Introduction to 3D Game Programming with DirectX 12 学习笔记之 --- 第四章:Direct 3D初始化
学习目标
- 对Direct 3D编程在3D硬件中扮演的角色有基本了解;
- 理解COM在Direct 3D中扮演的角色;
- 学习基本的图形学概念,比如存储2D图像、页面切换,深度缓冲、多重纹理映射和CPU与GPU如何交互;
- 学习如何使用性能计数函数读取高精度时间;
- 学习如何初始化Direct 3D;
- 熟悉本书Demo通用的应用框架中的基本结构。
1 前言
在理解Direct3D初始化步骤前,需要我们先熟悉一些图形学概念和Direct3D类型。
1.1 Direct3D 12 概述
Direct3D是一个底层图形API用来控制和对GPU编程,它可以让我们使用硬件加速来渲染3D图形;比如要向GPU提交一个清空渲染目标的命令,我们可以调用方法ID3D12CommandList::ClearRenderTargetView。
Direct3D 12添加了一些新的渲染特性,但是主要的提升在于它被重新设计用来减少CPU的开销和提高多线程支持。
1.2 COM
Component Object Model (COM)可以让DirectX成为独立的编程语言并且让它向下兼容。我们通常像使用C++类一样,以接口的形式应用COM对象。值得注意的是,我们通常使用特定的函数或者其他COM接口来获得COM接口引用的指针,我们不能使用C++中的new关键字直接创建COM对象;另外COM对接口是引用计数的,当我们使用完毕后,需要调用它的Release方法后(而不是Delete),当其引用计数等于0时,COM对象会释放其占用的内存。
为了管理COM对象的生命周期,Windows Runtime Library (WRL)提供了Microsoft::WRL::ComPtr类(#include
- Get:返回其包含的COM接口,这个主要用于在函数中传递参数;
- GetAddressOf:返回其包含的COM接口的指针指向的地址,这个主要用于在函数参数中传递COM指针;
- Reset:将ComPtr接口设置为空指针nullptr,并且减少其包含的COM接口的引用计数,相同的,你也可以给ComPtr对象赋值为nullptr;
当然,COM还有更多方法,但是对高效实用Direct3D来说,不需要。
1.3 贴图格式
一张2D贴图是数据元素的矩阵。2D贴图的其中一个用法是用来保存2D图像,其每个元素用来保存像素的颜色,当然,它的用途不仅于此,比如在法线贴图中,其每个元素用来保存3D向量;一张贴图也不仅限于是保存数据数组,它们可以包含纹理映射等级,还可以让GPU对其进行过滤和多重纹理映射等特殊操作。贴图中不能保存任意格式的数据,它只能保存在DXGI_FORMAT共用体中定义了的几种类型,其中一些格式类型如下:
- DXGI_FORMAT_R32G32B32_FLOAT:每个元素包含3个32位的浮点数组件;
- DXGI_FORMAT_R16G16B16A16_UNORM:每个元素包含4个16位组件,并映射到0到1;
- DXGI_FORMAT_R32G32_UINT:每个元素包含2个32位无符号整形组件;
- DXGI_FORMAT_R8G8B8A8_UNORM:每个元素包含4个8位组件,并映射到0到1;
- DXGI_FORMAT_R8G8B8A8_SNORM:每个元素包含4个8位组件,并映射到-1到1;
- DXGI_FORMAT_R8G8B8A8_SINT:每个元素包含4个8位整形组件,并映射到-128到127;
- DXGI_FORMAT_R8G8B8A8_UINT:每个元素包含4个8位无符号整形,并映射到0到255;
还有一些无类型格式,我们只是申请了内存,等到使用它的时候在申明它的类型,比如DXGI_FORMAT_R16G16B16A16_TYPELESS
1.4 交换链和页面切换
为了避免动画中的闪烁问题,使用多个缓冲来交换显示,只有画面在离屏缓冲中渲染完毕后,才切换到屏幕中显示;前和后缓冲形式的交换链在Direct3D中使用IDXGISwapChain接口来表示;其提供重置尺寸方法:IDXGISwapChain::ResizeBuffers和呈现方法:IDXGISwapChain::Present(交换2个缓冲前后位置)。
使用两个缓存称之为双缓冲,使用三个缓存的称之为三缓冲,大部分情况下双缓冲就够用了。
1.5 深度缓冲
深度缓存用来保存每个像素的深度信息,其值域为0到1,0代表距离是椎体最近距离,1代表最远距离,因为其余像素是一一对应的,所以它的分辨率和back buffer的分辨率是一样的;
深度缓存是一张贴图,所以它必须用特定的格式来创建:
- DXGI_FORMAT_D32_FLOAT_S8X24_UINT:使用32位浮点数深度缓存,和8位无符号整形预留给模板缓存(0~255)和24位未使用数据;
- DXGI_FORMAT_D32_FLOAT:使用32位浮点数深度缓存;
- DXGI_FORMAT_D24_UNORM_S8_UINT:使用24位无符号深度缓存,并映射到0到1,和8位无符号整形预留给模板缓存;
- DXGI_FORMAT_D16_UNORM:使用16位无符号深度缓存,并映射到0到1。
应用不需要一定有模板缓存,但是如果有的话,它经常附加到深度缓存中,比如32位格式:
DXGI_FORMAT_D24_UNORM_S8_UINT
所以深度缓存最好称之为深度/模板缓存;
1.6 资源和描述符(Descriptors)
GPU资源并不是直接绑定的,而是通过descriptor对象来引用,之所以这样做是因为GPU资源本质上是一堆普通的内存块,所以它们可以在渲染管线中不同阶段中被使用;更进一步,GPU资源可以创建成无类型的,所以GPU可能不知道资源的类型。所以就需要使用descriptors来描述资源。
(View和descriptor是一样的,老版本中使用View,DX12中部分地方也沿用View)
Descriptors拥有类型,用来定义它将如何被使用,在本书中使用到的类型有:
- CBV/SRV/UAV descriptors用来描述尝试缓存(constant buffers)、着色器资源(shader resources)和unordered access view resources;
- Sampler descriptors用来描述纹理映射资源;
- RTV descriptors用来描述渲染目标资源;
- DSV descriptors用来描述深度/模板资源;
一个descriptor heap是一个descriptors的数组,它用来保存所有特定类型的descriptors,不同类型的descriptors需要用不用descriptors heap保存,你也可以针对同一个类型的descriptors创建多个descriptors heap;同时也可以多个descriptors heap引用同一个资源。
Descriptors应该在初始化的时候创建,因为它需要做一些类型检查和验证;
1.7 多重纹理映射理论
因为显示器上的像素不是无限小,所以任意线段都不能在显示器上完美呈现出来;当无法增加显示器分辨率的时候,我们可以使用抗锯齿技术。
其中一种叫超级纹理映射技术,它使用4倍于屏幕分辨率的back buffer 和 深度缓存(depth buffer),当显示到屏幕上时,取4个像素的平均值;这种计数计算量和内存占用都太大了,Direct3D选用了一种折中的方案称为多重纹理映射:该计数也使用4倍于屏幕分辨率的back buffer 和 深度缓存(depth buffer),它并不计算每个字像素的颜色,而是每个像素只计算一遍,然后分享给每个可见和未被遮挡的子像素,如下图所示:
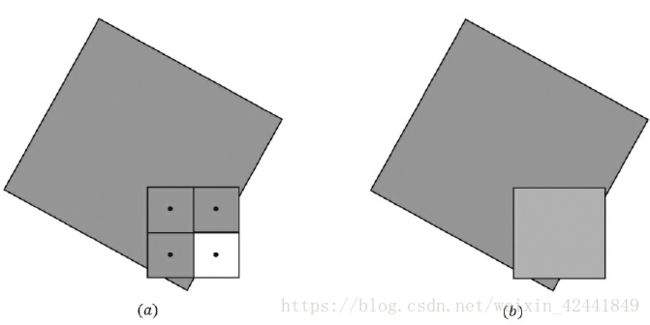
1.8 Direct3D中的多重纹理映射
在下一个部分中,我们需要填写一个结构体DXGI_SAMPLE_DESC,这个结构体有2个成员变量如下:
typedef struct DXGI_SAMPLE_DESC
{
UINT Count;
UINT Quality;
} DXGI_SAMPLE_DESC;
Count用来指定对每个像素进行多少次采样,Quality用来指定品质等级(quality level 指可以兼容不同硬件厂商?);高采样次数和品质等级代表更好的效果也代表更大的运算和内存开销;品质等级的范围只要基于纹理格式,采样次数基于每个像素。
我们可以使用函数ID3D12Device::CheckFeatureSupport检查品质等级对于当前的纹理格式,和采样次数是否可用:
typedef struct D3D12_FEATURE_DATA_MULTISAMPLE_QUALITY_LEVELS {
DXGI_FORMAT Format;
UINT SampleCount;
D3D12_MULTISAMPLE_QUALITY_LEVELS_FLAG Flags;
