正则表达式学习:JAVA使用正则表达式递归校验JSON格式数据
由于工作中用到正则表达式不多,一直没有好好学习正则表达式。在网上找到了原版的精通正则表达式(第三版)电子版,抽时间详细学习,下面对最近学到的做个总结。
最近在进行安全检查漏洞修补,在做XSS攻击过滤器时,在后台对单双引号等字符进行了转义,这样影响到了JSON字符串的传递。为了解决这个问题,想在过滤时把JSON参数专门过滤出来不转义双引号。于是就开启了正则表达式的学习之路。
首先先附上JAVA配合正则递归校验JSON的源码
/**
* 方法名称:校验是否是有效JSON数据
* 概要说明:由于JAVA正则表达式没法递归,不能一个表达式进行匹配,只能用JAVA进行递归
* 字符串传来后进行匹配,普通类型数据仅匹配格式不捕获,将可能的JSON类型([] {})进行捕获,
* 递归进行校验,共设置四个捕获组,为了保证逗号分隔的格式是严格正确的,没有想到好的方法简化正则表达式
* 只能把数据分成两类,一类带逗号一类不带分别进行匹配.由于捕获组仅能匹配最后一个捕获结果,所以需要手动 进行字符串截取进行递归验证。
*
* 严格按照JSON官网给出的数据格式 双引号引起来的字符串 数字 JSONOBJECT JSONARRAY 波尔值和JSONNull
* 在[]{}以及逗号前后可以有任意空字符。
*
* @param value 数据
* @return boolean 是/不是
*/
public boolean isJSON(String value) {
try {
boolean result = false;
String jsonRegexp = "^(?:(?:\\s*\\[\\s*(?:(?:"
+ "(?:\"[^\"]*?\")|(?:true|false|null)|(?:[+-]?\\d+(?:\\.?\\d+)?(?:[eE][+-]?\\d+)?)|(?(?:\\[.*?\\])|(?:\\{.*?\\})))\\s*,\\s*)*(?:"
+ "(?:\"[^\"]*?\")|(?:true|false|null)|(?:[+-]?\\d+(?:\\.?\\d+)?(?:[eE][+-]?\\d+)?)|(?(?:\\[.*?\\])|(?:\\{.*?\\})))\\s*\\]\\s*)"
+ "|(?:\\s*\\{\\s*"
+ "(?:\"[^\"]*?\"\\s*:\\s*(?:(?:\"[^\"]*?\")|(?:true|false|null)|(?:[+-]?\\d+(?:\\.?\\d+)?(?:[eE][+-]?\\d+)?)|(?(?:\\[.*?\\])|(?:\\{.*?\\})))\\s*,\\s*)*"
+ "(?:\"[^\"]*?\"\\s*:\\s*(?:(?:\"[^\"]*?\")|(?:true|false|null)|(?:[+-]?\\d+(?:\\.?\\d+)?(?:[eE][+-]?\\d+)?)|(?(?:\\[.*?\\])|(?:\\{.*?\\}))))\\s*\\}\\s*))$";
Pattern jsonPattern = Pattern.compile(jsonRegexp);
Matcher jsonMatcher = jsonPattern.matcher(value);
if (jsonMatcher.matches()) {
result = true;
for (int i = 4; i >= 1; i--) {
if (!StringUtils.isEmpty(jsonMatcher.group("json" + i))) {
result = this.isJSON(jsonMatcher.group("json" + i));
if (!result) {
break;
}
if (i == 3 || i == 1) {
result = this.isJSON(value.substring(0, jsonMatcher.start("json" + i))
+ (i == 3 ? "\"JSON\"}" : "\"JSON\"]"));
if (!result) {
break;
}
}
}
}
}
return result;
} catch (Exception e) {
return false;
}
}
JSON官方给出JSON数据格式
http://www.json.org/json-zh.html
JSONARRAY [value,value,…,value]
JSONOBJECT {“string”:value,…,“string”:value}
正则表达式无法去引用规则,只能引用捕获组捕获的内容。所以递归由JAVA完成。
首先字符串自身必须满足上述JSON格式,其中只有嵌套的JSON数据不好判断,于是将这部分value进行捕获,捕获后内容也要符合JSON格式,再调用本身去判断。
