知识图谱概述(四)知识图谱历史发展
知识图谱系列文章列表:
知识图谱概述(一)知识图谱概念提出
知识图谱概述(二)知识图谱定义
知识图谱概述(三)知识图谱构成
知识图谱概述(四)知识图谱历史发展
知识图谱概述(五)知识图谱分类
知识图谱概述(六)知识图谱技术应用
要深入了解一个技术,就要知道这个技术在历史上如何发展而来的。
知识图谱号称人工智能领域的一颗掌上明珠,知识图谱的历史,要先从人工智能的三大学派说起。
(一)人工智能三大学派
发展到目前为止,人工智能分下列三大学派:
-
(1) 连接主义(connectionism),又称为仿生学派或生理学派,其主要原理为神经网络及神经网络间的连接机制与学习算法。这里的智能我理解的是感知智能,比如语音识别、图像识别,主要让机器能够感知周围事物,而感知智能当前已经发展的非常成熟,比如人脸支付,语音翻译等已经大规模商用。
-
(2) 符号主义(symbolicism),又称为逻辑主义、心理学派或计算机学派,其原理主要为物理符号系统(即符号操作系统)假设和有限合理性原理。这里的智能我理解的是认知智能,也就是让机器像人一样思考,能够自我学习、理解知识,交流问题。而我们要介绍的知识图谱就属于这个学派。
-
(3) 行为主义(actionism),又称为进化主义或控制论学派,其原理为控制论及感知-动作型控制系统。这里的智能我理解的是行为智能,比如足球机器人,无人驾驶汽车。
符号派一直以来都处于人工智能研究的核心位置。但是近年来,随着数据的大量积累和计算能力的大幅提升,深度学习在视觉、听觉等感知处理中取得突破性进展,进而又在围棋等博弈类游戏、机器翻译等领域获得成功,使得人工神经网络和机器学习获得了人工智能研究的核心地位。
深度学习在处理感知、识别和判断等方面表现突出,能帮助构建聪明的人工智能,但在模拟人的思考过程、处理常识知识和推理,以及理解人的语言方面仍然举步维艰,这也是知识图谱发展的潜力所在。
(二)知识图谱历史发展
其实早在文艺复兴时期,培根就提出了“知识就是力量”,在当今人工智能时代,各大科技公司更是纷纷提出:知识图谱就是人工智能的基础。
知识图谱不是无缘无故诞生的技术,在此之前有许多相关联的技术给它做了铺垫,时间线如下:
1960 年,认知科学家 Allan M.Collins 提出用语义网络(Semantic Network)(注意不是语义网)研究人脑的语义记忆,提出用相互连接的节点和边来表示知识。节点表示对象、概念,边表示节点之间的关系。语义网络可以比较容易地让我们理解语义和语义关系。其表达形式简单直白,符合自然。然而,由于缺少标准,其比较难应用于实践。
1965 年,在斯坦福大学,美国著名计算机学家费根鲍姆带领学生开发了第一个专家系统 Dendral,这个系统可以根据化学仪器的读数自动鉴定化学成分。随着专家系统的提出和商业化发展,知识库(Knowledge Base)构建和知识表示更加得到重视。专家系统的基本想法是:专家是基于大脑中的知识来进行决策的,因此人工智能的核心应该是用计算机符号表示这些知识,并通过推理机模仿人脑对知识进行处理。依据专家系统的观点,计算机系统应该由知识库和推理机两部分组成,而不是由函数等过程性代码组成。
1969 年,因特网诞生于美国。它的前身“阿帕网”( ARPAnet)是一个军用研究系统,后来才逐渐发展成为连接大学及高等院校计算机的学术系统,现在则已发展成为一个覆盖五大洲 150 多个国家的开放型全球计算机网络系统,拥有许多服务商。
1980 年,本体论,哲学概念”本体”被引入人工智能领域用来刻画知识。
1989 年,英国科学家 Tim Berners-Lee 在欧洲高能物理研究所工作的时候,发明了万维网技术。Tim Berners-Lee 发明的万维网技术,把信息用网页(HTML)表示,用超链接 HTTP 协议把不同的网页链接起来。万维网一下子激活了信息组织的灵活性,使万维网成为了互联网上的最大应用。
1998 年,在上述技术基础上,英国科学家 Tim Berners-Lee(还是这个人)又提出语义网,希望把这个万维网技术向前推进一步。
Tim Berners-Lee 提出了最初的语义网体系结构,随着人们对语义网的深入研究,语义网的体系结构也在不断地发展演变。体系结构如下图所示。可以看出,语义网是传统人工智能与 Web 融合的结果,是符号主义核心知识表示与推理在现代 Web 中的应用,其中的 RDF/OWL 都是面向 Web 的知识表示语言。