UINT NumQualityLevels;
} D3D12_FEATURE_DATA_MULTISAMPLE_QUALITY_LEVELS;
D3D12_FEATURE_DATA_MULTISAMPLE_QUALITY_LEVELS msQualityLevels;
msQualityLevels.Format = mBackBufferFormat;
msQualityLevels.SampleCount = 4;
msQualityLevels.Flags = D3D12_MULTISAMPLE_QUALITY_LEVELS_FLAG_NONE;
msQualityLevels.NumQualityLevels = 0;
ThrowIfFailed(md3dDevice->CheckFeatureSupport(
D3D12_FEATURE_MULTISAMPLE_QUALITY_LEVELS,
&msQualityLevels,
sizeof(msQualityLevels)));
第二个参数同时是输入和输出参数,对于输入参数,我们必须指定纹理格式,采样次数和我们需要确认的多重纹理映射支持flag进行赋值;函数在输出的时候回对quality level进行赋值。无效的纹理格式的品质等级和采样次数组合范围是0到NumQualityLevels–1。
最大采样次数定义为:
#define D3D11_MAX_MULTISAMPLE_SAMPLE_COUNT ( 32 )
采样次数设置为4或者8,对于性能和内存开销都是合理的;如果你不想使用多重纹理映射,可以把采样次数设置为1,品质等级设置为0(back buffer 和 depth buffer要设置一样的采样设置)。
1.9 特征级别(Feature Levels)
Direct3D 11中介绍了特征级别的概念,它直接对应到每个版本的Direct3D:
enum D3D_FEATURE_LEVEL
{
D3D_FEATURE_LEVEL_9_1 = 0x9100,
D3D_FEATURE_LEVEL_9_2 = 0x9200,
D3D_FEATURE_LEVEL_9_3 = 0x9300,
D3D_FEATURE_LEVEL_10_0 = 0xa000,
D3D_FEATURE_LEVEL_10_1 = 0xa100,
D3D_FEATURE_LEVEL_11_0 = 0xb000,
D3D_FEATURE_LEVEL_11_1 = 0xb100
}D3D_FEATURE_LEVEL;
特征级别定义了一系列严格的功能;比如,如果一个GPU支持11,它必须支持所有Direct 11的功能,除了少量一些功能(比如多重纹理映射还是需要被确认下,因为它可以在不同支持Direct 11的硬件之间变化)。特征级别让开发变得容易一些,因为当你知道特征级别时,你就知道了你处理的Direct3D支持的功能。
如果用户的硬件不支持当前特征级别,应用程序会返回到上一个(更老的)特征级别。
1.10 DirectX 图像基础设施(DXGI)
DXGI是一套和Direct3D一起使用的API。它的基本思想是:一些图形任务对于一些图形API是相同的。比如:为了平滑动画的交换链(swap chain)和页面切换(page flipping)在2D和3D情况是相同的,所以交换链的接口IDXGISwapChain就是DXGI API的一部分。DXGI还有其他功能,比如:全屏切换,遍历系统信息比如显示适配器(display adapters),显示器,支持的显示模式(分辨率,刷新频率等);它也定义了各种支持的表面格式(surface formats (DXGI_FORMAT))。
在这里我们简单介绍一些后面将要用到的DXGI接口的概念。一个主要的接口是IDXGIFactory,它主要用来创建IDXGISwapChain接口和遍历显示适配器。显示适配器用来执行图形功能,通常它是物理硬件上的一部分;但是系统也可以包含一个软件的显示适配器;一个系统可以拥有多个显示适配器,每个适配器可以用一个IDXGIAdapter接口来表示,我们可以使用下列代码遍历系统中所有的显示适配器:
void D3DApp::LogAdapters()
{
UINT i = 0;
IDXGIAdapter* adapter = nullptr;
std::vector adapterList;
while(mdxgiFactory->EnumAdapters(i, &adapter) != DXGI_ERROR_NOT_FOUND)
{
DXGI_ADAPTER_DESC desc;
adapter->GetDesc(&desc);
std::wstring text = L"***Adapter: ";
text += desc.Description;
text += L"\n";
OutputDebugString(text.c_str());
adapterList.push_back(adapter);
++i;
}
for(size_t i = 0; i < adapterList.size(); ++i)
{
LogAdapterOutputs(adapterList[i]);
ReleaseCom(adapterList[i]);
}
}
一个系统可以由多个显示器,一个显示器输出可以使用IDXGIOutput接口表示。每个适配器关联一个显示输出列表;比如,一个系统包含2个显卡和3个显示器,其中一个显卡与2个显示器挂钩,另一个显卡和一个显示器挂钩,那么在这种情况下,一个适配器关联2个输出,另一个适配器关联一个输出。
这些信息我们可以使用下列代码遍历出来:
void D3DApp::LogAdapterOutputs(IDXGIAdapter* adapter)
{
UINT i = 0;
IDXGIOutput* output = nullptr;
while(adapter->EnumOutputs(i, &output) != DXGI_ERROR_NOT_FOUND)
{
DXGI_OUTPUT_DESC desc;
output->GetDesc(&desc);
std::wstring text = L"***Output: ";
text += desc.DeviceName;
text += L"\n";
OutputDebugString(text.c_str());
LogOutputDisplayModes(output, DXGI_FORMAT_B8G8R8A8_UNORM);
ReleaseCom(output);
++i;
}
}
每个显示器又可以支持一些列显示模式,一个显示模式用DXGI_MODE_DESC结构体表示:
typedef struct DXGI_MODE_DESC
{
UINT Width; // Resolution width
UINT Height; // Resolution height
DXGI_RATIONAL RefreshRate;
DXGI_FORMAT Format; // Display format
DXGI_MODE_SCANLINE_ORDER ScanlineOrdering; //Progressive vs. interlaced
DXGI_MODE_SCALING Scaling; // How the image is stretched
// over the monitor.
} DXGI_MODE_DESC;
typedef struct DXGI_RATIONAL
{
UINT Numerator;
UINT Denominator;
} DXGI_RATIONAL;
typedef enum DXGI_MODE_SCANLINE_ORDER
{
DXGI_MODE_SCANLINE_ORDER_UNSPECIFIED = 0,
DXGI_MODE_SCANLINE_ORDER_PROGRESSIVE = 1,
DXGI_MODE_SCANLINE_ORDER_UPPER_FIELD_FIRST = 2,
DXGI_MODE_SCANLINE_ORDER_LOWER_FIELD_FIRST = 3
} DXGI_MODE_SCANLINE_ORDER;
typedef enum DXGI_MODE_SCALING
{
DXGI_MODE_SCALING_UNSPECIFIED = 0,
DXGI_MODE_SCALING_CENTERED = 1,
DXGI_MODE_SCALING_STRETCHED = 2
} DXGI_MODE_SCALING;
我们可以使用下列代码把所有显示模式都打印出来:
void D3DApp::LogOutputDisplayModes(IDXGIOutput* output, DXGI_FORMAT format)
{
UINT count = 0;
UINT flags = 0;
// Call with nullptr to get list count.