又由于捕获组只能捕获最后一个内容,相当于每次校验只能捕获到最后两个JSON格式数据。但是JAVA中可以获取他们的位置。于是将倒数第二个JSON往后的部分截去,再去校验截去后的字符串,直到字符串中没有JSON格式的数据且符合JSON基本数据格式。
(?:\"[^\"]*?\") --> 双引号引起的任意字符串,不可包含双引号
本身还有反斜杠,但是项目功能需要所以去掉了
(?:true|false|null) --> 波尔值和JSONNULL
(?:[+-]?\\d+(?:\\.?\\d+)?(?:[eE][+-]?\\d+)?) 数字 浮点数+科学计数法
(?(?:\\[.*?\\])|(?:\\{.*?\\})) JSON数据捕获后迭代进行判断
正则表达式如同名字所说,是一个规则表达式(Regular Expression)。他表达的是一种规则,我们要学习的就是如何去书写规则。
最基础的就是如何去匹配各种字符以及控制字符所出现的顺序与个数。
网上到处都有介绍的。
百度百科:https://baike.baidu.com/item/正则表达式/1700215?fr=aladdin#7
我们用一个正则表达式匹配时,不论正则表达式如何写,如何分组,首先会在内容中去完整整个正则表达式,整个正则表达式匹配是其他操作成立的前提。所以理解书写一个正则表达式首先去关注整个正则表达式的匹配。
书写正则表达式可以拆分成很多最基础的元素进行叠加,就像是叠加积木一样。
1.字符
正则表达式在校验字符串时,最基础的是每一个字符位。每个字符位可以使用字符本身进行匹配比如 regExp=“a” 就匹配字符a,也可以使用方括号+表达式 [表达式] 进行匹配。表达式就是一个集合,可以进行交、并、非等运算去限定可以匹配字符的范围。比如regExp="[^a]"就匹配除a以外的字符。
在每一个字符后可以限定字符出现的次数,默认不带匹配符号就是1次。具体符号可以在上面百度百科介绍。
2.字符串
使用括号()将多个字符按顺序组合起来就可以成为一个可操作的字符串。在括号后就可以使用数量符号,连续匹配多次字符串。比如regExp="(aaa)?" 就可以匹配字符串 aaa一次或者0次。
会写正则表达式就需要三点
1.明确要匹配字符串的格式,具有规律。
2.知道字符用什么去匹配,比如空格\n 反斜杠\ 得双写匹配原字符\等等。
3.知道如何控制字符的数量,比如大括号{5}代表五次,{1-5}代表一次到五次之间都可以。
知道这三个就可以写出绝大多数的正则表达式了。
比如邮箱校验
用户名 + “ @” + 邮箱名 + “.” + “com/cn” (规则可能不准确)
1.用户名可以是多位字母、数字、下划线
[a-z|A-Z|0-9|] 匹配一个字符 可以是a-z的小写字母,A-Z大写字母,或者是0-9数字,或者是下划线。
用户名不能为空至少有一位。 于是字符出现次数>=1,即 [a-z|A-Z|0-9|]+
2.@就用原字符匹配就可以 必须出现一次
3.邮箱名比如限定只能是163、126邮箱 (163|126) 必须出现一次
或者和用户名一样字母数字下划线组成的名字
4. 点在正则表达式中代表任意字符,匹配原字符要用 . 必须出现一次
5. com/cn 就是(com|cn)必须出现一次
组合起来就是
[a-z|A-Z|0-9|_]+@(163|126).(com|cn)
这就是最后的正则表达式。
非常简单 就是把规则拆分成各个小部分,每个部分的字符和次数指定好,拼接起来就OK。需要注意的一点是写正则不要随便打空格,空格也是需要去匹配的。
能够写最基础的正则表表达式后就可以继续学习分组和捕获。
分组
在上面使用括号()就是所谓的分组。
而捕获的意思就是能够把其中的一部分匹配到的内容记录下来。
就以 [a-z|A-Z|0-9|_]+@(163|126).(com|cn) 为例。
我匹配的邮箱是[email protected]
这个正则表达式在匹配时,会记录三组匹配内容。
第一组 group0 :组0是默认的,不需要使用括号,这是所有正则表达式整体表达式匹配结果。匹配成功就记录整个表达式。所以值就是 [email protected]
表达式中有还有两对括号,所以还有组1 组2
第二组 group1:第二组表达式是 (163|126) 所以他记录的就是邮箱名的部分,在我匹配的里面就是163 ,所以group1的值就是 163
同理第三组group2:就是最后的尾缀即 com
所以次正则表达式我们捕获到了三组匹配的内容。
捕获组
捕获的作用既可以在当前正则表达式中引用,也可以在相应的程序里使用,比如在JAVA中使用matcher.group()方法获取内容,进行其他处理。
分组的名称如果没有命名,就是默认的数组分组。分组数量好像有上限是9个。
如果想自己给分组命名,就在括号中加入(?<组名>表达式)组名尖括号后一定不要顺手打空格!
