keepalived 配置详解
keepalived 配置详解
- keepalived 原理及配置介绍
- VRRP 协议
- Keepalived 原理
- Keepalived 配置文件详解
- 1.global_defs 全局配置
- 2.VRRPD 配置
- vrrp_script
- vrrp_sync_group
- vrrp_instance
- 3. LVS 配置
- virtual_server
- real_server
- Real_server 中的健康检查
- 配置实例
keepalived 原理及配置介绍
什么是 Keepalived 呢,keepalived 观其名可知,保持存活,在网络里面就是保持在线了,也就是所谓的高可用或热备,用来防止单点故障(单点故障是指一旦某一点出现故障就会导致整个系统架构的不可用)的发生,Keepalived 通过请求一个 vip 来达到请求真是 IP 地址的功能,而 VIP 能够在一台机器发生故障时候,自动漂移到另外一台机器上,从来达到了高可用 HA 功能。那说到 keepalived 时不得不说的一个协议就是 VRRP 协议,可以说这个协议就是 keepalived 实现的基础,那么首先我们来看看 VRRP 协议。
VRRP 协议
网络在设计的时候必须考虑到冗余容灾,包括线路冗余,设备冗余等,防止网络存在单点故障,那在路由器或三层交换机处实现冗余就显得尤为重要,在网络里面有个协议就是来做这事的,这个协议就是 VRRP 协议,Keepalived 就是巧用 VRRP 协议来实现高可用性 (HA) 的 VRRP 协议。
Keepalived 原理
keepalived 也是模块化设计,不同模块复杂不同的功能,下面是 keepalived 的组件 core check vrrp libipfwc libipvs-2.4 libipvs-2.6
core:是 keepalived 的核心,复杂主进程的启动和维护,全局配置文件的加载解析等
check:负责 healthchecker (健康检查),包括了各种健康检查方式,以及对应的配置的解析包括LVS的配置解析
vrrp:VRRPD 子进程,VRRPD 子进程就是来实现 VRRP 协议的
libipfwc:iptables(ipchains) 库,配置 LVS 会用到
libipvs*:配置 LVS 会用到
注意,keepalived 和 LVS 完全是两码事,只不过他们各负其责相互配合而已。
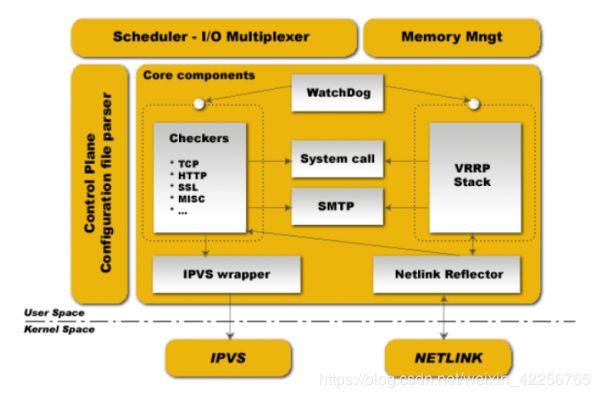
keepalived 启动后会有三个进程
父进程:内存管理,子进程管理等等
子进程:VRRP 子进程
子进程:healthchecker 子进程
有图可知,两个子进程都被系统 WatchDog 看管,两个子进程各自复杂自己的事,healthchecker 子进程复杂检查各自服务器的健康程度,例如 HTTP,LVS 等等,如果healthchecker 子进程检查到 MASTER 上服务不可用了,就会通知本机上的兄弟 VRRP 子进程,让他删除通告,并且去掉虚拟 IP,转换为 BACKUP 状态。
Keepalived 配置文件详解
keepalived 有三类配置区域,注意不是三种配置文件,是一个配置文件里面三种不同类别的配置区域,全局配置 (Global Configuration)、VRRPD 配置、LVS 配置。
1.global_defs 全局配置
{
global_defs {
notification_email {
[email protected]
[email protected]
[email protected] #邮件报警
}
notification_email_from [email protected] 指定发件人
