Yarn资源调度系统
一、课前准备
1. 三个节点的hadoop集群
二、课堂主题
1. yarn架构、核心组件
2. yarn应用提交过程
3. yarn的调度策略
4. yarn的优化
三、课堂目标
1. 数据yarn资源的任务调度原理
2. 熟练对yarn集群进行维护
3. 了解如何使用YARN的可扩展性、效率和灵活性来增加集群性能
四、知识要点
1. yarn介绍

Apache Hadoop YARN是apache Software Foundation Hadoop的子项目,为分离Hadoop2.0资源管理和
计算组件而引入。YARN的诞生源于HDFS的数据需要更多的交互模式,不单单是MapReduce模式。Hadoop2.0
的YARN架构提供了更多的处理框架,不再强迫使用MapReduce框架。

当企业的数据在HDFS中是最可用的,有多钟数据处理方式是非常重要的。有了Hadoop2.0和YARN,机构可以采用流处理
互动数据处理方式以及其他的基于Hadoop的应用程序。
2. yarn架构
YARN还是经典的主从(master/slave)架构,如下图。大体上看,YARN服务由一个ResourceManager(RM)
和多个NodeManager(NM)构成,ResourceManager为主节点(master),NodeManager为从节点(slave)。
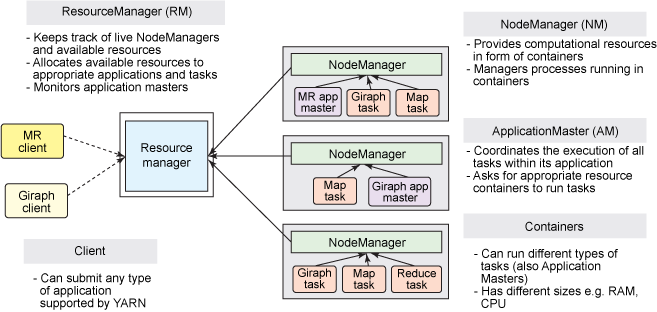
ApplicationMaster可以在容器内运行任何类型的任务。例如,MapReduceApplicationMaster请求容器启动map
或reduce任务,而Giraph ApplicationMaster请求容器运行Giraph任务。
3. yarn应用运行原理
YARN是如何工作的?YARN的基本理念是将JobTracker/TaskTracker两大职能分割为以下几个实体:
1. 一个全局的资源管理ResourceManager
2. 每个应用程序一个ApplicationMaster
3. 每个从节点一个NodeManager
4. 每个应用程序一个运行在NodeManager上的Container
ResourceManager和NodeManager组成了一个新的、通用的、用分布式管理应用程序的系统。
ResourceManager对系统中的应用程序资源有终极仲裁的权限。ApplicationMaster是一个特定于框架的实体,
它的责任是同ResourceManager谈判资源,同时为NodeManager(S)执行和监控组件任务。ResourceManager有一个
调度器,根据不同的约束条件,例如队列容量、用户限制等,将资源进行分配给各类运行着的应用程序。调度器执行的
调度功能是基于应用程序的资源申请。NodeManager负责发布应用程序容器,监控资源的使用并向ResourceManager进行汇报。
每个ApplicationMaster都有职责从调度器那谈判得到适当的资源容器,追踪它们的状态,并监控他们的进程。从系统
的视图看,ApplicationMaster作为一个普通的容器运行着。
3.1 yarn应用提交过程
Application在Yarn中的执行过程,整个执行过程可以总结为三步:
1. 应用程序提交
2. 启动应用的ApplicationMaster实例
3. ApplicationMaster实例管理应用程序的执行
具体提交过程为:
1. 客户端程序向ResourceManager提交应用并请求一个ApplicationMaster实例;
2. ResourceManager找到一个可以运行一个Container的NodeManager,并在这个Container中启动ApplicationMaster实例;
3. ApplicationMaster向ResourceManager进行注册,注册之后客户端就可以查询ResourceManager获得自己ApplicationMaster
的详细信息,以后就可以和自己的ApplicationMaster直接交互了(这个时候,客户端主动和ApplicationMaster交流,
应先向ApplicationMaster发送一个满足自己需求的资源请求);
4. 在平常的操作过程中,ApplicationMaster根据resource-request协议向ResourceManager发送resource-request请求;
5. 当Container被成功分配后,ApplicationMaster通过向NodeManager发送container-launch-specification信息来启动
Container,Container-launch-specification信息包含了能够让Container和ApplicationMaster交流所需要的资料;
6. 应用程序的代码以task形式在启动的Container中运行,并把运行的进度、状态等信息通过application-specific
协议发送给ApplicationMaster;
7. 在应用程序运行期间,提交应用的客户端主动和ApplicationMaster交流获得应用的运行状态,进度更新等信息,
交流协议也是application-specific协议;
8. 一旦应用程序执行完成并且所有相关工作也以及完成,ApplicationMaster向ResourceManager取消注册然后关闭,
用到所有的Container也归还系统;
精简版:步骤1:用户将应用程序提交到ResourceManager上;步骤2:ResourceManager为应用程序ApplicationMaster申请资源
并与某个NodeManager通信启动第一个Container,以启动ApplicationMaster;