output->GetDisplayModeList(format, flags, &count, nullptr);
std::vector modeList(count);
output->GetDisplayModeList(format, flags, &count, &modeList[0]);
for(auto& x : modeList)
{
UINT n = x.RefreshRate.Numerator;
UINT d = x.RefreshRate.Denominator;
std::wstring text = L"Width = " + std::to_wstring(x.Width) + L" " +
L"Height = " + std::to_wstring(x.Height) + L" " +
L"Refresh = " + std::to_wstring(n) + L"/" + std::to_wstring(d) + L"\n";
::OutputDebugString(text.c_str());
}
}
当进入全屏模式的时候,遍历显示模式就变得很重要,为了优化全屏模式下的性能,准确匹配显示模式就很重要,比如刷新频率。
如果要更多的了解DXGI,我们建议阅读下面的文档:
DXGI Overview: http://msdn.microsoft.com/enus/library/windows/desktop/bb205075(v=vs.85).aspx
DirectX Graphics Infrastructure: http://msdn.microsoft.com/enus/brary/windows/desktop/ee417025(v=vs.85).aspx
DXGI 1.4 Improvements: https://msdn.microsoft.com/enus/library/windows/desktop/mt427784(v=vs.85).aspx
1.11 检查特征等级支持
我们已经使用ID3D12Device::CheckFeatureSupport函数来检查设备对多重纹理映射的支持,我们也可以用它来检查对其他特征的支持,它的参数如下:
HRESULT ID3D12Device::CheckFeatureSupport(
D3D12_FEATURE Feature,
void *pFeatureSupportData,
UINT FeatureSupportDataSize);
- Feature:是D3D12_FEATURE枚举类型,用来定义我们要检查哪种类型:
D3D12_FEATURE_D3D12_OPTIONS:检查各种Direct 12特征的支持;
D3D12_FEATURE_ARCHITECTURE:检查对硬件结构特征的支持;
D3D12_FEATURE_FEATURE_LEVELS:检查对特征等级的支持;
D3D12_FEATURE_FORMAT_SUPPORT:检查特征对纹理类型的支持;
D3D12_FEATURE_MULTISAMPLE_QUALITY_LEVELS:检查多重纹理映射的支持; - pFeatureSupportData指向特征支持数据的数据结构的指针,数据的类型基于指定的Feature的值改变:
a、如果指定D3D12_FEATURE_D3D12_OPTIONS,那么传递D3D12_FEATURE_DATA_D3D12_OPTIONS的实例;
b、如果指定D3D12_FEATURE_ARCHITECTURE,那么传递D3D12_FEATURE_DATA_ARCHITECTURE的实例;
c、如果指定D3D12_FEATURE_FEATURE_LEVELS,那么传递D3D12_FEATURE_DATA_FEATURE_LEVELS的实例;
d、如果指定D3D12_FEATURE_FORMAT_SUPPORT,那么传递D3D12_FEATURE_DATA_FORMAT_SUPPORT的实例;
e、如果指定D3D12_FEATURE_MULTISAMPLE_QUALITY_LEVELS,那么传递D3D12_FEATURE_DATA_MULTISAMPLE_QUALITY_LEVELS的实例; - FeatureSupportDataSize是传递到参数pFeatureSupportData的数据大小。
ID3D12Device::CheckFeatureSupport可以检查大量各种特征,很多本书没有使用到的和高级特征,可以通过SDK文档来查看细节,在这里我们使用特征等级检查来举例:
typedef struct D3D12_FEATURE_DATA_FEATURE_LEVELS
{
UINT NumFeatureLevels;
const D3D_FEATURE_LEVEL *pFeatureLevelsRequested;
D3D_FEATURE_LEVEL MaxSupportedFeatureLevel;
} D3D12_FEATURE_DATA_FEATURE_LEVELS;
D3D_FEATURE_LEVEL featureLevels[3] =
{
D3D_FEATURE_LEVEL_11_0, // First check D3D 11 support
D3D_FEATURE_LEVEL_10_0, // Next, check D3D 10 support
D3D_FEATURE_LEVEL_9_3 // Finally, check D3D 9.3 support
};
D3D12_FEATURE_DATA_FEATURE_LEVELS featureLevelsInfo;
featureLevelsInfo.NumFeatureLevels = 3;
featureLevelsInfo.pFeatureLevelsRequested = featureLevels;
md3dDevice->CheckFeatureSupport(
D3D12_FEATURE_FEATURE_LEVELS,
&featureLevelsInfo,
sizeof(featureLevelsInfo));
值得注意的是,第二个参数既是输入也是输出参数;输入的是将要检查的特征等级数组(pFeatureLevelsRequested),然后输出硬件所支持的最大等级(MaxSupportedFeatureLevel)。
1.12 Residency
在Direct 12中,应用程序使用资源residency来管理资源的申请和释放GPU内存,也可以使用下面函数来手动管理residency:
HRESULT ID3D12Device::MakeResident(
UINT NumObjects,
ID3D12Pageable *const *ppObjects);
HRESULT ID3D12Device::Evict(
UINT NumObjects,
ID3D12Pageable *const *ppObjects);
第二个参数是类型ID3D12Pageable的资源数组,第一个参数是数组中元素的个数;在本书中我们不使用residency,如果想要继续了解,可以参考文档:https://msdn.microsoft.com/enus/library/windows/desktop/mt186622(v=vs.85).aspx
2 CPU/GPU的交互
在图形程序中,有2个处理器在同时运行:CPU和GPU,为了优化性能,我们的目标是让他们尽可能长时间同时在处理,并且减少同步。如果它们需要同步,就代表着其中一个处理器正在空闲,在等到另一个处理器处理完毕,这种情况就破坏了它们的并行运算,所以要尽可能减少同步操作。
2.1 命令队列和命令列表(The Command Queue and Command Lists)
GPU有一个命令队列,CPU调用Direct 3D API使用命令列表项GPU提交命令:
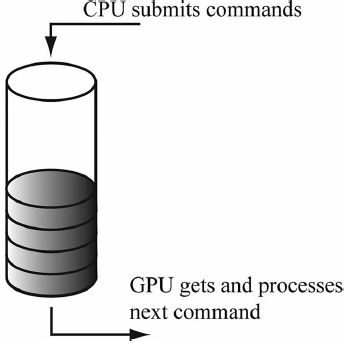
如果命令队列为空,表示GPU会被闲置;如果命令队列太满,CPU将要等待GPU处理完成;上述两种情况都不利于高性能的程序,比如游戏。所以我们的目标是让他们同时都高效的运行。
在Direct 12中,使用ID3D12CommandQueue接口来表示命令队列,我们填写D3D12_COMMAND_QUEUE_DESC数据结构,然后调用函数ID3D12Device::CreateCommandQueue来创建它。
Microsoft::WRL::ComPtr mCommandQueue;
D3D12_COMMAND_QUEUE_DESC queueDesc = {};
queueDesc.Type = D3D12_COMMAND_LIST_TYPE_DIRECT;
queueDesc.Flags = D3D12_COMMAND_QUEUE_FLAG_NONE;
ThrowIfFailed(md3dDevice->CreateCommandQueue( &queueDesc, IID_PPV_ARGS(&mCommandQueue)));
其中IID_PPV_ARGS宏定义如下:
#define IID_PPV_ARGS(ppType) __uuidof(** (ppType)), IID_PPV_ARGS_Helper(ppType)
__uuidof(**(ppType))等同于COM接口的ID,比如在上面代码中就是ID3D12CommandQueue;IID_PPV_ARGS_Helper函数本质上是将ppType类型转换为void* *;许多Direct 12的API的调用需要COM接口ID作为参数,所以本书中将大量使用这个宏。
这个接口中的一个重要的方法是:ExecuteCommandLists,它用来将命令从命令列表提交到命令队列:
void ID3D12CommandQueue::ExecuteCommandLists(
// Number of commands lists in the array
UINT Count,
// Pointer to the first element in an array of command lists
ID3D12CommandList *const *ppCommandLists);
命令列表将会从第一个元素开始执行。
命令列表使用ID3D12GraphicsCommandList接口来表示(继承自ID3D12CommandList接口),ID3D12GraphicsCommandList接口有很多方法可以添加命令到命令列表,比如下面代码添加了一个设置窗口的命令,清空渲染目标的命令和一个发布draw call的命令:
// mCommandList pointer to ID3D12CommandList
mCommandList->RSSetViewports(1, &mScreenViewport);
mCommandList->ClearRenderTargetView(mBackBufferView, Colors::LightSteelBlue, 0, nullptr);
mCommandList->DrawIndexedInstanced(36, 1, 0, 0, 0);
从这些添加命令的方法名字看,感觉命令会立刻被执行,但实际上只是将他们添加到了命令列表。当我们添加完毕后,需要调用方法ID3D12GraphicsCommandList::Close来表示命令已经添加完毕:
// Done recording commands.
