kafka单机伪分布式搭建
kafka单机伪分布式搭建
Zookeeper的功能以及工作原理
ZooKeeper是什么? ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,是Google的Chubby一个开源的实现,它是集群的管理者,监视着集群中各个节点的状态根据节点提交的反馈进行下一步合理操作。最终,将简单易用的接口和性能高效、功能稳定的系统提供给用户。
Kafka简介
Kafka是最初由Linkedin公司开发,是一个分布式、支持分区的(partition)、多副本的(replica),基于zookeeper协调的分布式消息系统,它的最大的特性就是可以实时的处理大量数据以满足各种需求场景:比如基于hadoop的批处理系统、低延迟的实时系统、storm/Spark流式处理引擎,web/nginx日志、访问日志,消息服务等等,用scala语言编写,Linkedin于2010年贡献给了Apache基金会并成为顶级开源 项目。
一、环境基础准备jdk
java -version #查看jadk
yum -y list java* #查看yum源中的java
yum -y install java-1.8.0* #安装1.8jdk
二、定义目录结构以及伪分布式节点:
mkdir -p /opt/zookeeper #zookeeper目录里面到时存放各个zookeeper节点
mkdir -p /opt/zookeeper/server1 #定义zookeeper节点1
mkdir -p /opt/zookeeper/server2 #定义zookeeper节点2
mkdir -p /opt/zookeeper/server3 #定义zookeeper节点3
mkdir -p /opt/kafka #kafka路径
三、下载并安装zookeeper和kafka的最新版压缩包:
1、下载解压zookeeper
cd /opt/zookeeper
wget https://mirrors.aliyun.com/apache/zookeeper/zookeeper-3.4.12/zookeeper-3.4.12.tar.gz
tar zxvf zookeeper-3.4.12/zookeeper-3.4.12.tar.gz -C /opt/zookeeper/server1
tar zxvf zookeeper-3.4.12/zookeeper-3.4.12.tar.gz -C /opt/zookeeper/server2
tar zxvf zookeeper-3.4.12/zookeeper-3.4.12.tar.gz -C /opt/zookeeper/server3
2、下载解压kafka
cd /opt/kafka
wget https://mirrors.aliyun.com/apache/kafka/1.1.0/kafka_2.12-1.1.0.tgz
tar zxvf kafka_2.12-1.1.0.tgz -C /opt/kafka
##没有wget 需要安装
Yum -y install wget
四、创建zookerper各个节点的data和logs目录以及zookeeper节点标识文件的myid:
cd /opt/zookeeper/server1/zookeeper-3.4.12 #切到server1创建
mkdir -p data #Zookeeper保存数据的目录
mkdir -p logs #Zookeeper将写数据的日志文件保存在这个目录里。
cd data
vim myid #创建myid文件
1 #server1的id
:wq #保存退出

cd /opt/zookeeper/server2/zookeeper-3.4.12 #切到server2创建
mkdir -p data #Zookeeper保存数据的目录
mkdir -p logs #Zookeeper将写数据的日志文件保存在这个目录里。
cd data
vim myid #创建myid文件
2 #server2的id
:wq #保存退出
cd /opt/zookeeper/server3/zookeeper-3.4.12 ##切到server3创建
mkdir -p data #Zookeeper保存数据的目录
mkdir -p logs #Zookeeper将写数据的日志文件保存在这个目录里。
cd data
vim myid #创建myid文件
3 #server3的id
:wq #保存退出
五、修改各个节点的zookeeper的配置文件:
修改server1的配置文件:
cd /opt/zookeeper/server1/zookeeper-3.4.12/conf
cp zoo_sample.cfg zoo_sample.cfg.bak #备份默认配置文件
mv zoo_sample.cfg zoo.cfg #zookeeper启动配置文件

