,return后面不能再有代码,不写return则自动返回NONE
下面是一些例子:
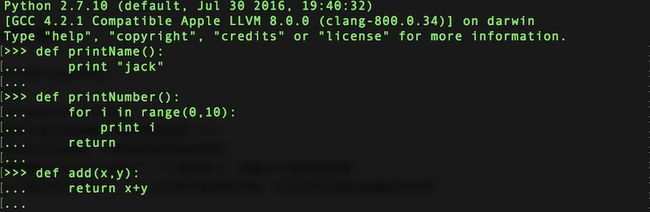
2.函数的使用
先定义函数,再使用函数:

python中不允许前向引用,也就是必须def函数在使用函数之前,如果反过来就会出错。
新建一个testadd.py文件,代码如下:
print add(3,5)
def add(x,y):
return x+y
然后运行 testadd.py文件,会发现报错:name 'add' is not defined
3.参数传递
函数的参数类型,分为2大类:
不可变类型和可变类型。
不可变类型:整数,字符串,元组,数值。
可变类型:列表,字典。
如果参数是可变类型,那么函数内部改变了该参数变量的值,则函数外部该变量的值同样被改变。
要根据实际情况来使用这种特征,有些情况如果不希望改变原来的参数值,那么可以在函数内部读取后赋值给一个新的变量;
这个前面教程0015里面有例子,这里只是补充说明一下。
4.常用系统内建函数
abs(x) 返回一个数字的绝对值。
cmp(x,y) 比较2哥对象大小,如果xy返回1,如果x==y返回0。
divmod(x,y) 除法运算,返回商和余数。
isinstance(object,class-or-type-or-tuple) 测试对象类型,返回bool。
len(object) 返回字符串或者序列的长度。
type(obj) 返回对象的数据类型。
min(x[,y,z...]) 返回给定参数的最小值,参数可以为序列。
max(x[,y,z...]) 返回给定参数的最大值,参数可以为序列。
还有其它的就不一一列出了,大家自行搜索,然后在python环境中进行测试验证具体的用法。
5.递归函数
在函数内部,可以调用其它函数。如果一个函数在内部调用自身本身,这个函数就是递归函数。
来看一个例子,计算阶乘n!=1*2*3*...*n,用函数fact(n)表示,可以推理出:
fact(n)=n!=1*2*3*...*(n-1)*n=(n-1)!*n=fact(n-1)*n
所以fact(n)可以使用n*fact(n-1),注意当n=1时需要特殊处理
于是,代码就是这样的:

python是如何进行计算的呢,我们以fact(5)做为例子来单步跟踪看看。
fact(5)进入函数内部,不满足n==1的情况,执行下一句
return 5*fact(4),这时候,程序并不会返回,因为又碰到函数调用,python会将当前的5*保存到一个栈里面
然后去运行fact(4)函数
fact(4)进入函数内部,不满足n==1的情况,执行下一句
return 4*fact(3),这时候,程序并不会返回,因为又碰到函数调用,python会将当前的4*保存到一个栈里面
,这时候栈里面有2个元素,最里面是5*,上面是4*,然后去运行fact(3)函数
fact(3)进入函数内部,不满足n==1的情况,执行下一句
return 3*fact(2),这时候,程序并不会返回,因为又碰到函数调用,python会将当前的3*保存到一个栈里面
,这时候栈里面有3个元素,最里面是5*,上面是4*,上面是3*,然后去运行fact(2)函数
fact(2)进入函数内部,不满足n==1的情况,执行下一句
return 2*fact(1),这时候,程序并不会返回,因为又碰到函数调用,python会将当前的2*保存到一个栈里面
,这时候栈里面有4个元素,最里面是5*,上面是4*,上面是3*,上面是2*,然后去运行fact(1)函数
fact(1)进入函数内部,满足n==1的情况,执行return 1语句
这时候,碰到return,则栈里面的最上面的2*会出栈,栈里面剩余5*4*3*总共3个,执行2*1,然后执行return 2
这时候,碰到return,则栈里面的最上面的3*会出栈,栈里面剩余5*4*总共2个,执行3*2,然后执行return 6
这时候,碰到return,则栈里面的最上面的4*会出栈,栈里面剩余5*总共1个,执行4*6,然后执行return 24
这时候,碰到return,则栈里面的最上面的5*会出栈,栈里面剩余0个,执行5*24,然后执行return 120
这时候,由于栈里面空了,就return数据返回。得到结果120。
递归函数的优点是定义简单逻辑清晰,但是需要注意防止栈溢出,也就是死循环调用。
假如上面的fact函数里面缺少if n==1这个代码就会导致死循环调用,这一定要避免。
再来看看,之前我们做过的斐波拉契数列,也可以改造为递归函数,会看起来
更简洁:
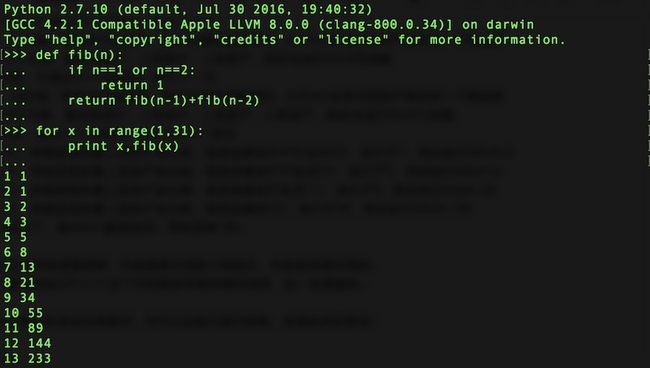
相信大家在运行的时候会发现一个问题:运行速度比较慢。这是因为递归调用需要频繁的进栈出栈,消耗比较大。
可见,有时候,代码简洁并不一定是效率最高的方法,要根据实际情况灵活决定。
6.函数和模块设计定义的一些经验
一般而言,有这样一些约定俗成的经验:
(1)将函数设计成简单的功能性单元,理想情况下,函数应简明扼要,若长度很大,可考虑分割成较短的几个方法。
(2)设计一个函数时,设身处地为使用这个函数的程序员考虑一下,使用方法应该是非常明确的。
(3)模块应尽可能短小精悍,而且只解决一个特定的问题,更有利于维护和灵活搭配组合使用。
(4)尽可能的“私有”。就是函数内部的变化对外部调用尽量减少干扰和改变,也就是不要修改或保存传入的数据。
(5)尽可能细致的加上注释,方便使用者和维护者。
(6)避免使用“魔术数字”,应创建常量,并使用有说明力的描述性名称,更易理解和维护。
(7)重要的参数在前,次要的参数在后且有默认值。
因为学哥也没有用python来做过真正的大项目,不过参照以前做java项目的经验来看,一个方法,只要发现有重复代码出现,就说明需要将这些重复代码独立出来做成函数,就是将代码不停的拆分拆分,直到感觉是在不能再拆了为止,如果调用的时候感觉有问题,再考虑合并或者调换等修改。总之,其中的一些感悟,只可意会,要靠大家在实际运用过程中不断分析总结。