mCommandList->Close();
命令列表需要关闭后才能调用ID3D12CommandQueue::ExecuteCommandLists被传递到命令队列。
和命令列表相关联的是一个内存支持类:ID3D12CommandAllocator。当一个命令被记录到命令列表时,它实际上是被储存到一个关联的命令分配器(command allocator),当列表被传递到命令队列是,命令队列将从命令分配器中引用这些命令。一个命令分配器通过ID3D12Device创建:
HRESULT ID3D12Device::CreateCommandAllocator(
D3D12_COMMAND_LIST_TYPE type,
REFIID riid,
void **ppCommandAllocator);
- type:可以被关联到这个分配器的命令列表类型,本书中将要使用到的2个类型:
a、D3D12_COMMAND_LIST_TYPE_DIRECT:保存一个将直接被GPU执行的命令列表;
b、D3D12_COMMAND_LIST_TYPE_BUNDLE:将命令列表表示为一个包(bundle),这个是Direct 12提供的一个优化方法,将一组命令记录到一个bundle里,这组里的命令会被预处理用以优化。所以bundle需要在初始化时记录。只有当性能分析出在创建零碎的命令列表时占用了大量时间,再考虑使用该类型。一般情况下Direct 12的API已经非常高效,所以不需要使用该类型为默认,本书中也不会使用该类型,如果有需求,可以查看官方文档。 - riid:ID3D12CommandAllocator接口的COM ID;
- ppCommandAllocator:创建好的分配器的指针;
命令列表也是从ID3D12Device创建:
HRESULT ID3D12Device::CreateCommandList(
UINT nodeMask,
D3D12_COMMAND_LIST_TYPE type,
ID3D12CommandAllocator *pCommandAllocator,
ID3D12PipelineState *pInitialState,
REFIID riid,
void **ppCommandList);
- nodeMask:设置0表示单GPU,否则表示指定该命令列表关联的GPU,本书中使用单GPU;
- type:命令列表的类型:D3D12_COMMAND_LIST_TYPE_DIRECT和D3D12_COMMAND_LIST_TYPE_BUNDLE;
- pCommandAllocator:关联的分配器,分配器和命令列表的类型要一致;
- pInitialState:指定该命令列表最初的流水线状态,对于bundles可以指定为null,我们在第六章详细讨论ID3D12PipelineState;
- riid:ID3D12CommandList接口的COM ID;
- ppCommandList:输出常见的命令列表的指针;
你可以使用ID3D12Device::GetNodeCount来获取当前系统中的GPU适配器的个数。
你可以创建多个命令列表关联同一个分配器,但是不能同时为它们记录命令;所以当为一个命令列表记录命令时,其它关联同一个分配器的命令列表必须关闭;所以所有从关联了相同分配器添加的命令是连续的。
(一个命令列表创建时的默认状态是open,所以如果同时创建2个命令列表关联到同一个分配器,会报错:D3D12 ERROR: ID3D12CommandList:: {Create,Reset}CommandList: The command allocator is currently in-use by another command list.)
当我们调用ID3D12CommandQueue::ExecuteCommandList©后,继续调用ID3D12CommandList::Reset之后重新使用C内部的内存来记录新的命令是安全的,它的参数和ID3D12Device::CreateCommandList中的参数是一致的:
HRESULT ID3D12CommandList::Reset(
ID3D12CommandAllocator *pAllocator,
ID3D12PipelineState *pInitialState);
重置命令列表不会影响到命令队列中的命令,因为关联的命令分配器中还保存这命令队列中引用的命令。
当完成当前帧的渲染时,我们可以调用ID3D12CommandAllocator::Reset方法在下一帧中重新使用命令分配器中的内存:
HRESULT ID3D12CommandAllocator::Reset(void);
这个思路类似于std::vector::clear,重置vector的大小为0,但是保持容量和之前相同;因为命令队列引用命令分配器中的命令,所以在确保GPU已经完成渲染前,不能重置命令分配器,在下一章中讨论这个方法。
2.2 CPU和GPU的同步
因为有2个处理器并行运算,就会出现一些同步问题:
假设有一个资源R保存了一个即将绘制的几何体的位置数据,CPU设置了一个位置给R,并将命令添加到了命令队列,然后CPU又设置了一个新位置给R,并将命令添加到了命令队列,如果这个时候第一个命令还没有被GPU执行,那么就会出现错误:

其中一个解决方案是,强制CPU等待GPU处理完所有在一个特殊标记(fence point)前的命令,我们管这个方案叫冲洗命令队列(flushing the command queue)。我们可以使用一个由ID3D12Fence接口代表的fence来同步CPU和GPU。一个fence可以用下面的方法创建:
HRESULT ID3D12Device::CreateFence(
UINT64 InitialValue,
D3D12_FENCE_FLAGS Flags,
REFIID riid,
void **ppFence);
// Example
ThrowIfFailed(md3dDevice->CreateFence(
0,
D3D12_FENCE_FLAG_NONE,
IID_PPV_ARGS(&mFence)));
一个fence对象包含一个UINT64的值用来实时表示fence点,开始的时候设置为0,然后在需要的时候标记一个fence点,然后让它增长;下面的代码表示了如何使用它:
UINT64 mCurrentFence = 0;
void D3DApp::FlushCommandQueue()
{
// Advance the fence value to mark commands up to this fence point.
mCurrentFence++;
// Add an instruction to the command queue to set a new fence point.
// Because we are on the GPU timeline, the new fence point won’t be
// set until the GPU finishes processing all the commands prior to
// this Signal().
ThrowIfFailed(mCommandQueue->Signal(mFence.Get(), mCurrentFence));
// Wait until the GPU has completed commands up to this fence point.
if(mFence->GetCompletedValue() < mCurrentFence)
{
HANDLE eventHandle = CreateEventEx(nullptr, false, false, EVENT_ALL_ACCESS);
// Fire event when GPU hits current fence.
ThrowIfFailed(mFence->SetEventOnCompletion(mCurrentFence, eventHandle));
// Wait until the GPU hits current fence event is fired.