vim zoo.cfg
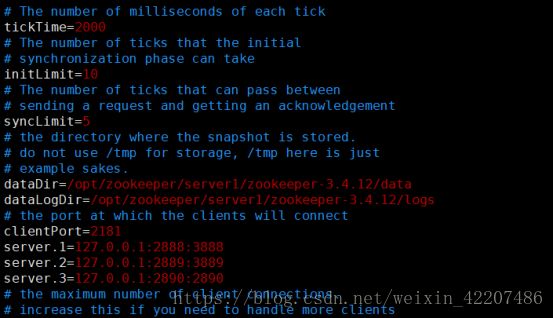
tickTime=2000 #Zookeeper 服务器之间或客户端与服务器之间维持心跳的时间间隔,也就是每个 tickTime 时间就会发送一个心跳。tickTime以毫 秒为单位。tickTime=2000
initLimit=10 #集群中的follower服务器(F)与leader服务器(L)之间初始连接时能容忍的最多心跳数(tickTime的数量)。
syncLimit=5 #集群中的follower服务器与leader服务器之间请求和应答之间能容忍的最多心跳数(tickTime的数量)。
dataDir=/opt/zookeeper/server1/zookeeper-3.4.12/data #Zookeeper保存数据的目录
dataLogDir=/opt/zookeeper/server1/zookeeper-3.4.12/logs #Zookeeper将写数据的日志文件保存在这个目录里。
clientPort=2181 #客户端连接 Zookeeper 服务器的端口,Zookeeper 会监听这个端口,接受客户端的访问请求。
server.1=127.0.0.1:2888:3888 #服务器名称与地址:集群信息(服务器编号,服务器地址,LF通信端口,选举端口)
server.2=127.0.0.1:2889:3889
server.3=127.0.0.1:2890:2890
修改server2的配置文件:
cd /opt/zookeeper/server2/zookeeper-3.4.12/conf
cp zoo_sample.cfg zoo_sample.cfg.bak #备份默认配置文件
mv zoo_sample.cfg zoo.cfg #zookeeper启动配置文件
vim zoo.cfg
tickTime=2000 #Zookeeper 服务器之间或客户端与服务器之间维持心跳的时间间隔,也就是每个 tickTime 时间就会发送一个心跳。tickTime以毫 秒为单位。tickTime=2000
initLimit=10 #集群中的follower服务器(F)与leader服务器(L)之间初始连接时能容忍的最多心跳数(tickTime的数量)。
syncLimit=5 #集群中的follower服务器与leader服务器之间请求和应答之间能容忍的最多心跳数(tickTime的数量)。
dataDir=/opt/zookeeper/server2/zookeeper-3.4.12/data #Zookeeper保存数据的目录
dataLogDir=/opt/zookeeper/server2/zookeeper-3.4.12/logs #Zookeeper将写数据的日志文件保存在这个目录里。
clientPort=21821 #客户端连接 Zookeeper 服务器的端口,Zookeeper 会监听这个端口,接受客户端的访问请求。
server.1=127.0.0.1:2888:3888 #服务器名称与地址:集群信息(服务器编号,服务器地址,LF通信端口,选举端口)
server.2=127.0.0.1:2889:3889
server.3=127.0.0.1:2890:2890
修改server3的配置文件:
cd /opt/zookeeper/server3/zookeeper-3.4.12/conf
cp zoo_sample.cfg zoo_sample.cfg.bak #备份默认配置文件
mv zoo_sample.cfg zoo.cfg #zookeeper启动配置文件
vim zoo.cfg
tickTime=2000 #Zookeeper 服务器之间或客户端与服务器之间维持心跳的时间间隔,也就是每个 tickTime 时间就会发送一个心跳。tickTime以毫 秒为单位。tickTime=2000
initLimit=10 #集群中的follower服务器(F)与leader服务器(L)之间初始连接时能容忍的最多心跳数(tickTime的数量)。
syncLimit=5 #集群中的follower服务器与leader服务器之间请求和应答之间能容忍的最多心跳数(tickTime的数量)。
dataDir=/opt/zookeeper/server3/zookeeper-3.4.12/data #Zookeeper保存数据的目录
dataLogDir=/opt/zookeeper/server3/zookeeper-3.4.12/logs #Zookeeper将写数据的日志文件保存在这个目录里。
clientPort=2181 #客户端连接 Zookeeper 服务器的端口,Zookeeper 会监听这个端口,接受客户端的访问请求。
server.1=127.0.0.1:2888:3888 #服务器名称与地址:集群信息(服务器编号,服务器地址,LF通信端口,选举端口)
server.2=127.0.0.1:2889:3889
server.3=127.0.0.1:2890:2890
六、启动三个zookeeper节点:
/opt/zookeeper/server1/zookeeper-3.4.12/bin/zkServer.sh start
/opt/zookeeper/server2/zookeeper-3.4.12/bin/zkServer.sh start
/opt/zookeeper/server3/zookeeper-3.4.12/bin/zkServer.sh start
启动后查看: /opt/zookeeper/server1/zookeeper-3.4.12/bin/zkServer.sh status ZooKeeper JMX enabled by default Using config: /opt/zookeeper/server1/zookeeper-3.4.12/bin/../conf/zoo.cfg Mode: follower ###正常启动

