mapreduce实现简单计数
准备工作:
1).添加程序所需要依赖的jar包
1.commons-cli:主要提供了解析命令行的库
2.commons-logging:常用的日志相关库
3.guava: guava的中文意思其实是石榴嘛,是google的一个开源项目。其中包含了很多java的常用库
4.hadoop-common:hadoop的基础依赖库,包括配置文件,文件系统,通信,安全等。
5.hadoop-mapreduce-client-core:顾名思义,这是编写mapreduce程序的核心依赖库了。
2)程序
package hadoop;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import java.io.IOException;
import java.util.StringTokenizer;
/**
* Created by admin on 2018/8/13.
*/
public class TestWord {
public static class WordMapper extends Mapper
@Override
public void map(LongWritable key, Text values, Mapper
String line = values.toString();
StringTokenizer st = new StringTokenizer(line);
while (st.hasMoreTokens()) {
String word = st.nextToken();
context.write(new Text(word), new IntWritable(1));
}
}
}
public static class WordReduce extends Reducer
@Override
public void reduce(Text key,Iterable
int sum = 0;
for(IntWritable it:iterable){
sum = sum + it.get();
}
context.write(key,new IntWritable(sum));
}
}
public static void main(String[] args) throws Exception{
Configuration con = new Configuration();
Job job = new Job(con);
job.setJarByClass(TestWord.class);
job.setJobName("words count!");
job.setMapOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
job.setMapperClass(WordMapper.class);
job.setReducerClass(WordReduce.class);
FileInputFormat.addInputPath(job,new Path("hdfs://hadoop1:9000/test1.txt"));
FileOutputFormat.setOutputPath(job,new Path("hdfs://hadoop1:9000/result/"));
job.waitForCompletion(true);
}
}
3)将程序打包并上传到hadoop3,如何打包下面链接有详细教程
https://blog.csdn.net/huangzhichang13/article/details/53580320
4)执行程序
./hadoop jar /home/hadoop/hadoop/test/wordcount.jar hadoop/TestWord
5)问题
1.
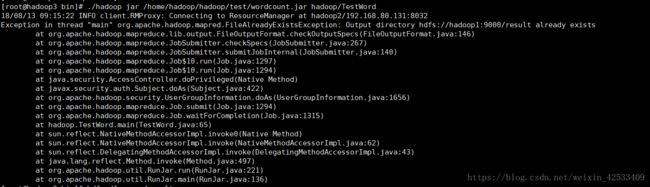
提示目录已存在,因为是防止用户出现误操作,替换掉原先的文件,所以不能覆盖已经存在的目录,将hdfs上的目录删除即可
2.org.apache.hadoop.yarn.exceptions.InvalidAuxServiceException: The auxService:mapreduce_shuffle does not exist

是因为这个配置错了,多了一个aux-services,去掉最后一个即可(3个节点的配置都需要)

正确结果,部分截图
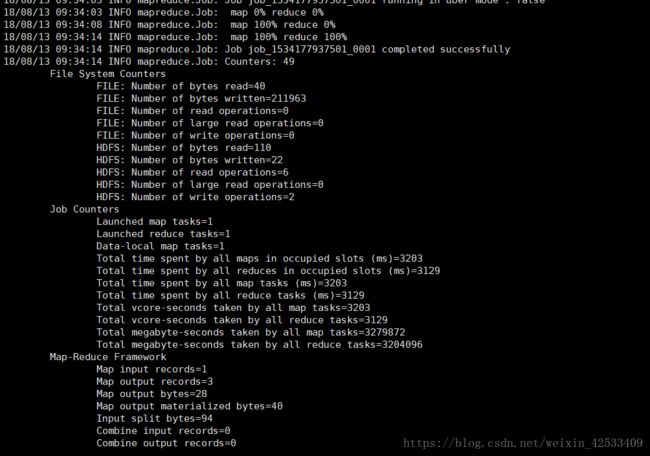


数据统计出来了