WaitForSingleObject(eventHandle, INFINITE);
CloseHandle(eventHandle);
}
}

这并不是一个很好的方案,因为CPU需要等待GPU执行完毕,但是在第七章前,它给我们提供了一个很简单的思路可以同步CPU和GPU;我们可以在任何需要的地方进行同步(不需要太频繁,每帧一次就可以),比如初始化的时候、我们想重置分配器的时候。
2.3 资源状态转变
为了保证共同的渲染效果,有时GPU需要先在资源R中写入数据,然后在下一步中读取R的数据;这样在使用R资源的时候就会有一定的风险,比如读取R数据的时候,可能还没有写入完成或者还没有开始写;为了解决这个问题Direct3D给资源关联了一个状态来避免这种情况。
一个资源转换是使用在命令列表中的一个transition resource barriers数组来表示,它代表了你想转换资源的数据;在代码中,一个资源barrier用D3D12_RESOURCE_BARRIER_DESC结构来表示:
struct CD3DX12_RESOURCE_BARRIER : public D3D12_RESOURCE_BARRIER
{
// [...] convenience methods
static inline CD3DX12_RESOURCE_BARRIER Transition(
_In_ ID3D12Resource* pResource,
D3D12_RESOURCE_STATES stateBefore,
D3D12_RESOURCE_STATES stateAfter,
UINT subresource = D3D12_RESOURCE_BARRIER_ALL_SUBRESOURCES,
D3D12_RESOURCE_BARRIER_FLAGS flags = D3D12_RESOURCE_BARRIER_FLAG_NONE)
{
CD3DX12_RESOURCE_BARRIER result;
ZeroMemory(&result, sizeof(result));
D3D12_RESOURCE_BARRIER &barrier = result;
result.Type = D3D12_RESOURCE_BARRIER_TYPE_TRANSITION;
result.Flags = flags;
barrier.Transition.pResource = pResource;
barrier.Transition.StateBefore = stateBefore;
barrier.Transition.StateAfter = stateAfter;
barrier.Transition.Subresource = subresource;
return result;
}
// [...] more convenience methods
};
CD3DX12_RESOURCE_BARRIER继承自D3D12_RESOURCE_BARRIER_DESC并且添加了一些方法,大多数Direct 12结构都有扩展结构,它们定义在d3dx12.h。这个文件不是SDK的核心,但是可以从微软官方上下载,为了方便,本书将它们赋值到了Common目录下。
其中一个使用的例子如下:
mCommandList->ResourceBarrier(1,
&CD3DX12_RESOURCE_BARRIER::Transition(
CurrentBackBuffer(),
D3D12_RESOURCE_STATE_PRESENT,
D3D12_RESOURCE_STATE_RENDER_TARGET));
上述代码将back buffer 从用来显示到屏幕的状态修改为渲染目标。
2.4 多线程与命令
Direct 12被设计用来提高多线程的性能,命令列表就是其中一种;当我们要渲染一个很大的场景的时候,使用4个线程和4个命令列表分别计算25%的资源可以很大的提高性能。
但是有几点需要注意:
- 命令列表不是线程自由的,多个线程不能共用一个命令列表;
- 命令分配器不是线程自由的,多个线程不能供用一个命令分配器;
- 命令队列是线程自由的,多个线程可以共用一个命令队列;
- 出于性能考虑,在初始化的时候需要指明最大同时记录的命令列表的数量。
为了简化考虑,本书中不使用多线程,但是希望读完本书后参考SDK中的Multithreading12例子来学习多线程。
3 Direct3D 的初始化
下面展示初始化我们Demo中使用的Direct3D框架,初始化的流程可以概括如下:
- 使用D3D12CreateDevice函数创建ID3D12Device;
- 创建ID3D12Fence对象和query descriptor大小;
- 检查4重纹理映射支持;
- 创建命令队列,命令列表分配器和主命令列表;
- 描述和创建交换链;
- 创建应用需要的descriptor heaps;
- 重置back buffer大小,并创建back buffer的render target view;
- 创建depth/stencil buffer和与它关联的depth/stencil view;
- 设置viewport和scissor;
3.1 创建设备
Direct 12的设备代表显示适配器,通常情况下它是硬件的一部分(比如显卡,有时也可以是软件),它用来检查特征支持和创建其它接口比如资源、views和命令列表;可以使用下面的方法来创建:
HRESULT WINAPI D3D12CreateDevice(
IUnknown* pAdapter,
D3D_FEATURE_LEVEL MinimumFeatureLevel,
REFIID riid, // Expected: ID3D12Device
void** ppDevice );
- pAdapter:表示我们创建的设备表示的显示适配器,设置为null表示使用主显示适配器,本书中通常使用主显示适配器;
- MinimumFeatureLevel:表示我们的应用需要支持的最小特征等级,如果显示适配器不支持最小等级,设备会创建失败;在我们的框架中使用D3D_FEATURE_LEVEL_11_0;
- riid:ID3D12Device接口COM ID;
- ppDevice:返回创建好的设备的指针;
下面是调用上面函数的例子:
#if defined(DEBUG) || defined(_DEBUG)
// Enable the D3D12 debug layer.
{
ComPtr debugController;
ThrowIfFailed(D3D12GetDebugInterface(IID_PPV_ARGS(&debugController)));
debugController->EnableDebugLayer();
}
#endif
ThrowIfFailed(CreateDXGIFactory1(IID_PPV_ARGS(&mdxgiFactory)));
// Try to create hardware device.
HRESULT hardwareResult = D3D12CreateDevice(
nullptr, // default adapter
D3D_FEATURE_LEVEL_11_0,
IID_PPV_ARGS(&md3dDevice));
// Fallback to WARP device.
if(FAILED(hardwareResult))
{
ComPtr pWarpAdapter;
ThrowIfFailed(mdxgiFactory->EnumWarpAdapter(IID_PPV_ARGS(&pWarpAdapter)));
ThrowIfFailed(D3D12CreateDevice(
pWarpAdapter.Get(),
D3D_FEATURE_LEVEL_11_0,
IID_PPV_ARGS(&md3dDevice)));
}
3.2 创建Fence和Descriptor Sizes
当创建完设备后,我们可以创建Fence来同步GPU和CPU,另外Descriptor的大小会根据不同GPU来改变,所以我们需要确认Descriptor的大小:
ThrowIfFailed(md3dDevice->CreateFence(
0, D3D12_FENCE_FLAG_NONE,
IID_PPV_ARGS(&mFence)));
mRtvDescriptorSize = md3dDevice->GetDescriptorHandleIncrementSize(
D3D12_DESCRIPTOR_HEAP_TYPE_RTV);
mDsvDescriptorSize = md3dDevice->GetDescriptorHandleIncrementSize(
D3D12_DESCRIPTOR_HEAP_TYPE_DSV);
mCbvSrvDescriptorSize = md3dDevice->GetDescriptorHandleIncrementSize(
D3D12_DESCRIPTOR_HEAP_TYPE_CBV_SRV_UAV);
3.3 检查4重纹理映射支持
本书中我们检查4重纹理映射,选择它一方面是因为它能带来不错的效果并且不占用太多的性能;另一方面是所有支持Direct 11的设备都可以支持所有格式的4重纹理映射,所以我们不需要确认它的支持情况;但是我们还是需要确认质量等级,代码如下:
D3D12_FEATURE_DATA_MULTISAMPLE_QUALITY_LEVELS msQualityLevels;
msQualityLevels.Format = mBackBufferFormat;
msQualityLevels.SampleCount = 4;
msQualityLevels.Flags = D3D12_MULTISAMPLE_QUALITY_LEVELS_FLAG_NONE;
msQualityLevels.NumQualityLevels = 0;
ThrowIfFailed(md3dDevice->CheckFeatureSupport(
D3D12_FEATURE_MULTISAMPLE_QUALITY_LEVELS,
&msQualityLevels,
sizeof(msQualityLevels)));
m4xMsaaQuality = msQualityLevels.NumQualityLevels;
assert(m4xMsaaQuality > 0 && "Unexpected MSAA quality level.");
3.4 创建命令队列和命令列表
示例代码如下:
ComPtr mCommandQueue;
ComPtr mDirectCmdListAlloc;
ComPtr mCommandList;
void D3DApp::CreateCommandObjects()
{
D3D12_COMMAND_QUEUE_DESC queueDesc = {};
queueDesc.Type = D3D12_COMMAND_LIST_TYPE_DIRECT;
queueDesc.Flags = D3D12_COMMAND_QUEUE_FLAG_NONE;
ThrowIfFailed(md3dDevice->CreateCommandQueue(
&queueDesc, IID_PPV_ARGS(&mCommandQueue)));
ThrowIfFailed(md3dDevice->CreateCommandAllocator(
D3D12_COMMAND_LIST_TYPE_DIRECT,
IID_PPV_ARGS(mDirectCmdListAlloc.GetAddressOf())));
ThrowIfFailed(md3dDevice->CreateCommandList(
0,
D3D12_COMMAND_LIST_TYPE_DIRECT,
mDirectCmdListAlloc.Get(), // Associated command allocator
nullptr, // Initial PipelineStateObject
IID_PPV_ARGS(mCommandList.GetAddressOf())));
// Start off in a closed state. This is because the first time we
// refer to the command list we will Reset it, and it needs to be
// closed before calling Reset.
mCommandList->Close();
}
3.5 描述和创建交换链
首先需要填写一个DXGI_SWAP_CHAIN_DESC结构的实例,它用来描述交换链的特征,它的定义如下:
typedef struct DXGI_SWAP_CHAIN_DESC
{
DXGI_MODE_DESC BufferDesc;
DXGI_SAMPLE_DESC SampleDesc;
DXGI_USAGE BufferUsage;
UINT BufferCount;
HWND OutputWindow;
BOOL Windowed;
DXGI_SWAP_EFFECT SwapEffect;
UINT Flags;
} DXGI_SWAP_CHAIN_DESC;
另外一个结构DXGI_MODE_DESC的定义如下:
typedef struct DXGI_MODE_DESC
{
UINT Width; // Buffer resolution width
UINT Height; // Buffer resolution height
DXGI_RATIONAL RefreshRate;
DXGI_FORMAT Format; // Buffer display format
DXGI_MODE_SCANLINE_ORDER ScanlineOrdering; //Progressive vs. interlaced
DXGI_MODE_SCALING Scaling; // How the image is stretched over the monitor.
} DXGI_MODE_DESC;
下面介绍一些重要的参数:
- BufferDesc:这个结构体描述了我们需要创建的back buffer;
- SampleDesc:多重纹理映射的值和质量等级;
- BufferUsage:指定DXGI_USAGE_RENDER_TARGET_OUTPUT;
- BufferCount:在交换链中使用的buffer数量;
- OutputWindow:我们要输出的窗口的句柄;
- Windowed:是否为窗口模式;
- SwapEffect:指定DXGI_SWAP_EFFECT_FLIP_DISCARD;
- Flags:如果指定为DXGI_SWAP_CHAIN_FLAG_ALLOW_MODE_SWITCH,那么切换到全屏模式后,应用会选择与当前最匹配的显示模式,否则会保留当前桌面模式;
当我们描述完交换链后,我们可以使用IDXGIFactory::CreateSwapChain函数来创建它:
HRESULT IDXGIFactory::CreateSwapChain(
IUnknown *pDevice, // Pointer to ID3D12CommandQueue.
DXGI_SWAP_CHAIN_DESC *pDesc, // Pointer to swap chain description.
IDXGISwapChain **ppSwapChain);// Returns created swap chain interface.
下面的代码展示了在我们的Demo框架中如何创建交换链;该函数可以多次调用,它在创建新的交换链的时候会先销毁之前创建的,所以我们可以使用不同的设置重新创建交换链,也代表我们可以在运行时重新设置多重纹理映射。
DXGI_FORMAT mBackBufferFormat = DXGI_FORMAT_R8G8B8A8_UNORM;
void D3DApp::CreateSwapChain()
{
// Release the previous swapchain we will be recreating.
mSwapChain.Reset();
DXGI_SWAP_CHAIN_DESC sd;
sd.BufferDesc.Width = mClientWidth;
sd.BufferDesc.Height = mClientHeight;
sd.BufferDesc.RefreshRate.Numerator = 60;
sd.BufferDesc.RefreshRate.Denominator = 1;
sd.BufferDesc.Format = mBackBufferFormat;
sd.BufferDesc.ScanlineOrdering = DXGI_MODE_SCANLINE_ORDER_UNSPECIFIED;
sd.BufferDesc.Scaling = DXGI_MODE_SCALING_UNSPECIFIED;
sd.SampleDesc.Count = m4xMsaaState ? 4 : 1;
sd.SampleDesc.Quality = m4xMsaaState ? (m4xMsaaQuality - 1) : 0;
sd.BufferUsage = DXGI_USAGE_RENDER_TARGET_OUTPUT;
sd.BufferCount = SwapChainBufferCount;
sd.OutputWindow = mhMainWnd;
sd.Windowed = true;
sd.SwapEffect = DXGI_SWAP_EFFECT_FLIP_DISCARD;
sd.Flags = DXGI_SWAP_CHAIN_FLAG_ALLOW_MODE_SWITCH;
// Note: Swap chain uses queue to perform flush.
ThrowIfFailed(mdxgiFactory->CreateSwapChain(
mCommandQueue.Get(),
&sd,
mSwapChain.GetAddressOf()));
}
3.6创建Descriptor Heaps
我们需要创建一个descriptor heaps来保存descriptors/views;descriptor heap使用ID3D12DescriptorHeap接口来表示,使用ID3D12Device::CreateDescriptorHeap函数来创建;在本章的简单程序中,我们需要SwapChainBufferCount需要个数个RTV(render target views)来描述buffer;和一个DSV(depth/stencil view):
ComPtr mRtvHeap;
ComPtr mDsvHeap;
void D3DApp::CreateRtvAndDsvDescriptorHeaps()
{
D3D12_DESCRIPTOR_HEAP_DESC rtvHeapDesc;
rtvHeapDesc.NumDescriptors = SwapChainBufferCount;
rtvHeapDesc.Type = D3D12_DESCRIPTOR_HEAP_TYPE_RTV;
rtvHeapDesc.Flags = D3D12_DESCRIPTOR_HEAP_FLAG_NONE;
rtvHeapDesc.NodeMask = 0;
ThrowIfFailed(md3dDevice->CreateDescriptorHeap(
&rtvHeapDesc,
IID_PPV_ARGS(mRtvHeap.GetAddressOf())));
D3D12_DESCRIPTOR_HEAP_DESC dsvHeapDesc;
dsvHeapDesc.NumDescriptors = 1;
dsvHeapDesc.Type = D3D12_DESCRIPTOR_HEAP_TYPE_DSV;
dsvHeapDesc.Flags = D3D12_DESCRIPTOR_HEAP_FLAG_NONE;
dsvHeapDesc.NodeMask = 0;
ThrowIfFailed(md3dDevice->CreateDescriptorHeap(
&dsvHeapDesc,
IID_PPV_ARGS(mDsvHeap.GetAddressOf())));
}
在我们的框架中,我们定义:
static const int SwapChainBufferCount = 2;
int mCurrBackBuffer = 0;
并且我们需要跟踪当前的back buffer索引mCurrBackBuffer;我们的应用程序通过句柄来引用descriptors,可以通过ID3D12DescriptorHeap::GetCPUDescriptorHandleForHeapStar函数来获取堆中的第一个句柄:
D3D12_CPU_DESCRIPTOR_HANDLE CurrentBackBufferView()const
{
// CD3DX12 constructor to offset to the RTV of the current back buffer.
return CD3DX12_CPU_DESCRIPTOR_HANDLE(
mRtvHeap->GetCPUDescriptorHandleForHeapStart(),// handle start
mCurrBackBuffer, // index to offset
mRtvDescriptorSize); // byte size of descriptor
}
D3D12_CPU_DESCRIPTOR_HANDLE DepthStencilView()const
{
return mDsvHeap->GetCPUDescriptorHandleForHeapStart();
}
现在我们知道获取descriptor大小的目的了,我们需要根据当前back buffer索引偏移到我们需要的descriptor。
3.7 创建Render Target View
如果我们想绑定back buffer到输出合并阶段(D3D可以渲染到它上),我们需要为back buffer创建一个Render Target View,第一步是获取在交换链中的back buffer:
HRESULT IDXGISwapChain::GetBuffer(
UINT Buffer,
REFIID riid,
void **ppSurface);
- Buffer:指定我们想要获取的back buffer的索引;
- riid:ID3D12Resource接口的COM ID;
- ppSurface:返回获取的ID3D12Resource对象指针。
调用IDXGISwapChain::GetBuffer会增加COM的引用计数,所以使用完毕后需要释放它;
为了创建Render Target View,我们使用ID3D12Device::CreateRenderTargetView函数:
void ID3D12Device::CreateRenderTargetView(
ID3D12Resource *pResource,
const D3D12_RENDER_TARGET_VIEW_DESC *pDesc,
D3D12_CPU_DESCRIPTOR_HANDLE DestDescriptor);
- pResource:指明将要使用的pResource;
- pDesc:一个D3D12_RENDER_TARGET_VIEW_DESC类型的指针,它描述了数据的类型;如果resource创建的时候不是typeless,则这里可以设置为Null,那么会和resource的类型保持一致;
- DestDescriptor:返回包含创建的Render Target View的句柄。
根据调用上面两个函数,我们可以为交换链中的每个back buffer创建RTV:
ComPtr mSwapChainBuffer[SwapChainBufferCount];
CD3DX12_CPU_DESCRIPTOR_HANDLE rtvHeapHandle(mRtvHeap->GetCPUDescriptorHandleForHeapStart());
for (UINT i = 0; i < SwapChainBufferCount; i++)
{
// Get the ith buffer in the swap chain.