语义网和万维网、语义网络的区别如下:
- 万维网是以文档来组织的,我们所访问的网页、文件,本质上都是一个个文档,而文档中存在大量知识,只有人可以读懂。
- 语义网当中的相关技术 RDF, schema, 和 inference languages 等目的是将万维网所有的文档数据降解到数据级别,降解到能够被计算机所理解的语义,我们就可以将当前网络上无结构或半结构化的文档转换为网络数据,变成一个巨大的数据库,从而使计算机与人更好的合作。

- 相对于最早语义网络,语义网更倾向于描述万维网中资源、数据之间的关系,语义网中提出了更多规范的标准:例如,RDF 的提出解决了语义网络的缺点 1 和缺点 2,在节点和边的取值上做了约束,制定了统一标准,为多源数据的融合提供了便利;W3C 制定的另外两个标准 RDFS/OWL,解决区分概念和对象的问题,即定义 Class 和 Object(也称作 Instance, Entity)。
2006 年,Tim Berners Lee(还是这个人)提出链接数据。由于语义网的设计模型是“自顶向下”的,大规模情况下实现起来很困难,于是乎,学者们逐渐将焦点转向数据本身,在这种情况下,Tim Berners-Lee 提出关联数据(Linked Data)的概念,鼓励大家将数据公开并遵循一定的原则(2006 年提出 4 条原则,2009 年精简为 3 条原则)将其发布在互联网中,链接数据起初是用于定义如何利用语义网技术在网上发布数据,其强调在不同的数据集间创建链接。
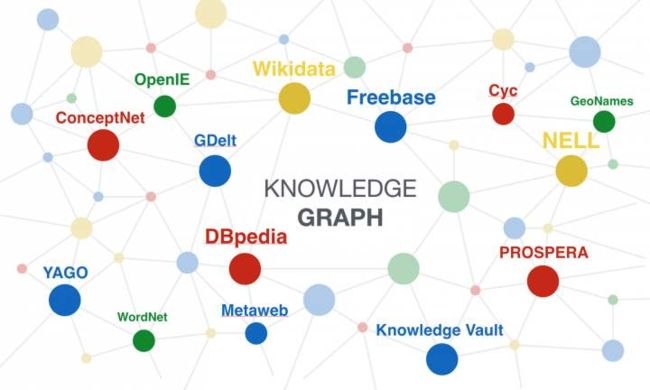
在上述背景下,大型数据集项目越来越多,包括国外的DBpedia 项目、Wikidata 项目、Freebase项目等。在中文社区类似的项目有清华大学的 XLore、复旦大学的 CN-pedia等。
2012 年,谷歌在上述技术的基础上,特别是依托收购的Freebase,进行改扩充和改进(谷歌自己的专业团队在Freebase 的基础上又设计了模式层等),最后提出了知识图谱,目的是提升搜索引擎返回的答案质量和用户查询的效率,有知识图谱作为辅助,搜索引擎能够洞察用户查询背后的语义信息,返回更为精准、结构化的信息,更大可能地满足用户的查询需求。
知识图谱和专家系统、本体、语义网、链接数据区别如下:
- 知识图谱和专家系统:知识图谱技术继承了知识本体和专家系统的精髓,成为了当代知识表示和推理的重要技术。但知识图谱与传统专家系统时代的知识工程有着显著的不同。传统专家系统时代主要依靠专家手工获取知识,构建规则,而现代知识图谱的显著特点是规模巨大,无法单一依靠人工和专家构建。
- 知识图谱和本体:知识图谱与本体的相同之处在于:二者都通过定义元数据以支持语义服务。不同之处在于: 知识图谱更灵活, 支持通过添加自定义的标签划分事物的类别。本体侧重概念模型的说明,能对知识表示进行概括性、抽象性的描述,强调的是概念以及概念之间的关系。大部分本体不包含过多的实例, 本体实例的填充通常是在本体构建完成以后进行的.。知识图谱更侧重描述实体关系, 在实体层面对本体进行大量的丰富与扩充.。可以认为, 本体是知识图谱的抽象表达, 描述知识图谱的上层模式; 知识图谱是本体的实例化, 是基于本体的知识库。
- 知识图谱和语义网:知识图谱继承了语义网的知识表示方法,比如说和RDFS和OWL具有紧密的关系,因为知识图谱可以看成是一种知识存储的数据结构,本身并不具备形式化的语义,但是可以通过RDFS 或者OWL 的规则应用于知识图谱进行推理,从而赋予知识图谱形式化语义。从某种角度说,知识图谱就是大规模语义网,也是对链接数据这个概念的进一步包装。
- 知识图谱和链接数据:链接数据技术直接促成了谷歌的知识图谱技术(Knowledge Graph)。链接数据和知识图谱最大的区别在于:1. 链接数据更强调不同 RDF 数据集(知识图谱)的相互链接。2. 知识图谱不一定要链接到外部的知识图谱(和企业内部数据通常也不会公开一个道理),更强调有一个本体层来定义实体的类型和实体之间的关系。另外,知识图谱数据质量要求比较高且容易访问,能够提供面向终端用户的信息服务(查询、问答等等)。
扫码或搜索关注我的公众号:知识图谱与机器学习
带你快速入门知识图谱
