Python基础学习之一------python基础
python基础
简单介绍一下Python语言
之前也接触过python语言,也使用python语言实现过一些操作,但是毕竟学习应该从底层开始,所以还是要重头来过,具体是根据廖雪峰老师的网站上发布的python教程开始学习的。网址:https://www.liaoxuefeng.com/
Python语言也是一门很简单的机器语言,但其代码的编写量相对较少,操作也比较简单,比如完成同一个任务,C语言要写1000行,Java只要100行,而Python可能只要20行。所以Python语言相当高级。但是代码少的代价是运行速度慢,用Python可以做日常任务,比如自动备份文件,可以做网站、网络游戏的后台等等。当然python也有不能干的,比如写操作系统,这个只能用C语言写;写手机应用,只能用swift/objective C(针对iPhone) 和Java(针对Android);写3D游戏,最好用C或C++。
数据类型和变量
安装好python后,如果要在命令提示符里面要进入python模式,只需要输入python,再按enter键即可,接下来就可以输入python命令,最基本的就是print和input了

在cmd里,如果print(a+b),①a+b可以是二进制、十进制、十六进制......等等;②可以是浮点数

③对于字符串,如果既包含单引号 ‘ 又包含双引号 “ ,用转义字符下划线 \ 标志

④也可以是布尔值,True 或者False两种如下


⑤空值:none,不能理解为0,因为0是有意义的,而None比较特殊
⑥变量:必须是大小写的英文字母,数字,和“_”组合,且不能以数字开头,
如:a=1,则变量是整数;t_007=‘T007’,变量是字符串;answer=True,变量是布尔值,python中等于符号“=”是赋值语句,同一个变量可反复赋值,而且可以是不同类型的变量。如

⑦常量;python中如定义PI=3.1415926就是一个常量

这部分学习完成,做一个例题,计算一下下列输出的结果:
# 例题1
n = 123
f = 456.789
s1 = 'Hello, world'
s2 = 'Hello, \'Adam\''
s3 = r'Hello, "Bart"'
s4 = r'''Hello,
Lisa!'''
#例题2
b = 10
a = b
print(a)
a = 20
print(b)
print(a)python对浮点数设有大小限制,但超出范围也会表示为inf
字符串和编码
(1)字符编码
ASCII编码(只有127个字符被编码到计算机里,也就是大小写英文字母、数字和一些符号):A=65,Z=90,a=91,z=122;Unicode 所有编码语言统一,避免乱码,通常2个字节表示1个字符,ASCII通常一个字节,但Unicode通常是2个字节,字符 ‘ 0 ’用ASCII码是十进制的48,注意字符‘ 0 ’和整数 0 是不同的,表示网页正是用的UTF-8编码

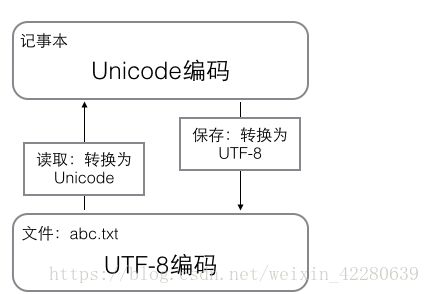
在计算机内存中,统一使用Unicode编码,当需要保存到硬盘或者需要传输的时候,就转换为UTF-8编码;用记事本编辑的时候,从文件读取的UTF-8字符被转换为Unicode字符到内存里,编辑完成后,保存的时候再把Unicode转换为UTF-8保存到文件:
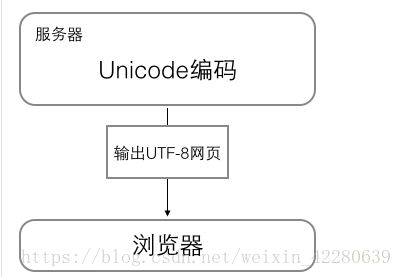
浏览网页的时候,服务器会把动态生成的Unicode内容转换为UTF-8再传输到浏览器:
(2)Python的字符串
①Python3支持多语言;②对于单个字符编码,Python提供了 ord()函数 和 chr()函数 把编码转换为对应的字符


由于Python的字符串类型是str,在内存中以Unicode表示,一个字符对应若干个字节。如果要在网络上传输,或者保存到磁盘上,就需要把str变为以字节为单位的bytes。 python中对bytes类型的数据用带b前缀的单引号或双引号来表示:

以Unicode表示的str通过encode()方法可以编码为指定的bytes,例如

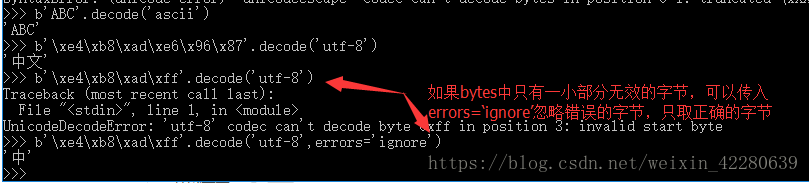
反过来如果我们从网络上或磁盘上字节流,那么读出的数据就是bytes。要把bytes转换为str,就需要用到decode()方法:

要计算str中包含多少个字符,就需要用到 len() 函数,对于bytes就是计算字节数。

python源代码也是一个文本文件,所以,源代码中如果包含中文的时候,在保存源代码时,就需要务必指定保存为utf-8编码。当python解释器读取源代码时,为了让它按utf-8编码读取,通常在文件头加入下面两行。

(3)格式化
格式化方式和C语言类似,认识一下常见的占位符
| 占位符 | 替换内容 |
|---|---|
| %d | 整数 |
| %f | 浮点数 |
| %s | 字符串 |
| %x | 十六进制整数 |
例如,如下 :注意有几个%? 后面就要跟几个变量值,顺序需要对应好

有些时候,字符串里面的%是普通字符时,就需要用到转义,用两个百分号 %% 表示 一个百分号%
![]()
(4)format
格式化字符串的方法二:format(),但是比%麻烦
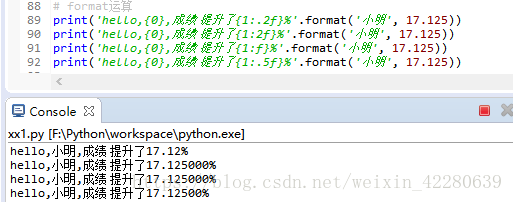
举个例子:
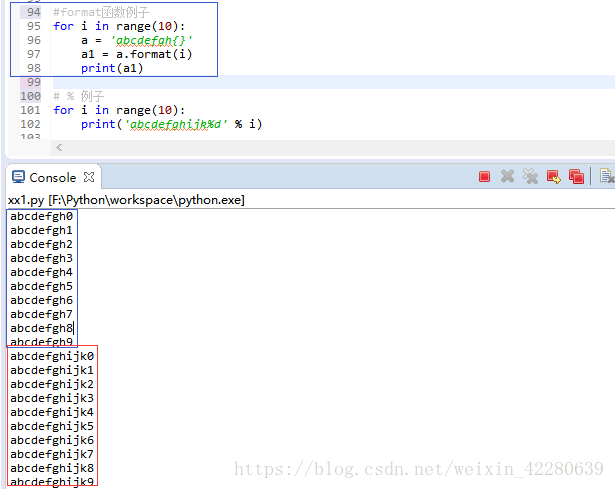
练习:小明的成绩从去年的72分提升到了今年的85分,请计算小明成绩提升的百分点,并用字符串格式化显示出'xx.x%',只保留小数点后1位:>>> print('小明的成绩提升了%0.1f %%' % ((85-72)/72*100))
使用list和tuple
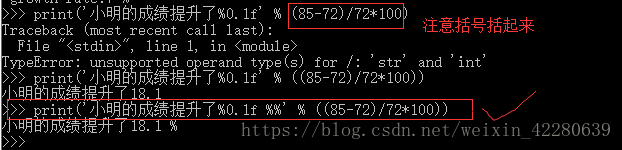
(1)list列表
python的内置的数据类型,列表。是以一对中括号[1,2,3,4,5........]括起来的数据 。list中的数据是可变的,所以他可以进行元素的增、删、改、查操作
①使用索引查询列表中的元素
②要进行元素的增加,可用到两个函数,一是使用append()函数,直接将元素追加到 list末尾,二是使用insert()函数,将元素追加到指定位置,具体操作如下:
# 往list列表中追加元素
animals.append('dragon') # 追加一个dragon元素到末尾
print('animals1[]=', animals)
animals.insert(0, 'lion') # 追加一个lion元素到末尾
print('animals2[]=', animals)
③删除list中的元素用pop()函数,删除最后一位,直接pop,删除指定位置使用pop(i),