ThrowIfFailed(mSwapChain->GetBuffer(i, IID_PPV_ARGS(&mSwapChainBuffer[i])));
// Create an RTV to it.
md3dDevice->CreateRenderTargetView(
mSwapChainBuffer[i].Get(), nullptr,
rtvHeapHandle);
// Next entry in heap.
rtvHeapHandle.Offset(1, mRtvDescriptorSize);
}
3.8 创建Depth/Stencil Buffer 和 View
一个纹理是GPU的一种资源,所以我们填充D3D12_RESOURCE_DESC结构来描述纹理资源,然后调用ID3D12Device::CreateCommittedResource函数来创建,D3D12_RESOURCE_DESC结构定义如下:
typedef struct D3D12_RESOURCE_DESC
{
D3D12_RESOURCE_DIMENSION Dimension;
UINT64 Alignment;
UINT64 Width;
UINT Height;
UINT16 DepthOrArraySize;
UINT16 MipLevels;
DXGI_FORMAT Format;
DXGI_SAMPLE_DESC SampleDesc;
D3D12_TEXTURE_LAYOUT Layout;
D3D12_RESOURCE_MISC_FLAG MiscFlags;
} D3D12_RESOURCE_DESC;
- dimension:资源的维数,其枚举如下:
enum D3D12_RESOURCE_DIMENSION
{
D3D12_RESOURCE_DIMENSION_UNKNOWN = 0,
D3D12_RESOURCE_DIMENSION_BUFFER = 1,
D3D12_RESOURCE_DIMENSION_TEXTURE1D = 2,
D3D12_RESOURCE_DIMENSION_TEXTURE2D = 3,
D3D12_RESOURCE_DIMENSION_TEXTURE3D = 4
} D3D12_RESOURCE_DIMENSION;
- Width:纹理的宽度(对于buffer,它代表位数);
- Height:纹理的高度;
- DepthOrArraySize:纹理元素的深度,或者纹理矩阵的大小;
- MipLevels:纹理映射的等级;
- Format:一个DXGI_FORMAT枚举类型,用来指明格式;
- SampleDesc:多重纹理映射和质量等级;
- Layout:一个D3D12_TEXTURE_LAYOUT枚举类型,用来指明纹理布局,目前我们可以直接设置为D3D12_TEXTURE_LAYOUT_UNKNOWN;
- MiscFlags:对于depth/stencil buffer设置为D3D12_RESOURCE_MISC_DEPTH_STENCIL。
使用ID3D12Device::CreateCommittedResource方法根据我们指明的参数来创建和提交资源到对应的堆中 :
HRESULT ID3D12Device::CreateCommittedResource(
const D3D12_HEAP_PROPERTIES *pHeapProperties,
D3D12_HEAP_MISC_FLAG HeapMiscFlags,
const D3D12_RESOURCE_DESC *pResourceDesc,
D3D12_RESOURCE_USAGE InitialResourceState,
const D3D12_CLEAR_VALUE *pOptimizedClearValue,
REFIID riidResource,
void **ppvResource);
typedef struct D3D12_HEAP_PROPERTIES {
D3D12_HEAP_TYPE Type;
D3D12_CPU_PAGE_PROPERTIES CPUPageProperties;
D3D12_MEMORY_POOL MemoryPoolPreference;
UINT CreationNodeMask;
UINT VisibleNodeMask;
} D3D12_HEAP_PROPERTIES;
- pHeapProperties:我们要提交资源的堆的属性,很多属性都是高级应用,当前我们只考虑D3D12_HEAP_TYPE,它的值可以是枚举D3D12_HEAP_PROPERTIES中的一种
a、D3D12_HEAP_TYPE_DEFAULT:默认堆,只能被GPU访问,CPU不能访问,所以depth/stencil buffer应该放在这里;
b、D3D12_HEAP_TYPE_UPLOAD:需要从CPU上传资源到GPU的堆;
c、D3D12_HEAP_TYPE_READBACK:需要被CPU读取资源的堆;
d、D3D12_HEAP_TYPE_CUSTOM:高级应用的情况,查看MSDN文档; - HeapMiscFlags:对堆进一步的描述,这里我们直接设置为D3D12_HEAP_MISC_NONE;
- pResourceDesc:D3D12_RESOURCE_DESC实例的指针,描述我们想创建的资源;
- InitialResourceState:设置资源的初始化状态;对于depth/stencil buffer,初始化状态设置为D3D12_RESOURCE_USAGE_INITIAL,后续转化成D3D12_RESOURCE_USAGE_DEPTH,这样它在渲染管线中就可以被绑定为depth/stencil buffer;
- pOptimizedClearValue:D3D12_CLEAR_VALUE对象的指针用来描述清空资源的优化值;清空调用如果匹配到一个优化过的清空值可能会更高效,当然也可以直接设置为Null:
struct D3D12_CLEAR_VALUE
{
DXGI_FORMAT Format;
union
{
FLOAT Color[ 4 ];
D3D12_DEPTH_STENCIL_VALUE DepthStencil;
};
} D3D12_CLEAR_VALUE;
- riidResource:ID3D12Resource接口的COM ID:
- ppvResource:返回创建的ID3D12Resource的指针;
出于优化考虑,资源应该放在默认堆中,除非你真的需要upload或者read堆的特性;
在使用depth/stencil buffer前,需要创建一个关联的depth/stencil view来绑定到渲染管线,这个的做法和render target view类似:
// Create the depth/stencil buffer and view.
D3D12_RESOURCE_DESC depthStencilDesc;
depthStencilDesc.Dimension = D3D12_RESOURCE_DIMENSION_TEXTURE2D;
depthStencilDesc.Alignment = 0;
depthStencilDesc.Width = mClientWidth;
depthStencilDesc.Height = mClientHeight;
depthStencilDesc.DepthOrArraySize = 1;
depthStencilDesc.MipLevels = 1;
depthStencilDesc.Format = mDepthStencilFormat;
depthStencilDesc.SampleDesc.Count = m4xMsaaState ? 4 : 1;
depthStencilDesc.SampleDesc.Quality = m4xMsaaState ? (m4xMsaaQuality - 1) : 0;
depthStencilDesc.Layout = D3D12_TEXTURE_LAYOUT_UNKNOWN;
depthStencilDesc.Flags = D3D12_RESOURCE_FLAG_ALLOW_DEPTH_STENCIL;
D3D12_CLEAR_VALUE optClear;
optClear.Format = mDepthStencilFormat;
optClear.DepthStencil.Depth = 1.0f;
optClear.DepthStencil.Stencil = 0;
ThrowIfFailed(md3dDevice->CreateCommittedResource(
&CD3DX12_HEAP_PROPERTIES(D3D12_HEAP_TYPE_DEFAULT),
D3D12_HEAP_FLAG_NONE,
&depthStencilDesc,
D3D12_RESOURCE_STATE_COMMON,
&optClear,
IID_PPV_ARGS(mDepthStencilBuffer.GetAddressOf())));
// Create descriptor to mip level 0 of entire resource using the
// format of the resource.
md3dDevice->CreateDepthStencilView(
mDepthStencilBuffer.Get(),
nullptr,
DepthStencilView());
// Transition the resource from its initial state to be used as a depth buffer.
