Hadoop——HDFS编程学习笔记
上次学习的是HDFS基于Shell命令行的模式.
HDFS JAVA API
HDFS支持JVA的接口,利用JAVA API 中的库来读写HDFS中的文件
例子:
使用HadoopURL读取数据
1. java.net.URL打开一个数据输入流
inputStream in = null;
try {
in = new URL( "hdfs:namenode/path" ).openStream();
..//处理代码
} finally {
IOUtils.closeStream(in); //关闭输出流
}
使用IOUtils工具类,FS的IO工具类
例RULCAT
1. 运行方式
1. Hadoop CLASSNAME
2. 注:需要设置HADOOP_CLASSPATH路径.
实践:
首先我们需要设置路径,找到三个jar包.
/opt/module/hadoop-2.6.5/share/hadoop/common/lib/commons-cli-1.2.jar
/opt/module/hadoop-2.6.5/share/hadoop/common/hadoop-common-2.6.5.jar
/opt/module/hadoop-2.6.5/share/hadoop/mapreduce/hadoop-mapreduce-client-core-2.6.5.jar

配置HADOOP_CLASSPATH:
export HADOOP_CLASSPATH=.:${HADOOP_HOME}/javabin
![]()
向云端上传文件:
Hadoop 开发环境
Eclipse.
- 把插件放到Eclipse的plugins里面.
- 设置本地的Hadoop工作路径
- 连接到Linux上的Hadoop上,通过IP地址.
- 创建一个项目进行代码的测试.
HDFS读写数据流
Hadoop文件API的起点是FileSystem抽象类
1. org.apache.hadoop.fs.FileSystem
2. org.apache.hadoop.conf.Configuration
-----一个键值对的配置类 #JavaDoc#
— core-default.xml core-site.xml
使用FileSystem API读取数据
1. 通过factory方法获得文件系统实例
FileSystem.get(Configuration conf)
Filesystem.get(URI uri, Configuration conf)
2. 调用open方法获得文件输入流 #javadoc#
3. 返回
org.apache.hadoop.fs.FSDataInputStream
public clas FSDataInputStream
extends java.io.DataInputStream
inpulements Seekable, PositionedReadable
输入支持随机读取
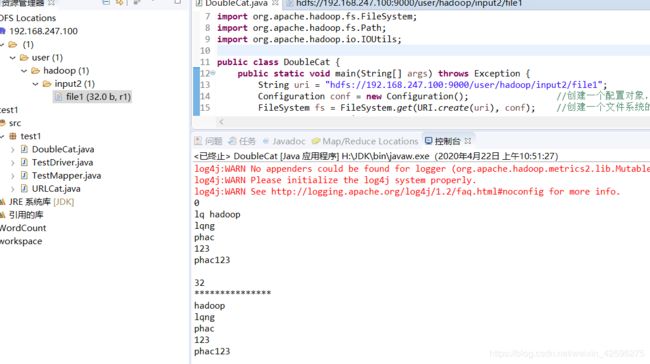
例子:DoubleCat
代码:
package test1;
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
public class DoubleCat {
public static void main(String[] args) throws Exception {
String uri = "hdfs://192.168.247.100:9000/user/hadoop/input2/file1";
Configuration conf = new Configuration(); //创建一个配置对象,它能读取一些基本的配置内容
FileSystem fs = FileSystem.get(URI.create(uri), conf); //创建一个文件系统的实例
FSDataInputStream in = null;
try {
//通过 open方法获得文件输入流
in = fs.open(new Path(uri)); //使用open的方法建立一个流
System.out.println(in.getPos()); //读取初始的位置
IOUtils.copyBytes(in, System.out, 4096, false); //把文件里面的内容输出
System.out.println(); //换行
System.out.println(in.getPos()); //读取现在的位置
System.out.println("***************"); //为了区分输出一串*号进行分割
in.seek(3); // go back to pos 3 of the file //把位置调整到3号位置
IOUtils.copyBytes(in, System.out, 4096, false); //再次输出,即应该从3号位置继续往外输出
// fs.mkdirs(new Path("hdfs://192.168.247.100:9000/user/hadoop/data0417"));
} finally {
IOUtils.closeStream(in);
}
}
}
运行结果:
创建目录:
public boolean mkdirs(Path f) throws IOException
写数据:
public FSDataOutputStream create(Path f) 建文件
…create重载函数 #javadoc#
public FSDataOutputStream append(Path f) 追加数据
…append 重载函数 #javadoc#
public interface Progressable 报告操作过程 #javadoc#
#例 FileCopyWithProgress#
代码:
package test1;
import java.io.BufferedInputStream;
import java.io.FileInputStream;
import java.io.InputStream;
import java.io.OutputStream;
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.util.Progressable;
public class FileCopyWithProgress {
public static void main(String[] args) throws Exception {
String localSrc = "testdata/input/1.log";
String dst = "hdfs://192.168.247.100:9000/user/hadoop/up0417/f1";
InputStream in = new BufferedInputStream(new FileInputStream(localSrc)); //建立一个缓冲流
//下面两步是建立一个文件系统标准的过程.