如果报错排查思路:
1、查看监听的端口是否被占用; (占用的话可以杀死再启动,或者在配置文件中更换端口)
2、再次启动失败时,查看/data文件夹内删除version-2和zookeeper_server.pid留下myid。(再次启动)
3、上二步执行后没有问题的话查看防火墙:
service iptables status #查看防火墙
service iptables stop #关闭防火墙
/opt/zookeeper/server1/zookeeper-3.4.12/bin/zkServer.sh start #启动zookeeper
七、kafka搭建:
1、Kafka伪分布式安装的思路跟Zookeeper的伪分布式安装思路完全一样,不过比Zookeeper稍微简单些(不需要创建myid文件),主要是针对每个Kafka服务器配置一个单独的server.properties,三个服务器分别使用server.properties,server.1.properties, server.2.properties
cd /opt/kafka/kafka_2.12-1.1.0/config #进入kafka配置目录
cp server.properties server.properties.bak #备份kafka默认配置文件
cp server.properties server-1.properties #创建kafka-1的broker
cp server.properties server-2.properties #创建kafka-2的broker

2、修改配置文件: 修改kafka的server配置文件:
cd /opt/kafka/kafka_2.12-1.1.0/config
vim server.properties #
broker.id=0 #broker的id
host.name=192.168.1.5 #本机名或者ip
port=9092 #每个id内Kakfa服务器监听的端口
log.dirs=/opt/kafka/kafka_2.12-1.1.0/logs/log-0 #日志存放路径
zookeeper.connect=192.168.1.5:2181 #zookeeper连接端口
:wq 保存退出

### 本机ip:192.168.1.5
修改kafka的server1配置文件:
vim server-1.properties
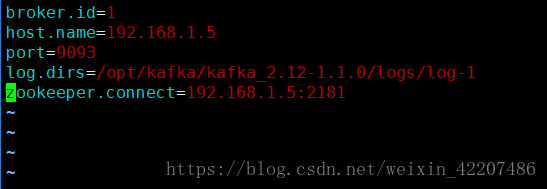
broker.id=1
host.name=192.168.1.5
port=9093
log.dirs=/opt/kafka/kafka_2.12-1.1.0/logs/log-1
zookeeper.connect=192.168.1.5:2181
:wq
修改kafka的server2配置文件:
vim server-2.properties
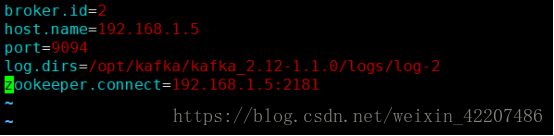
broker.id=2
host.name=192.168.1.5
port=9094
log.dirs=/opt/kafka/kafka_2.12-1.1.0/logs/log-2
zookeeper.connect=192.168.1.5:2181
:wq
八、启动启动三个broker:
/opt/kafka/kafka_2.12-1.1.0/bin/kafka-server-start.sh -daemon /opt/kafka/kafka_2.12-1.1.0/config/server.properties
/opt/kafka/kafka_2.12-1.1.0/bin/kafka-server-start.sh -daemon /opt/kafka/kafka_2.12-1.1.0/config/server-1.properties
/opt/kafka/kafka_2.12-1.1.0/bin/kafka-server-start.sh -daemon /opt/kafka/kafka_2.12-1.1.0/config/server-2.properties
九、测试kafka
1、测试创建主题
cd /opt/kafka/kafka_2.12-1.1.0/bin/
./kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic testing #发布测试主题
./kafka-topics.sh --list --zookeeper 192.168.1.5:2181 #查看是否获取主题

2、运行生产者,然后在控制台中输入几条消息发送到服务器。
./kafka-console-producer.sh --broker-list 192.168.1.5:9092 --topic testing #发送一些消息
>this is dgp
>dgp ok
./kafka-console-consumer.sh --bootstrap-server 192.168.1.5:9092 --topic testing --from-beginning #获取信息

##我这里创建的是另一个主题dgp
3、创建一个拥有3个副本的topic
./kafka-topics.sh --create --zookeeper 192.168.1.5:2181 --replication-factor 3 --partitions 1 --topic my-replicated-topic #创建
./kafka-topics.sh --describe --zookeeper 192.168.1.5:2181 --topic my-replicated-topic #查看运行“描述主题”命令
Topic:my-replicated-topic PartitionCount:1 ReplicationFactor:3 Configs:
Topic: my-replicated-topic Partition: 0 Leader: 0 Replicas: 0,1,2 Isr: 0,1,2

##leader:是负责给定分区的所有读写操作的节点。每个节点将成为分区随机选择部分的领导者。
##replicas:是复制此分区的日志的节点列表
##isr:节点列表,通过他来选取领导者。
后续##有时间更新!