④替换也就是修改list中的元素,直接重新赋值替换即可

list中的元素的数据类型可以不同,可以是一个元素,整形、浮点数、字符或者是布尔型都性,还可以在list中再嵌套一个list

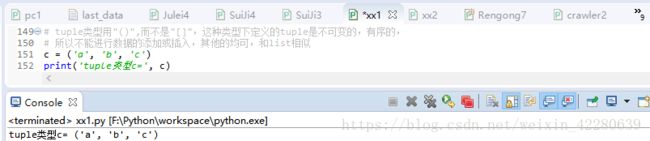
(2)tuple:元组
①tuple是一种“有序列表” ,是用一对小括号(1,2,3,4,5........)括起来的数据。和list类似,但是tuple是不可变的,一旦初始化就不能修改,所以tuple没有append以及insert这两个插入函数,也就是不能改变元组中元素的顺序。其他的和list是一样的,同样可以通过索引查询内容。
②如果定义一个空tuple,可以只写一个小括号,里面不追加元素t=()

③但定义一个只有一个元素的tuple时,有两种情况,t=(1)此时的只是定义1这个数,而不是tuple,小括号在python中既可以表示tuple也可以表示数学公式中的小括号。定义只有一个元素的tuple时,必须在后面加一个逗号来消除歧义。

④看一个 “可变的” tuple型数据

那么再试一试更改第一个元素
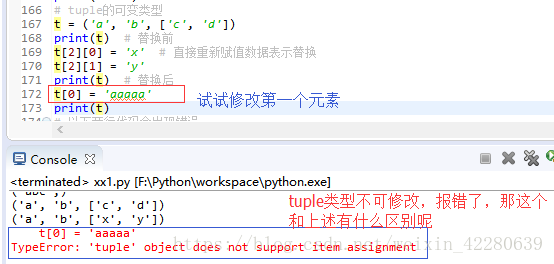
发现,现在报错了,原因是什么呢,观察一下,可以发现,上面修改的是tuple中的list中的元素,而下面我们直接修改了tuple中的元素,报错了
练习题: # 练习题
L = [['Apple', 'Google', 'Microsoft'], [
'Java', 'Python', 'Ruby', 'PHP'], ['Adam', 'Bart', 'Lisa']]
print('打印Apple:', L[0][0])
print('打印Python:', L[1][1])
print('打印Lisa:', L[2][2])条件判断
(1)条件判断
① if 语句实现条件判断