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(URI.create(dst), conf);
OutputStream out = fs.create(new Path(dst), new Progressable() { //输出流,即云端的文件去写入数据
//Progressable()接口,它可以让我们在写入数据的时候,每隔一定的字节就调用一次
/* (non-Javadoc)
* HDFS在每写入64K数据包后调用progress函数
* 64K是HDFS写入datanode的最小单位
*/
public void progress() {
System.out.print("*");
}
});
IOUtils.copyBytes(in, out, 4096, true);
}
}
运行效果(这里还没做好,因为我的文件的权限没有写得权限):
![]()
文件系统
- 文件元数据FileStatus, 封装了文件长度,块大小,副本,修改时间,所有者和许可信息.
– org.apache.hadoop.fs.FileStatus #javadoc# - 获取元数据的方法
public abstract FileStatus getFileStatus(Path f)
public abstract FileStatus[] listStatus(Path f)
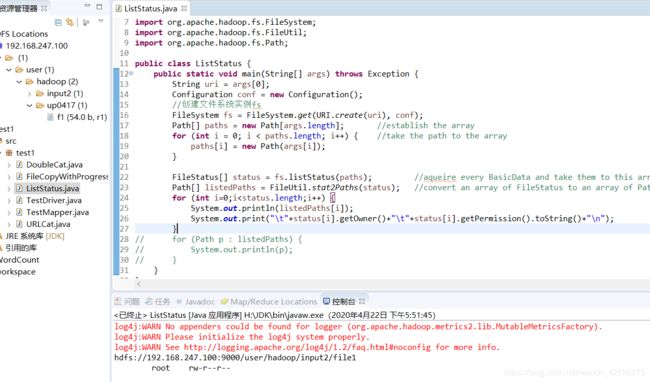
#列ListStatus#
package test1;
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.FileUtil;
import org.apache.hadoop.fs.Path;
public class ListStatus {
public static void main(String[] args) throws Exception {
String uri = args[0];
Configuration conf = new Configuration();
//创建文件系统实例fs
FileSystem fs = FileSystem.get(URI.create(uri), conf);
Path[] paths = new Path[args.length]; //establish the array
for (int i = 0; i < paths.length; i++) { //take the path to the array
paths[i] = new Path(args[i]);
}
FileStatus[] status = fs.listStatus(paths); //aqueire every BasicData and take them to this array
Path[] listedPaths = FileUtil.stat2Paths(status); //convert an array of FileStatus to an array of Path
for (int i=0;i<status.length;i++) {
System.out.println(listedPaths[i]);
System.out.print("\t"+status[i].getOwner()+"\t"+status[i].getPermission().toString()+"\n");
}
// for (Path p : listedPaths) {
// System.out.println(p);
// }
}
}
for this example, It is important for us to write the running’s configuration in running configuration, then, we can write the variable.Finally, we can run this program.The running picture is this :
Files’ read and write
-Input Stream
-org.apache.hadoop.fs.FSDataInputStream
.read()
-org.apache.hadoop.fs.FSDataOutputStream
.write()
-#p36, merge and put the program PutMerge#
Summary:for Hadoop files’ write and read, we need the format of Stream.
When we need to write something into files, we can user the InputStream, and when we want to get the files’ data, we can use the OutStream
删除数据:
—public boolean delete(Path f,boolean recursive)
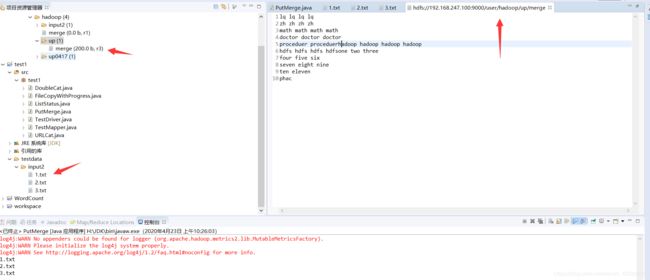
列子:实现本地多个文件合并后写入云端的一个文件
程序:
package test1;
import java.io.IOException;
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class PutMerge { //合并多个文件上传
public static void main(String[] args) throws IOException {
Configuration conf = new Configuration(); //创建一个配置
String uri = "hdfs://192.168.247.100:9000/user/hadoop/up/merge"; //指定云端的上传路径
Path inputDir = new Path("testdata/input2"); //本地路径
Path hdfsFile = new Path(uri); //设置远端的文件
// 即为了实现从本地路径向远端路径进行写数据.