smtp_server 192.168.200.1 #指定 smtp 服务器地址
smtp_connect_timeout 30 指定 smtp 连接超时时间
router_id LVS_DEVEL #负载均衡标识,在局域网内应该是唯一的。
vrrp_skip_check_adv_addr
vrrp_strict
vrrp_garp_interval 0
vrrp_gna_interval 0
}
说明:
-
notification_email:指定当 keepalived 出现问题时,发送邮件给哪些用户。
-
notification_emai_from:发送邮件时,邮件的来源地址。
-
smtp_server
-
smtp_helo_name
:指定在 HELO 消息中所使用的名称。默认为本地主机名。 -
smtp_connect_timeout:指定 smtp 服务器连接的超时时间。单位是秒。
-
router_id:指定标识该机器的 route_id. 如:route_id LVS_01
-
vrrp_mcast_group4 224.0.0.18:指定发送 VRRP 组播消息使用的 IPV4 组播地址。默认是224.0.0.18
-
vrrp_mcast_group6 ff02::12 指定发送 VRRP 组播消息所使用的 IPV6 组播地址。默认是ff02::12
-
default_interface eth0:设置静态地址默认绑定的端口。默认是 eth0。
-
lvs_sync_daemon
[id ] [maxlen ] [port ] [ttl ] [group ] 设置 LVS 同步服务的相关内容。可以同步 LVS 的状态信息。 -
INTERFACE:指定同步服务绑定的接口。
-
VRRP_INSTANCE:指定同步服务绑定的 VRRP 实例。
-
id
:指定同步服务所使用的 SYNCID,只有相同的 SYNCID 才会同步。范围是0-255. -
maxlen:指定数据包的最大长度。范围是 1-65507
-
port:指定同步所使用的 UDP 端口。
-
group:指定组播 IP 地址。
-
lvs_flush:在 keepalived 启动时,刷新所有已经存在的 LVS 配置。
-
vrrp_garp_master_delay 10:当转换为 MASTER 状态时,延迟多少秒发送第二组的免费 ARP。默认为 5s,0 表示不发送第二组免的免费 ARP。
-
vrrp_garp_master_repeat 1:当转换为 MASTER 状态时,在一组中一次发送的免费 ARP 数量。默认是 5.
-
vrrp_garp_lower_prio_delay 10:当 MASTER 收到更低优先级的通告时,延迟多少秒发送第二组的免费 ARP。
-
vrrp_garp_lower_prio_repeat 1:当 MASTER 收到更低优先级的通告时,在一组中一次发送的免费 ARP 数量。
-
vrrp_garp_master_refresh 60:当 keepalived 成为 MASTER 以后,刷新免费 ARP 的最小时间间隔(会再次发送免费 ARP)。默认是 0,表示不会刷新。
-
vrrp_garp_master_refresh_repeat 2: 当 keepalived 成为 MASTER 以后,每次刷新会发送多少个免费 ARP。默认是 1.
-
vrrp_garp_interval 0.001:在一个接口发送的两个免费 ARP 之间的延迟。可以精确到毫秒级。默认是 0.
-
vrrp_lower_prio_no_advert true|false:默认是 false。如果收到低优先级的通告,不发送任何通告。
-
vrrp_version 2|3:设置默认的 VRRP 版本。默认是 2.