②if语句判断是True时,就执行结果,如果if判断是false,则可用else,此时就只会执行else中的内容,不执行if下的内容了

③elif 是else if 的缩写,更加细致 结构:
if <条件判断1>:
<执行1>
elif <条件判断2>:
<执行2>
elif <条件判断3>:
<执行3>
else:
<执行4>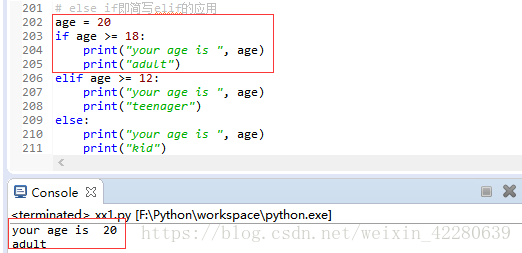
if在执行时,是从上到下执行,如果在某个判断上是True,那么执行该判断对应的语句,不会继续往下执行,不满足则跳到下一个判断语句。
④if判断语句还可以简写,如
# 判断语句还可以简写,x为非零数值、非空字符串、非空list则为True
if x:
print("True")
else:
print("false")
(2)再议input :input输出的数据类型为str
# 再议input,input输出的数据类型为str,不能直接和作为整形的数据相比较,
# 只有通过python专门的int()函数才可以成功运行
s = input("birth:")
birth = int(s)
if birth >= 2000:
print("00后")
else:
print("00前")
# 但是注意:如果此时输入abc则会报错,因为ABC是str,而int只能对应整形数据,所以会报错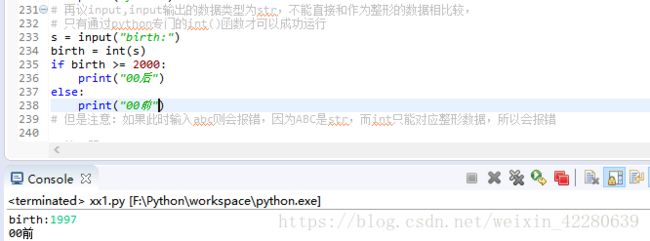
练习题1
# 练习题
# '''小明身高1.75,体重80.5kg。请根据BMI公式(体重除以身高的平方)帮小明计算他的BMI指数,并根据BMI指数:
#
# 低于18.5:过轻
# 18.5-25:正常
# 25-28:过重
# 28-32:肥胖
# 高于32:严重肥胖
#
# 用if-elif判断并打印结果:
height = input("height(m):")
weight = input("weight(kg):")
s = float(weight) / (float(height)**2)#BMI指数计算公式使用:BMI=体重(kg)/身高(m)的平方,此处平方用两个*号表示
BMI = float(s)
print("您的BMI指数为%0.01f" % BMI)
if BMI < 18.5:
print(" 过轻")
elif BMI < 25:
print(" 正常")
elif BMI < 28:
print(" 过重")
elif BMI < 32:
print(" 肥胖")
else:
print(" 严重肥胖")
循环
(1)循环,python有两种循环,一种是for.....in......,以此把list和tuple中每个元素迭代出来
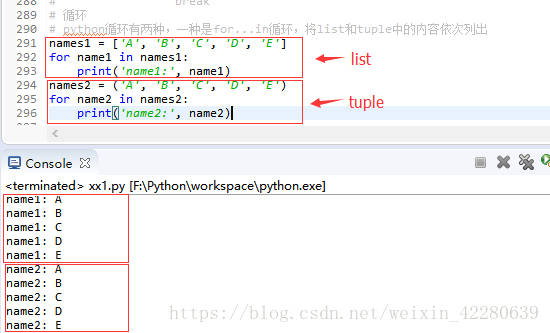
python还提供了一个range函数,可以打印出一定数量的整数序列
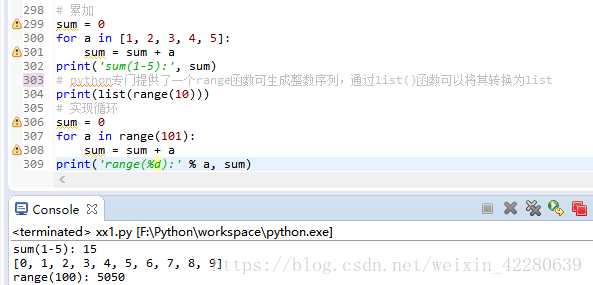
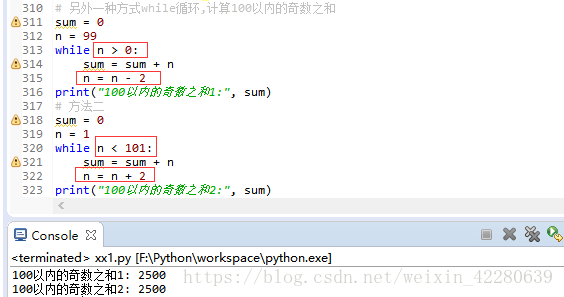
(2)第二种循环是while循环,一旦满足条件就不断进行循环,计算100以内的奇数之和
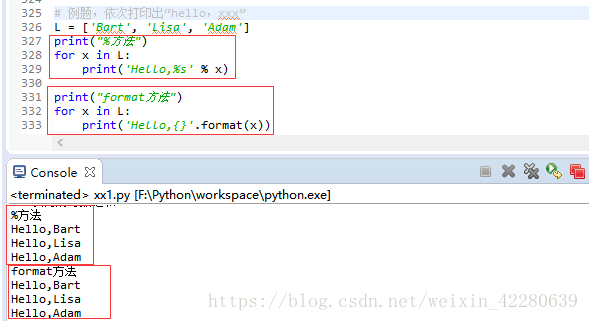
例题:# 例题,依次打印出“hello,xxx” L = ['Bart', 'Lisa', 'Adam']
(3)break
在循环中break与可以提前退出循环,例如本来要循环打印1~100,使用break就可以提前退出
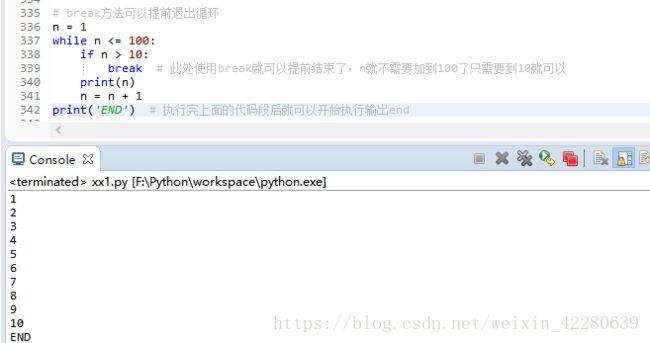
(4)continue:在循环中可以通过continue跳过当前的这次循环,直接开始下一次循环,比如,要打印1~10之间的奇数
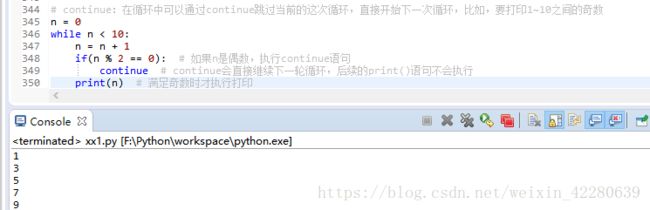
break和continue通常都必须配合if语句使用,如果有时陷入死循环想提前退出时,就采用Ctrl+C提前退出
使用dict和set
(1)dict:python中内置了字典:dict的支持,dict的全称dictionary,在其他语言中也称为map,使用键-值 (key-value)存储,查找极快,如使用名字查找对应的成绩,使用list实现时,则需要两个list,names=['A','B','C'],scores=[95,85,75],但是使用dict实现,则d = {'A': 95, 'B': 85, 'C': 75}
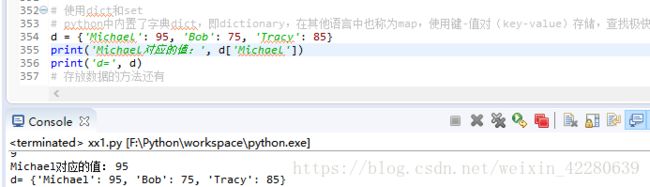
存放数据的方法直接输入即可,有时候我们进行查询时, key不存在就会报错,为了避免可以通过以下两种方法判断key是否存在, 一是通过in判断key是否存在,二是通过get判断,如果key不存在就返回none,
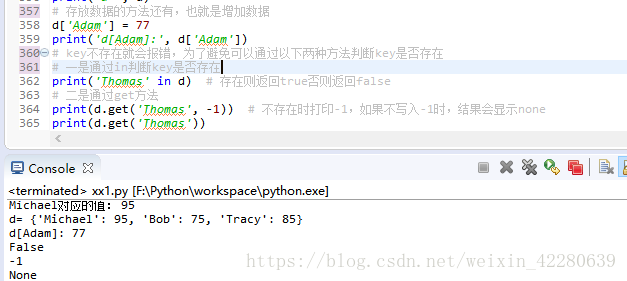
删除元素的函数与list一样,使用pop[key] 方法实现