步骤3:ApplicationMaster与ResourceManager注册进行通信,为内部要执行的任务申请资源,一旦得到资源后,
将于NodeManager通信,以启动对应的Task;步骤4:所有任务运行完成后,ApplicationMaster向ResourceManager注销,
整个应用程序运行结束。
3.2 MapReduce on yarn
MapReduce基于yarn的工作原理:我们通过提交jar包,进行MapReduce处理,那么这个那个运行过程分为五个环节:
1、向client端提交MapReduce job
2、随后yarn的ResourceManager进行资源的分配
3、由NodeManager进行加载与监控Containers
4、通过applicationMaster与ResourceManager进行资源的申请及状态的交互,由NodeManager进行
MapReduce运行时job的管理
5、通过hdfs进行job配置文件、jar包的各节点分发
Job初始化过程
1、当resourceManager收到了submitApplication()方法的调用通知后,Scheduler开始分配container,
随之ResourceManager发送applicationMaster进行,告知每个NodeManager管理器
2、由ApplicationMaster决定如何运行tasks,如果job数据量比较小,ApplicationMaster便选择将task运行在一个JVM
中。那么如何判断这个job是大是小呢?当一个job的mappers数量小于10个,只有一个reducer或者读取的文件大小要
小于HDFS block时,(可通过修改配置项
mapreduce.job.ubertask.maxmaps
mapreduce.job.ubertask.maxreduce以及
mapreduce.job.ubertask.maxbytes进行调整)
3、在运行task之前,applicationMaster将会调用setupJob()方法,随之创建output的输出路径(这就能够
解释,不管你的mapreduce一开始是否报错,输出路径都会创建)
Task任务分配
1、接下来applicationMaster向ResourceManager请求containers用于执行map与reduce的tasks(set 8),
这里map task的优先级要高于reduce task,当所有的map tasks执行了百分之五的时候,将会请求
reduce,具体下面再总结
2、 运行tasks的是需要消耗内存与CPU资源的,默认情况下,map和reduce的task资源分配为
1024M与一个核,(可修改运行的最小与最大参数配置,
mapreduce.map.memory.mb,
mapreduce.reduce.memory.mb,
mapreduce.map.cpu.vcores,
mapreduce.reduce.cpu.vcores)
Task任务执行
1、这时一个task已经被ResourceManager分配到一个container中,由applicationMaster告知nodemanager
启动container,这个task将会被一个主函数为YarnChild的java application运行,但在运行task之前,
首先定位task需要的jar包、配置文件以及加载在缓存中的文件。
2、YarnChild运行与一个专属的JVM中,所以任何一个map或reduce任务出现问题,都不会影响整个nodemanager的
crash或者hang。
3、每个task都可以在相同的JVM task中完成,随之将完成的处理数据写入临时文件中
MapReduce数据流进行进度与状态更新
1、MapReduce是一个较长运行时间的批处理过程,可以是一小时、几小时甚至几天,那么Job的运行状态监控
就非常重要。每个job的运行状态监控就非常重要。每个job以及每个task都有一个包含job
(running,successfully completed,tailed)的状态,以及value的计数器,状态信息及描述信息
(描述信息一般都是在代码中加的打印信息),那么,这些信息是如何与客户端进行通信的呢?
2、当一个task开始执行,它将会保持运行记录,记录task完成的比例,对于map的任务,将会记录其运行的
百分比,对于reduce来说可能复杂点,但系统依旧会估计reduce的完成比例,当一个map或reduce任务执行时,
子进程会持续每三秒钟与applicationMaster进行交互。Job完成
3.3 yarn应用生命周期
RM:Resource Manager
AM:Application Master
NM:Node Manager
1. Client向RM提交应用,包括AM程序及启动AM的命令
2. RM为AM分配宇哥容器,并与对应的NM通信,令其在容器上启动应用的AM
3. AM启动时向RM注册,允许Client向RM获取AM信息然后直接和AM通信
4. AM通过资源请求协议,为应用协商容器资源
5. 如容器分配成功,AM要求NM在容器中启动应用,应用启动后可以和AM独立通信
6. 应用程序在容器中执行,并向AM汇报
7. 在应用执行期间,Client和AM通信获取应用状态
8. 应用执行完成,AM向RM注销并关闭,释放资源。
申请资源=》启动appmaster=》申请宁运行任务的container=》分发task=》运行task=》task结束=》回收和container
4. 如何使用yarn
5. yarn调度器
未完成 01:05:34,今天脑子不在状态,就到这了,去过一遍hive了,拜拜了您嘞