-
vrrp_check_unicast_src:在单播模式中,开启对 VRRP 数据包的源地址做检查,源地址必须是单播邻居之一。
-
vrrp_skip_check_adv_addr:默认是不跳过检查。检查收到的 VRRP 通告中的所有地址可能会比较耗时,设置此命令的意思是,如果通告与接收的上一个通告来自相同的 master 路由器,则不执行检查(跳过检查)。
-
vrrp_strict:严格遵守 VRRP 协议。下列情况将会阻止启动 Keepalived:1. 没有 VIP 地址。2. 单播邻居。3. 在 VRRP 版本 2 中有 IPv6 地址。
-
vrrp_iptables:不添加任何 iptables 规则。默认是添加 iptables 规则的。
如果 vrrp 进程或 check 进程超时,可以用下面的 4 个选项。可以使处于 BACKUP 状态的 VRRP 实例变成 MASTER 状态,即使 MASTER 实例依然在运行。因为 MASTER 或 BACKUP 系统比较慢,不能及时处理 VRRP 数据包。 -
vrrp_priority <-20 – 19>:设置 VRRP 进程的优先级。
-
checker_priority <-20 – 19>:设置 checker 进程的优先级。
-
vrrp_no_swap:vrrp 进程不能够被交换。
-
checker_no_swap:checker 进程不能够被交换。
-
script_user [groupname]:设置运行脚本默认用户和组。如果没有指定,则默认用户为 keepalived_script (需要该用户存在),否则为 root 用户。默认 groupname 同 username。
-
enable_script_security:如果脚本路径的任一部分对于非 root 用户来说,都具有可写权限,则不会以 root 身份运行脚本。
-
nopreempt 默认是抢占模式 要是用非抢占式的就加上 nopreempt
2.VRRPD 配置
vrrp_script
作用:添加一个周期性执行的脚本。脚本的退出状态码会被调用它的所有的 VRRP Instance 记录。
注意:至少有一个 VRRP 实例调用它并且优先级不能为 0.优先级范围是 1-254.
vrrp_script {
...
}
选项说明:
-
scrip “/path/to/somewhere”:指定要执行的脚本的路径。
-
interval :指定脚本执行的间隔。单位是秒。默认为1s。
-
timeout :指定在多少秒后,脚本被认为执行失败。
-
weight <-254 — 254>:调整优先级。默认为2.
- 如果脚本执行成功(退出状态码为 0),weight 大于 0,则 priority 增加。
- 如果脚本执行失败(退出状态码为非 0),weight 小于0,则 priority 减少。
- 其他情况下,priority 不变。
-
rise :执行成功多少次才认为是成功。
-
fall :执行失败多少次才认为失败。
-
user [GROUPNAME]:运行脚本的用户和组。
-
init_fail:假设脚本初始状态是失败状态。
vrrp_sync_group
作用:将所有相关的 VRRP 实例定义在一起,作为一个 VRRP Group,如果组内的任意一个实例出现问题,都可以实现 Failov
vrrp_sync_group VG_1 {
group {
inside_network # vrrp instance name
outside_network # vrrp instance name
...
}
...
}
说明:
如果 username 和 groupname 没有指定,则以默认的 script_user 所指定的用户和组。
-
notify_master /path/to_master.sh [username [groupname]]
作用:当成为 MASTER 时,以指定的用户和组执行脚本。 -
notify_backup /path/to_backup.sh [username [groupname]]
作用:当成为 BACKUP 时,以指定的用户和组执行脚本。 -
notify_fault “/path/fault.sh VG_1” [username [groupname]]
作用:当该同步组 Fault 时,以指定的用户和组执行脚本。 -
notify /path/notify.sh [username [groupname]]
作用:在任何状态都会以指定的用户和组执行脚本。
说明:该脚本会在 notify_* 脚本后执行。notify 可以使用 3 个参数,如下:
a. 可以是 GROUP 或 INTANCE,表明后面是组还是实例.
b. 组名或实例名。
c. 转换后的目标状态。有:MASTER、BACKUP、FAULT。 -
smtp_alert:当状态发生改变时,发送邮件。
-
global_tracking:所有的 VRRP 实例共享相同的 tracking 配置。
vrrp_instance
vrrp_instance VI_1 {
state MASTER 指定该 keepalived 节点的初始状态
interface ens8 vrrp 实例绑定的接口,用于发送 VRRP 包
virtual_router_id 51 指定 VRRP 实例 ID
priority 150 指定优先级,优先级高的将成为 MASTER
nopreempt 设置为不抢占。默认是抢占的
advert_int 1 advert_int 1
authentication {
auth_type PASS 指定认证方式
auth_pass password 指定认证所使用的密码。
}
virtual_ipaddress {
192.168.1.217 dev ens8 指定 VIP 地址
}
}
命令说明:
-
state MASTER|BACKUP:指定该 keepalived 节点的初始状态。
-
interface eth0:vrrp 实例绑定的接口,用于发送 VRRP 包。
-
use_vmac [VMAC_INTERFACE]:在指定的接口产生一个子接口,如 vrrp.51,该接口的 MAC 地址为组播地址,通过该接口向外发送和接收 VRRP 包。
-
vmac_xmit_base:通过基本接口向外发送和接收 VRRP 数据包,而不是通过 VMAC 接口。
-
native_ipv6:强制 VRRP 实例使用 IPV6.(当同时配置了 IPV4 和 IPV6 的时候)
-
dont_track_primary:忽略 VRRP 接口的错误,默认是没有配置的。
track_interface {
eth0
eth1 weight <-254-254>
...