list和dict比较,区别:dict:①查找和插入极快,不会随着key的增加而变慢,②需占用大量的内存,内存浪费多。
而list则刚好相反:①查找和插入时间随着元素增加而增加,②占用内存少。所以可以这样理解,list是用空间换取时间,注意:dict的key是不可变对象,通过key计算位置的算法称为哈希算法(Hash)。
key的对象不可变,在Python中,字符串和整数等都不可变。因此,可以作为key,但list是可变的,不能作为key。

(2)set
set和dict类似,也是一个key集合,但不存储value。由于key不能重复,所以,在set中,没有重复的key,也就是没有重复的元素。set需要提供一个list作为输入集合。如s=set([1,2,3,])出来的结果为{1,2,3},并不是表示这个set变成了一个字典,只是告诉你有这三个元素。set和dict唯一的区别在于set没有存放value。
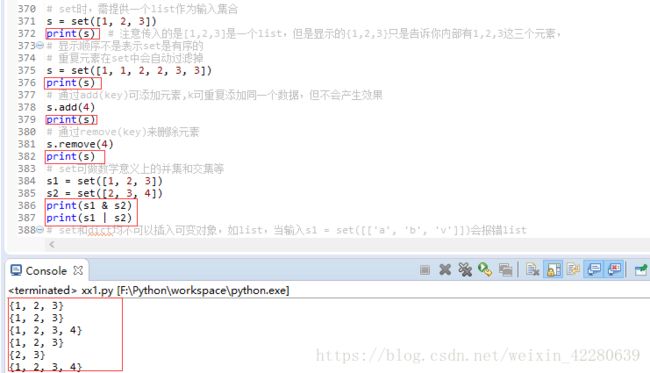
(3)再议不可变对象
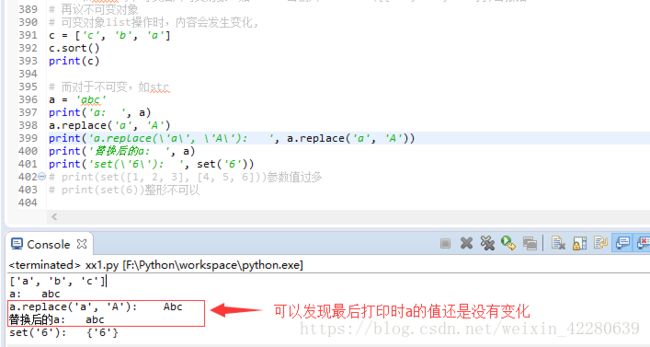
总结一下:
