hdfs的高可用配置及java api配置连接方式
配置之前需要具备的环境

进入官网后找到左侧Documentation,点击对应版本
点击左侧栏

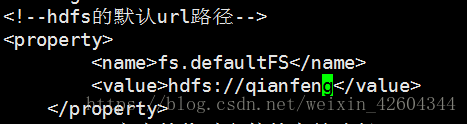
修改core-site.xml文件
进入目录
[root@hadoop01 ~]# cd /usr/local/hadoop-2.7.1/etc/hadoop/
vi 进入后找到

修改为(名字随便起)
添加
ha.zookeeper.quorum
hadoop01:2181,hadoop02:2181,hadoop03:2181
再配置hdfs-site.xml
添加(这里的mycluster要跟上面的名字的保持一致,example.com要改成机器名)nn1和nn2分别代表namenode1,namenode2
因为这里只用了两台机器,所以dfs.namenode.rpc-address.[nameservice ID].[name node ID]与dfs.namenode.http-address.[nameservice ID].[name node ID]只需要添加nn1和nn2
dfs.nameservices
qianfeng
dfs.ha.namenodes.qianfeng
nn1,nn2
dfs.namenode.rpc-address.qianfeng.nn1
hadoop01:9000
dfs.namenode.rpc-address.qianfeng.nn2
hadoop02:9000
dfs.namenode.http-address.qianfeng.nn1
hadoop01:50070
dfs.namenode.http-address.qianfeng.nn2
hadoop02:50070
dfs.namenode.shared.edits.dir
qjournal://hadoop01:8485;hadoop02:8485;hadoop03:8485/qianfeng
dfs.client.failover.proxy.provider.qianfeng
org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider
dfs.ha.fencing.methods
sshfence
shell(/bin/true)
dfs.ha.fencing.ssh.private-key-files
/root/.ssh/id_rsa
dfs.ha.fencing.ssh.connect-timeout
30000
以上是网页中的(是最简版)在老师给的文件中还有其他配置文件
继续添加
dfs.journalnode.edits.dir
/usr/local/hadoopdata/journaldata
dfs.ha.automatic-failover.enabled
true
翻到最后找到这两个,将其关闭
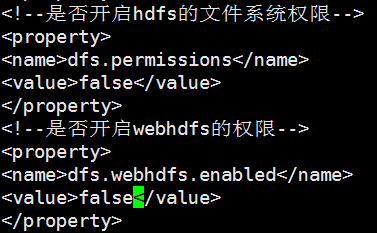
删除这两个配置文件

再配置yarn
点击进来开始按照说明配置
vi 进入yarn-site.xml
除了最上面的
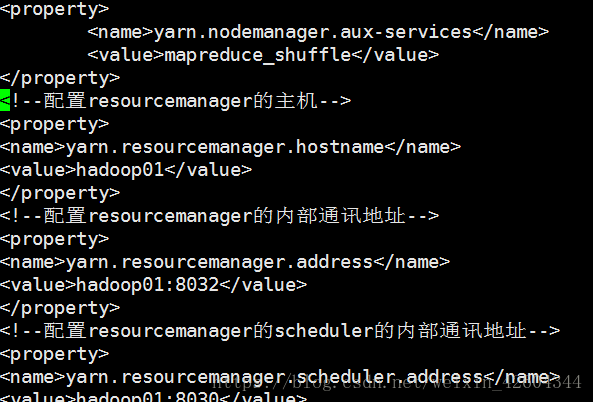
添加
yarn.resourcemanager.ha.enabled
true
yarn.resourcemanager.cluster-id
qianfeng
yarn.resourcemanager.ha.rm-ids
rm1,rm2
yarn.resourcemanager.hostname.rm1
hadoop01
yarn.resourcemanager.hostname.rm2
hadoop02
yarn.resourcemanager.webapp.address.rm1
hadoop01:8088
yarn.resourcemanager.webapp.address.rm2
hadoop02:8088
yarn.resourcemanager.zk-address
hadoop01:2181,hadoop02:2181,hadoop03:2181
全部配置完成后分发
[root@hadoop01 hadoop]# scp core-site.xml hdfs-site.xml yarn-site.xml root@hadoop02:$PWD
[root@hadoop01 hadoop]# scp core-site.xml hdfs-site.xml yarn-site.xml root@hadoop03:$PWD切换到local目录下 删除hadoopdata(三台机器都要删除)
jps看看三台机器QuorumPeerMain有没有启动,如果没有就启动
三台机器再启动journalnode
[root@hadoop01 hadoop-2.7.1]# hadoop-daemon.sh start journalnode发现两台子机器不能启动

是因为环境变量没有配好 配好之后 source /etc/profile
之后进行namenode的初始化(保证机器之间互相免密)
只在一台机器进行即可:hdfs namenode -format
启动namenode: hdfs-daemon.sh start namenode
在local目录下把Hadoopdata分发给另外两台机器
在hadoop01上格式化zkfc: hdfs zkfc -formatZK
启动start-dfs.sh
启动yarn
start-yarn.sh
注意:standby的resourcemanager不会自动启动,需要手动去启动
管理:
hdfs dfsadmin -
hdfs haadmin -
yarn的管理命令:
yarn rmadmin -
手动:
vi hdfs-site.xml
vi yarn-site.xml
启动集群后,两个namenode都是standby状态,需要手动切换一台namenode为active
hdfs haadmin -transitionToStandby --forcemanual nn2
hdfs haadmin -transitionToActive nn1
手动的前提是修改hdfs-site.xml里的true为false

----------------------------------------------------------------------------------------------------------------------------------------------
第一种方式:
conf.set("fs.defaultFS","hdfs://qianfeng");
conf.set("dfs.nameservices","qianfeng");
conf.set("dfs.ha.namenodes.qianfeng","nn1,nn2");
conf.set("dfs.namenode.rpc-address.qianfeng.nn1","hadoop05:9000");
conf.set("dfs.namenode.rpc-address.qianfeng.nn2","hadoop06:9000");
conf.set("dfs.client.failover.proxy.provider.qianfeng","org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider");
第二种方式:
将core-site.xml和hdfs-site.xml下载到本地
再将这两个文件copy到工程中的resource目录下