}
如果 track 的接口有任何一个出现故障,都会进入 FAULT 状态。
track_script {
weight <-254-254>
}
添加一个 track 脚本( vrrp_script 配置的脚本。)
-
mcast_src_ip :指定发送组播数据包的源 IP 地址。默认是绑定 VRRP 实例的接口的主 IP 地址。
-
unicast_src_ip :指定发送单薄数据包的源 IP 地址。默认是绑定 VRRP 实例的接口的主 IP 地址。
-
version 2|3:指定该实例所使用的 VRRP 版本。
unicast_peer {
...
}
采用单播的方式发送 VRRP 通告,指定单播邻居的 IP 地址。
- virtual_router_id 51:指定 VRRP 实例 ID,范围是 0-255.
- priority 100:指定优先级,优先级高的将成为 MASTER。
- advert_int 1:指定发送 VRRP 通告的间隔。单位是秒。
authentication {
auth_type PASS|AH:指定认证方式。PASS 简单密码认证(推荐), AH:IPSEC 认证(不推荐)。
auth_pass 1234:指定认证所使用的密码。最多 8 位。
}
virtual_ipaddress {
/ brd dev scope label 指定VIP地址。
-
nopreempt:设置为不抢占。默认是抢占的,当高优先级的机器恢复后,会抢占低优先级的机器成为 MASTER,而不抢占,则允许低优先级的机器继续成为 MASTER,即使高优先级的机器已经上线。如果要使用这个功能,则初始化状态必须为 BACKUP。
-
preempt_delay:设置抢占延迟。单位是秒,范围是 0—1000,默认是 0. 发现低优先级的 MASTER 后多少秒开始抢占。
通知脚本:
- notify_master | [username [groupname]]
- notify_backup | [username [groupname]]
- notify_fault | [username [groupname]]
- notify | [username [groupname]]
当停止 VRRP 时执行的脚本。
- notify_stop | [username [groupname]]
- smtp_alert
3. LVS 配置
virtual_server
virtual_server IP Port | virtual_server fwmark int | virtual_server group string {
delay_loop :健康检查的时间间隔。
lb_argo rr|wrr|lc|wlc|lblc|sh|dh:LVS 调度算法。
lb_kind NAT|DR|TUN:LVS 模式。
persistence_timeout 360:持久化超时时间,单位是秒。默认是6分钟。
persistence_granularity:持久化连接的颗粒度。
protocol TCP|UDP|SCTP:4 层协议。
ha_suspend:如果virtual server 的 IP 地址没有设置,则不进行后端服务器的健康检查。
virtualhost :为 HTTP_GET 和 SSL_GET 执行要检查的虚拟主机。如virtualhost www.felix.com
sorry_server :添加一个备用服务器。当所有的 RS 都故障时。
sorry_server_inhibit:将inhibit_on_failure 指令应用于 sorry_server 指令。
alpha:在 keepalived 启动时,假设所有的 RS 都是 down,以及健康检查是失败的。有助于防止 启动时的误报。默认是禁用的。
omega:在 keepalived 终止时,会执行 quorum_down 指令所定义的脚本。
quorum :默认值 1. 所有的存活的服务器的总的最小权重。
quorum_up :当 quorum 增长到满足 quorum 所定义的值时,执行该脚本。
quorum_down :当 quorum 减少到不满足 quorum 所定义的值时,执行该脚本。
}
real_server
real_server IP Port {
weight :给服务器指定权重。默认是 1.
inhibit_on_failure:当服务器健康检查失败时,将其 weight 设置为 0,而不是从 Virtual Server 中移除。
notify_up :当服务器健康检查成功时,执行的脚本。
notify_down :当服务器健康检查失败时,执行的脚本。
uthreshold :到这台服务器的最大连接数。
lthreshold :到这台服务器的最小连接数。
}
Real_server 中的健康检查
下面是常用的健康检查方式,健康检查方式一共有 HTTP_GET、SSL_GET、TCP_CHECK、SMTP_CHECK、MISC_CHECK 这些。
-
HTTP_GET | SSL_GET 方式
指定路径 url 进行配置查询
HTTP_GET | SSL_GET {
url {
path :指定要检查的 URL 的路径。如 path / or path /mrtg2
digest :摘要。计算方式:genhash -s 172.17.100.1 -p 80 -u /
index.
status_code :状态码。
}
nb_get_retry :get 尝试次数。
delay_before_retry :在尝试之前延迟多长时间。
connect_ip :连接的 IP 地址。默认是 real server 的 ip 地址。
connect_port :连接的端口。默认是 real server 的端口。
bindto :发起连接的接口的地址。
bind_port :发起连接的源端口。
connect_timeout :连接超时时间。默认是 5s。
fwmark :使用 fwmark 对所有出去的检查数据包进行标记。
warmup :指定一个随机延迟,最大为 N 秒。可防止网络阻塞。如果为 0,则关闭该功能。
}
-
TCP_CHECK 方式
通过连接 tcp 端口判断是否活跃。
TCP_CHECK {
connect_ip :连接的 IP 地址。默认是 real server 的 ip 地址。
connect_port :连接的端口。默认是 real server 的端口。
bindto :发起连接的接口的地址。
bind_port :发起连接的源端口。
connect_timeout :连接超时时间。默认是 5s。
fwmark :使用 fwmark 对所有出去的检查数据包进行标记。
warmup :指定一个随机延迟,最大为 N 秒。可防止网络阻塞。如果为 0,则关闭该功能。
retry :重试次数。默认是 1 次。
delay_before_retry :默认是 1 秒。在重试之前延迟多少秒。
}
-
SMTP_CHECK 方式
这个可以用来给邮件服务器做集群。
SMTP_CHECK {
connect_ip :连接的 IP 地址。默认是 real server 的 ip 地址。
connect_port :连接的端口。默认是 real server 的端口。 默认是 25 端口
bindto :发起连接的接口的地址。
bind_port :发起连接的源端口。
connect_timeout :连接超时时间。默认是 5s。
fwmark :使用 fwmark 对所有出去的检查数据包进行标记。
warmup :指定一个随机延迟,最大为 N 秒。可防止网络阻塞。如果为 0,则关闭该功能。
retry :重试次数。
delay_before_retry :在重试之前延迟多少秒。
helo_name :用于 SMTP HELO 请求的字符串。
}
- DNS_CHECK 方式
DNS_CHECK {
connect_ip :连接的 IP 地址。默认是 real server 的 ip 地址。
connect_port :连接的端口。默认是 real server 的端口。 默认是 25 端口
bindto :发起连接的接口的地址。
bind_port :发起连接的源端口。
connect_timeout :连接超时时间。默认是 5s。
fwmark :使用 fwmark 对所有出去的检查数据包进行标记。
warmup :指定一个随机延迟,最大为 N 秒。可防止网络阻塞。如果为 0,则关闭该功能。
retry :重试次数。默认是 3 次。
type :DNS query type。A/NS/CNAME/SOA/MX/TXT/AAAA
name :DNS 查询的域名。默认是(.)