try {
FileSystem hdfs = FileSystem.get(new URI(uri),conf); //建立远端的文件系统
FileSystem local = FileSystem.getLocal(conf); //创建本地的文件系统
FileStatus[] inputFiles = local.listStatus(inputDir); //列出本地路径中的所有的项
FSDataOutputStream out = hdfs.create(hdfsFile); //建立远端的一个输出流
for (int i=0; i<inputFiles.length; i++) {
System.out.println(inputFiles[i].getPath().getName()); //输出当前本地文件的名称
FSDataInputStream in = local.open(inputFiles[i].getPath()); //建立本地文件的输入流
byte buffer[] = new byte[256]; //建立一个缓冲区
int bytesRead = 0;
while( (bytesRead = in.read(buffer)) > 0) { //只要当前缓冲区中的字节数大于0,就将其写入到输出流中.
out.write(buffer, 0, bytesRead);
}
in.close(); //本地的当前文件读取成功后,就将其关掉.
}
out.close(); //全部写入成功后,就关掉输出流.
} catch (Exception e) {
e.printStackTrace();
}
}
}
遇到的问题:
权限不够
![]()
解决方法1:
这里指出云端的merge文件只能由超级用户组中的root用户才能进行写操作,所以我们在指定文件系统的时候,可以通过下面这行代码,指定进行操作的用户:
FileSystem hdfs = FileSystem.get(new URI(uri),conf, "root");
运行成功:
HDFS中的读写数据流:
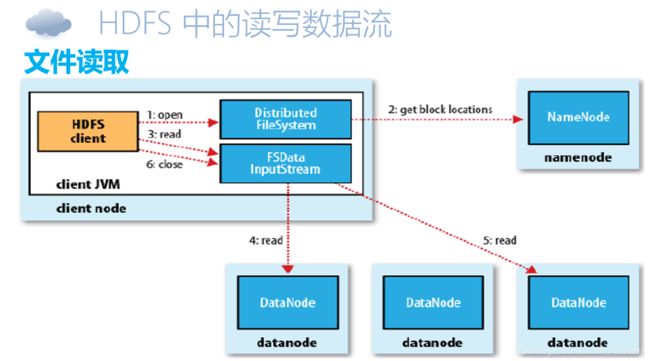
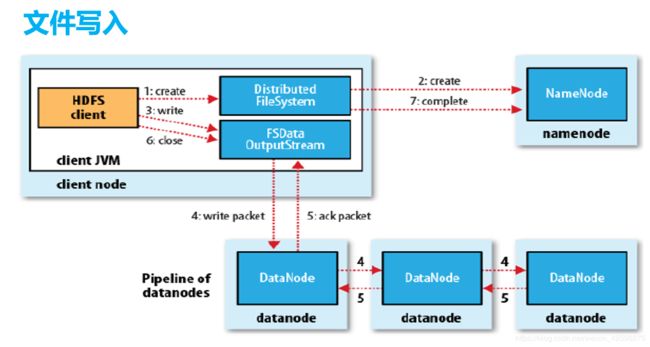
数据写出,一般需要写三份.
一致性模型
创建一个文件时,在命名空间中可见,但对这个文件的任何写操作不保证是可见的;简单的来说,就是当我们一个文件进行写操作的时候,由于这里会有延迟,而导致我们并不能看到这个文件的存在,如果想要强制看到,可以去刷新数据流,把数据流中写入到云端中,这样就保证了,文件在云端命名空间可见,在实际的数据块中也是可见的.
FSDataOutputStream out = fs.create(uri);
out.write(…)
out.flush(); (数据流刷新命令)
HDFS提供了缓存和DataNode之间数据强制同步的方法 out.sync();
应注意sync()方法将带来极大的开销.(会降低HDFS的性能,如果是特别重要的数据的话,可以考虑这样做,快速实现缓存和DataNode之间的数据强制同步).