以上两种就是 捕获组。会将匹配内容记录下来供我们使用。
如果我们不需要让他记录,可能会浪费资源,比如内存等。
我们就有了 非捕获组。
非捕获组
(?:表达式)
只要在括号中起始加入?:就可以不捕获该分组。
这时默认的数字分组名称会统计所有有效的 捕获组,而不会去管非捕获组。
还有其他非捕获组
1.表达式(?=表达式) 2.(?<=表达式)表达式 3.表达式(?!表达式)4.(?表达式
仔细观察上方四个捕获组写法,
1.括号中以?开头
2. ! 代表 非/否定 ,= 代表 是/肯定,所以?= 就代表着 右边部分匹配这个表达式, ?! 就代表右边部分不能匹配这个表达式。他们写在主表达式的右方,代表 后面的表达式必须出现在主表达式的右边。
3. 如果要在左边进行限定则 使用 <号,代表表达式在左边。
除了基本非捕获组(?:)以外的四个非捕获组的匹配部分是不计算在整个表达式匹配结果中的,相当于需要匹配两次
不仅要带上该非捕获组表达式能够匹配成功
还要去掉该非捕获组的表达式也能成功匹配!
否则是无法匹配的。
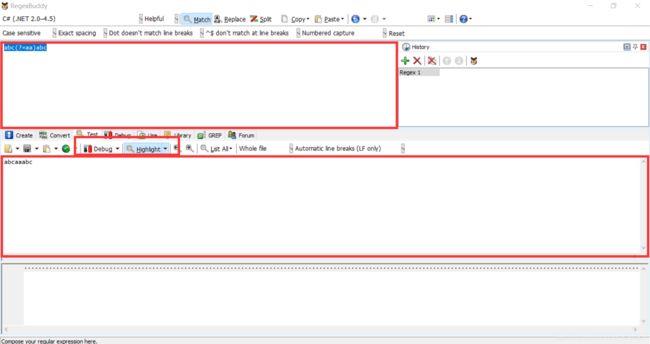
regExp=“abc(?=aa)abc” 匹配字符串 abcaaabc
上述匹配时失败的。 (?=)就像一个关卡一样,通过了,关卡就会消失,接着之前的地方继续匹配。
上述匹配过程实际上是
1.abc 匹配到 abc ,
2.匹配(?=aa) 通过关卡。
3.这是正则表达式变成了 “abcabc”,匹配字符串 abcaaabc ,结果是失败了。
以之前邮箱例子
- [a-z|A-Z|0-9|_]+@(163|126).(com|cn)
- [a-z|A-Z|0-9|_]+@(
163|126).(? com|cn) - [a-z|A-Z|0-9|_]+@(?:163|126).(?:com|cn)
- [a-z|A-Z|0-9|_]+@(?:163|126).(?=com|cn)
匹配字符串为 [email protected]
三个正则表达式都可以成功匹配
第一个匹配得到三个组 组0:[email protected] 组1:163 组2:126
第二个匹配和第一个匹配相同,三个组,但是组1 可以使用group(mailName)进行获取,组2可以用group(suff)进行获取结果。
第三个匹配得到一个组 组0:[email protected]
第四个匹配得到一个组 组0:xjwjy002@163.
在写正则表达式时
软件 RegexBuddy 非常的好用。上方红框写正则表达式,下方写匹配的字符串。
debug可以查看正则表达式匹配的过程,每一步。还可以查看每个捕获组的结果和位置。使用非常简便。