mCommandList->ResourceBarrier(
1,
&CD3DX12_RESOURCE_BARRIER::Transition(
mDepthStencilBuffer.Get(),
D3D12_RESOURCE_STATE_COMMON,
D3D12_RESOURCE_STATE_DEPTH_WRITE));
我们使用了CD3DX12_HEAP_PROPERTIES helper constructor来创建对属性结构:
explicit CD3DX12_HEAP_PROPERTIES(
D3D12_HEAP_TYPE type,
UINT creationNodeMask = 1,
UINT nodeMask = 1 )
{
Type = type;
CPUPageProperty =
D3D12_CPU_PAGE_PROPERTY_UNKNOWN;
MemoryPoolPreference =
D3D12_MEMORY_POOL_UNKNOWN;
CreationNodeMask = creationNodeMask;
VisibleNodeMask = nodeMask;
}
CreateDepthStencilView的第二个参数是D3D12_DEPTH_STENCIL_VIEW_DESC的指针,它描述了资源中的数据类型,如果资源创建的时候有类型,那么这个参数可以为null。
3.9 设置Viewport
正常情况下,我们都是画满整个屏幕,但是有些特殊情况下只需要画在一个小的矩形里:

这个back buffer的子矩形我们称之为viewport,它可以用下面的结构体描述:
typedef struct D3D12_VIEWPORT {
FLOAT TopLeftX;
FLOAT TopLeftY;
FLOAT Width;
FLOAT Height;
FLOAT MinDepth;
FLOAT MaxDepth;
} D3D12_VIEWPORT;
前四个参数用来定义矩形的位置,在Direct 3D中,深度值为0到1,后两个参数用来转化深度值范围MinDepth到MaxDepth;设置深度值可以达到一些特殊效果,比如设置MinDepth=0,MaxDepth=0,那么所有像素都会渲染都最前面;一般情况下就设置为0到1。
当填充好D3D12_VIEWPORT结构后,我们使用ID3D12CommandList::RSSetViewports函数来设置VIEWPORT:
D3D12_VIEWPORT vp;
vp.TopLeftX = 0.0f;
vp.TopLeftY = 0.0f;
vp.Width = static_cast(mClientWidth);
vp.Height = static_cast(mClientHeight);
vp.MinDepth = 0.0f;
vp.MaxDepth = 1.0f;
mCommandList->RSSetViewports(1, &vp);
第一个参数是需要绑定的viewports的数字(应用于多个viewports的特殊效果);
你不能指定多个viewports到同一个render target,多个viewports应用于多个render target的高级效果;
每当命令列表被重置时,viewport也要被重置。
3.10 设置裁剪框(scissor rectangle)
关联在back buffer裁剪框以外的像素会被裁切,这个可以用来做优化操作;一个裁剪框可以由D3D12_RECT结构来定义:
typedef struct tagRECT
{
LONG left;
LONG top;
LONG right;
LONG bottom;
} RECT;
我们使用ID3D12CommandList::RSSetScissorRects方法来设置裁剪框;下面的代码只保留左上方的像素:
mScissorRect = { 0, 0, mClientWidth/2, mClientHeight/2 };
mCommandList->RSSetScissorRects(1, &mScissorRect);
和RSSetViewports类似,第一个参数是需要绑定的裁剪框的数字(应用于多个viewports的特殊效果);
你不能指定多个裁剪框到同一个render target,多个裁剪框应用于多个render target的高级效果;
每当命令列表被重置时,裁剪框也要被重置。
4 时间和动画
为了保证动画正确,我们需要一个高精度的计时器。
4.1 The Performance Timer
出于对精确度的考虑,我们使用The Performance Timer,使用Win32函数来查询The Performance Timer,需要#include
The performance timer使用Counts来测量时间,我们使用下面的函数来获取Counts:
__int64 currTime;
QueryPerformanceCounter((LARGE_INTEGER*)&currTime);
通过下面的方法来获取频率(每秒的Counts数):
__int64 countsPerSec;
QueryPerformanceFrequency((LARGE_INTEGER*)&countsPerSec);
那么每秒的Counts就是:mSecondsPerCount = 1.0 / (double)countsPerSec
所以时间就是:valueInSecs = valueInCounts * mSecondsPerCount
我们使用两次QueryPerformanceCounter的值计算时间差值:
__int64 A = 0;
QueryPerformanceCounter((LARGE_INTEGER*)&A);
/* Do work */
__int64 B = 0;
QueryPerformanceCounter((LARGE_INTEGER*)&B);
MSDN提示QueryPerformanceCounter在多线程下,不管任何处理器调用都会获得不同结果的BUG(BIOS或者HAL),你可以使用SetThreadAffinityMask函数,那么主线程将不会切换到其它线程。
4.2 游戏计时器类
下面两节我们将实现GameTimer类:
class GameTimer
{
public:
GameTimer();
float GameTime()const; // in seconds
float DeltaTime()const; // in seconds
void Start(); // Call when unpaused.
void Stop(); // Call when paused.
void Tick(); // Call every frame.
private:
double mSecondsPerCount;
double mDeltaTime;
__int64 mBaseTime;
__int64 mPausedTime;
__int64 mStopTime;
__int64 mPrevTime;
__int64 mCurrTime;
bool mStopped;
};
构造函数中确认了counter的频率:
GameTimer::GameTimer()
: mSecondsPerCount(0.0), mDeltaTime(-1.0),
mBaseTime(0),
mPausedTime(0), mPrevTime(0), mCurrTime(0),
mStopped(false)
{
__int64 countsPerSec;
QueryPerformanceFrequency((LARGE_INTEGER*)&countsPerSec);
mSecondsPerCount = 1.0 / (double)countsPerSec;
}
4.3 每帧消耗的时间
使用每帧之间的时间差值来计算消耗的时间:
void GameTimer::Tick()
{
if( mStopped )
{
mDeltaTime = 0.0;
return;
}
// Get the time this frame.
__int64 currTime;
QueryPerformanceCounter((LARGE_INTEGER*)&currTime);
mCurrTime = currTime;
// Time difference between this frame and the previous.
mDeltaTime = (mCurrTime - mPrevTime)*mSecondsPerCount;
// Prepare for next frame.
mPrevTime = mCurrTime;
// Force nonnegative. The DXSDK’s CDXUTTimer mentions that if the
// processor goes into a power save mode or we get shuffled to
// another processor, then mDeltaTime can be negative.
if(mDeltaTime < 0.0)
{
mDeltaTime = 0.0;
}
}
float GameTimer::DeltaTime()const
{
return (float)mDeltaTime;
}
Tick函数每帧都会调用:
int D3DApp::Run()
{
MSG msg = {0};
mTimer.Reset();
while(msg.message != WM_QUIT)
{
// If there are Window messages then process them.
if(PeekMessage( &msg, 0, 0, 0, PM_REMOVE ))
{
TranslateMessage( &msg );
DispatchMessage( &msg );
}
// Otherwise, do animation/game stuff.
else
{
mTimer.Tick();
if( !mAppPaused )
{
CalculateFrameStats();
Update(mTimer);
Draw(mTimer);
}
else
{
Sleep(100);
}
}
}
return (int)msg.wParam;
}
重置函数Reset的实现如下:
void GameTimer::Reset()
{
__int64 currTime;
QueryPerformanceCounter((LARGE_INTEGER*)&currTime);
mBaseTime = currTime;
mPrevTime = currTime;
mStopTime = 0;
mStopped = false;
}
4.4 总时间
详见Demo中的代码
5 Demo应用框架
详见代码工程,可以从本书官网下载代码,也可以下载我整理添加注释后的代码:
https://github.com/jiabaodan/Direct12BookReadingNotes
6 Direct 3D 应用的调试
许多Direct3D函数会返回HRESULT错误代码,所以我们使用下面的抛出异常来检查代码:
class DxException
{
public:
DxException() = default;
DxException(HRESULT hr, const std::wstring&
functionName,
const std::wstring& filename, int
lineNumber);
std::wstring ToString()const;
HRESULT ErrorCode = S_OK;
std::wstring FunctionName;
std::wstring Filename;
int LineNumber = -1;
};
#ifndef ThrowIfFailed
#define ThrowIfFailed(x) \
{ \
HRESULT hr__ = (x); \
std::wstring wfn = AnsiToWString(__FILE__); \
if(FAILED(hr__)) { throw DxException(hr__, L#x,
wfn, __LINE__); } \
} #
endif
ThrowIfFailed必须是一个宏并且不是函数,另外__FILE__和__LINE__表示异常出现的文件和行数,L#x可以将参数转化为Unicode字符串,这样我们就可以用message box来显示异常:
ThrowIfFailed(md3dDevice->CreateCommittedResource(
&CD3D12_HEAP_PROPERTIES(D3D12_HEAP_TYPE_DEFAULT),
D3D12_HEAP_MISC_NONE,
&depthStencilDesc,
D3D12_RESOURCE_USAGE_INITIAL,
IID_PPV_ARGS(&mDepthStencilBuffer)));
我们整个应用都在这个try/catch中:
try
{
InitDirect3DApp theApp(hInstance);
if(!theApp.Initialize())
return 0;
return theApp.Run();
}
catch(DxException& e)
{
MessageBox(nullptr, e.ToString().c_str(), L"HR Failed", MB_OK);
return 0;
}

7 总结
- Direct 3D是程序员和图形硬件之间的中介;
- Component Object Model (COM)可以是DirectX拥有基于语言开发和向下兼容;程序员不需要了解COM的原理和细节,只需要知道如何获取和释放COM接口就可以了;
- 纹理是一个数据的数组,它需要一个DXGI_FORMAT枚举来描述数据格式,它不仅可以包含图像数据,也可以包含其他数据,比如深度值;GPU可以在它上做特殊操作,比如:过滤和多重纹理映射;
- 为了避免动画冲突,使用交换链对多个back buffer进行交替渲染和显示;
- 深度缓存是用来某点在场景中最接近相机的值,利用这个技术,我们不同担心场景中物体的排序;
- 资源不能直接绑定到渲染管线,它需要绑定到descriptors;
- ID3D12Device可以类似于显卡硬件的软件控制器;
- GPU有命令队列,CPU通过命令列表向GPU提交命令;
- CPU和GPU是并行运算的2个处理器,它们有时需要进行同步处理;
- The performance counter是一个高精度计时器,我们使用它通过时间差来计算时间;
- 通过每帧消耗的时间来计算游戏当前的FPS;