Python-爬虫框架Pyspider
Python-爬虫框架Pyspider
PySpider: 强大的网络爬虫系统,并自带有强大的webUI
1、框架特性
- python 脚本控制,可以用任何你喜欢的html解析包(内置 pyquery)
- WEB 界面编写调试脚本,起停脚本,监控执行状态,查看活动历史,获取结果产出
- 支持 MySQL, MongoDB, SQLite
- 支持抓取 JavaScript 的页面
- 组件可替换,支持单机/分布式部署,支持 Docker 部署
- 强大的调度控制
2、可能遇到的问题
windows 下安装问题:http://docs.pyspider.org/en/latest/Frequently-Asked-Questions/#does-pyspider-work-with-windows
- 架构 ABOUT
- 模块
webui:web的可视化任务监控,web脚本编写,单步调试,异常捕获,log捕获,print捕获等
scheduler:任务优先级,周期定时任务,流量控制,基于时间周期或前链标签(例如更新时间)的重抓取调度
fetcher:用于拉取数据,其中涉及到phantomjs的拉取,使用代理来实现
processor:用于页面解析数据提取工作,这里提供如pyquery等选择器api
- 数据持久层database、result
- 信息传导层 massage_queue
3、数据处理流程
- 各个组件间使用消息队列连接,除了scheduler是单点的,fetcher 和 processor 都是可以多实例分布式部署的。scheduler 负责整体的调度控制
- 任务由 scheduler 发起调度,fetcher 抓取网页内容, processor 执行预先编写的python脚本,输出结果或产生新的提链任务(发往 scheduler),形成闭环。
- 每个脚本可以灵活使用各种python库对页面进行解析,使用框架API控制下一步抓取动作,通过设置回调控制解析动作。
4、Demo源码分析
demo 地址:http://demo.pyspider.org/debug/douban_rent_lzh_sample
5、运行PySpider
- 在命令行输入,打开浏览器输入:http://localhost:5000,就可以进入pyspider的后台了
- 点击Create,输入爬虫项目名称,点击确定之后就进入一个脚本编辑器,可以开始编写爬虫代码
6、具体业务逻辑
7、主要模块
- 调度程序从两个不同的队列中获取任务(newtask_queue和status_queue),并把任务加入到另外一个队列out_queue,这个队列稍后会被抓取程序读取。
- 调度程序做的第一件事情是从数据库中加载所需要完成的所有的任务。之后,它开始一个无限循环。在这个循环中会调用几个方法:
- 主要有 tornado_fetcher.py 和 phantomjs_fetcher.js 两个文件。两种不同程序、不同语言之间的交互使用这种监视端口和请求的模型,能够最大程度降低耦合。
- phantomjs_fetcher是在phantomjs上运行的脚本,负责监视固定端口请求,这样就可以接受来自fetcher的phantomjs_fetcher请求。
- 在phantomjs_fetcher里面,就使用了web_server_module,进行端口监听,使用page module请求,执行javaScript,然后封装好response返回给请求者
- 接收来自于fetcher的task,调用task内封装好的处理函数(callback),并将合适的进行输出(到result),其他的有后续任务的重新放入消息队列返回scheduler之中。
8、反爬虫策略
- self.crawl 中增加 auto_crawl=True,并设置好间隔时间,比如 age=60*60 这样一个小时后,pyspdier会去自动抓取网页
- 修改 webui 中的 rate/burst,降低抓取频率
- 可以在 crawl_config 中增加 proxy
9、部署
- 因为pyspider 是有多个组件组成,所以你不仅可以启动标准的进程,你还可以使用第三方进程管理工作来单独管理组件甚至可以使用第三方的免费实例来运行。你也可以使用mysql或mongodb和RabbitMQ部署成集群。
- 命令行部署
- 使用 Docker 部署,参考文档:http://docs.pyspider.org/en/latest/Running-pyspider-with-Docker/
10、爬虫框架pyspider的使用
- 前期准备:
1、安装pyspider:pip3 install pyspider
2、安装Phantomjs:在官网下载解压后,并将pathtomjs.exe拖进安装python路径下的Scripts下即可。
下载地址:https://phantomjs.org/dowmload.html
官方API地址:http://phantomjs.org/api/
- 用法(这里只简要介绍,更多请看官方文档):
1、首先启动pyspider
在黑窗口中输入pyspider all 即可看到如下。
提醒我们在http://localhost:5000端口打开即可。(注意不要关闭!)