}
-
MISC_CHECK 方式
非常精确的来调整权重,是后端每天服务器的压力都能均衡调配,这个主要是通过执行的程序或脚本返回的状态代码来动态调整 weight 值,使权重根据真实的后端压力来适当调整。
MISC_CHECK {
misc_path :外部的脚本或程序路径。
misc_timeout :脚本执行超时时间。
user USERNAME [GROUPNAME]:指定运行该脚本的用户和组。如果没有指定 GROUPNAME,则 GROUPNAME 同 USERNAME。
misc_dynamic:根据退出状态码动态调整权重。
0,健康检查成功,权重不变。
1,健康检查失败。
2-255,健康检查成功。权重设置为退出状态码减去 2.如退出状态码是 250,则权重调整为248
warmup :指定一个随机延迟,最大为 N 秒。可防止网络阻塞。如果为 0,则关闭该功能。
}
配置实例
master 主配置与 backup 配置中 state、interface、priority 不相同,其他配置可通用
! Configuration File for keepalived
#常规配置master
global_defs {
#配置接受异常短信人邮箱
notification_email {
[email protected]
[email protected]
[email protected]
}
#配置短信发送者
notification_email_from [email protected]
smtp_server 127.0.0.1
smtp_connect_timeout 30
router_id LVS_DEVEL
}
#配置执行脚本文件
vrrp_script chk_nginx {
script "/usr/local/sbin/check_ng.sh"
interval 5
}
#keepalive 主配置,主从机器除 state、interface、priority 不一致以外,其他保持一致
vrrp_instance VI_1 {
#MASTER为主方,BACKUP为从方
state MASTER
#eth0 为网卡信息,不同机器可使用不同 指令:IP a
interface eth0
#指定 VRRP 实例 ID,范围是 0-255
virtual_router_id 51
#指定优先级,优先级高的将成为 MASTER
priority 100
#指定发送 VRRP 通告的间隔。单位是秒
advert_int 1
authentication {
#指定认证方式。PASS 简单密码认证(推荐), AH:IPSEC 认证(不推荐)。
auth_type PASS
#指定认证所使用的密码。最多 8 位
auth_pass 1111
}
#指定 VIP 地址,主从必须一致
virtual_ipaddress {
192.168.1.100
}
#添加一个 track 脚本( vrrp_script 配置的脚本。)
track_script {
chk_nginx
}
}
#健康检查
virtual_server 192.168.1.100 80 {
delay_loop 3 delay_loop
lvs_sched rr LVS 的调度算法
lvs_method DR LVS 模式
protocol TCP 4层协议
real_server 192.168.1.52 80 {
weight 1 #给服务器指定权重。默认是 1
inhibit_on_failure:当服务器健康检查失败时,将其 weight 设置为0,而不是从Virtual Server中移除。
notify_up :当服务器健康检查成功时,执行的脚本。
notify_down :当服务器健康检查失败时,执行的脚本。
uthreshold :到这台服务器的最大连接数。
lthreshold :到这台服务器的最小连接数。
#检查方式,公用HTTP_GET | SSL_GET、TCP_CHECK、SMTP_CHECK、DNS_CHECK、MISC_CHECK
TCP_CHECK {
connect_port 80
connect_timeout 3
nb_get_retry 3 get尝试次数
delay_before_retry 10 在尝试之前延迟多长时间
}
}
real_server 192.168.1.53 80 {
weight 1 #给服务器指定权重。默认是1
TCP_CHECK {
connect_port 80
connect_timeout 3
nb_get_retry 3
delay_before_retry 10
}
}
}
- Check_ng.sh 脚本配置
#!/bin/bash
#时间变量,用于记录日志
d=`date --date today +%Y%m%d_%H:%M:%S`
#计算 nginx 进程数量
n=`ps -C nginx --no-heading|wc -l`
#如果进程为 0,则关闭 keepalived
if [ $n -eq "0" ];
then
#linux 系统关闭服务方式
service keepalived stop
if [ $n2 -eq "0" ]; then
echo "$d nginx down,keepalived will stop" >> /var/log/check_ng.log
#centos 关闭服务方式
systemctl stop keepalived
fi
fi
脚本加入授权
[root@localhost /]# chmod 755 /usr/local/sbin/check_ng.sh