打开后点击右边的Create创建项目,Project Name是项目名称,
Start URL(s)是你要爬取的地址点击Create就可以创建一个项目。
2、了解pyspider的格式和过程
创建之后我们会看到如下:
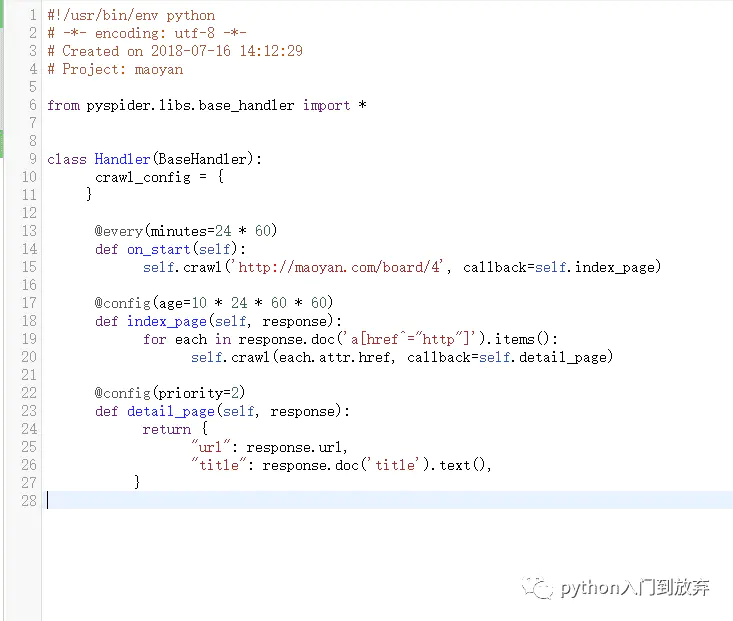
Handler方法是pysqider的主类,继承BaseHandler,所有的功能,只需要一个Handler就可以解决。
crawl_config = {}表示全局的配置,比如可以之前学的那样,定义一个headers
@every(minutes=24 * 60)every属性表示爬取的时间间隔,minutes=24*60即是一天的意思,也就是说一天爬取一次。
on_start方法:是爬取的入口,通过调用crawl方法来发送请求,
callback=self.index_page:callback表示回调函数,也就是说将请求的结果交给index_page来处理。
@config(age=10 * 24 * 60 * 60)是设置任务的有效时间为10天,也就是说在10天内不会重复执行。
index_page函数:就是进行处理的函数,参数response,表示请求页面的返回内容。
接下来的内容相必大家也看得懂,通过pyquery解析器(pyspider可以直接使用该解析器)获取所有的链接。并依次去请求。然后调用detail_page来处理,得到我们想要的东西。
@config(priority=2)priority表示爬取的优先级,没有设置默认为0,数字越大,可优先调用。
crawl的其他参数:
exetime:表示该任务一个小时候执行
self.crawl('http://maoyan.com/board/4', callback=self.detail_page,exetime=time.time()+60*60)
retries:可以设置重复次数,默认为3
auto_recrawl:设置为True时,当任务过期,即age的时间到了之后,再次执行。
method:即HTTP的请求方式默认为get
params:以字典的形式添加get的请求参数
self.crawl('http://maoyan.com/board/4', callback=self.detail_page,params={'a':'123','b':'456'})
data:post的表单数据,同样是以字典的形式
files:上传文件
self.crawl('http://maoyan.com/board/4', callback=self.detail_page,method='post',files={filename:'xxx'})
user_agent:即User-Agent
headers:即请求头信息
cookies:字典形式
connect_timeout:初始化的最长等待时间,默认20秒
timeout:抓取页面的最长等待时间
proxy:爬取时的代理,字典形式
fetch_type:设置成js即可看到javascript渲染的页面,需要安装Phantomjs
js_script:同样,也可以执行自己写的js脚本。如:
self.crawl('http://maoyan.com/board/4', callback=self.detail_page,js_script='''
function(){
alert('123')
}
''')
js_run_at:和上面运行js脚本一起使用,可以设置运行脚本的位置在开头还是结尾
load_images:在加载javascript时,是否加载图片,默认为否
save:在不同方法之间传递参数:
def on_start(self):
self.crawl('http://maoyan.com/board/4', callback=self.index_page,save={'a':'1'})
def index_page(self,response):
return response.save['a']
3、保存之后的项目是这样的

status表示状态:
TODO:表示项目刚刚被创建的状态
STOP:表示停止
CHECKING:正在运行的项目被修改的状态
DEBUG/RUNNING:都是运行,DEBUG可以说是测试版本。
PAUSE:出现多次错误。
如何删除项目?
将group修改成delete,staus修改成STOP,24小时后系统自动删除
actions:
run表示运行
active tasks 查看请求
results 查看结果
tate/burst:
1/3表示1秒发送一个请求,3个进程
progress:表示爬取的进度。
注意:
pyspider安装遇到的坑记录
1、启动报错
raise ValueError("Invalid configuration:\n - " + "\n - ".join(errors))
ValueError: Invalid configuration:
- Deprecated option 'domaincontroller': use 'http_authenticator.domain_control
ler' instead.
解决方法:
将wsgidav替换为2.4.1
python -m pip install wsgidav==2.4.1
2、PhantomJS配置
windows:在官网http://phantomjs.org/download.html 。
下载对应版本的程序,然后放到python安装目录的python.exe同级目录下。