c++ 3:STL概论、容器
一. STL概论
STL基本概念
STL(Standard Template Library,标准模板库),是惠普实验室开发的一系列软件的统称。现在主要出现在 c++中,但是在引入 c++之前该技术已经存在很长时间了。
STL 从广义上分为: 容器(container) 算法(algorithm) 迭代器(iterator)。容器和算法之间通过迭代器进行无缝连接。STL 几乎所有的代码都采用了模板类或者模板函数,这相比传统的由函数和类组成的库来说提供了更好的代码重用机会。STL(Standard Template Library)标准模板库,在我们 c++标准程序库中隶属于 STL 的占到了 80%以上。
(1) STL六大组件简介
STL提供了六大组件,彼此之间可以组合套用,这六大组件分别是:容器、算法、迭代器、仿函数、适配器(配接器)、空间配置器。
容器:
各种数据结构,如vector、list、deque、set、map等,用来存放数据,从实现角度来看,STL容器是一种class template。
算法:
各种常用的算法,如sort、find、copy、for_each。从实现的角度来看,STL算法是一种function tempalte.
迭代器:
扮演了容器与算法之间的胶合剂,共有五种类型,从实现角度来看,迭代器是一种将operator* , operator-> , operator++,operator–等指针相关操作予以重载的class template. 所有STL容器都附带有自己专属的迭代器,只有容器的设计者才知道如何遍历自己的元素。原生指针(native pointer)也是一种迭代器。
仿函数:
行为类似函数,可作为算法的某种策略。从实现角度来看,仿函数是一种重载了operator()的class 或者class template
适配器:
一种用来修饰容器或者仿函数或迭代器接口的东西。
空间配置器:
负责空间的配置与管理。从实现角度看,配置器是一个实现了动态空间配置、空间管理、空间释放的class tempalte.
STL六大组件的交互关系:
容器通过空间配置器取得数据存储空间,算法通过迭代器存储容器中的内容,仿函数可以协助算法完成不同的策略的变化,适配器可以修饰仿函数
(2) STL优点
STL是C++的一部分,因此不用额外安装什么,它被内建在你的编译器之内。
STL的一个重要特性是将数据和操作分离。数据由容器类别加以管理,操作则由可定制的算法定义。迭代器在两者之间充当“粘合剂”,以使算法可以和容器交互运作
程序员可以不用思考 STL 具体的实现过程,只要能够熟练使用 STL 就 OK 了。这样他们就可以把精力放在程序开发的别的方面。
STL 具有高可重用性,高性能,高移植性,跨平台的优点。
(3) STL三大组件
<1> 容器
容器,置物之所也。研究数据的特定排列方式,以利于搜索或排序或其他特殊目的,这一门学科我们称为数据结构。常用的数据结构:数组(array),链表(list),tree(树),栈(stack),队列(queue),集合(set),映射表(map)。根据数据在容器中的排列特性,这些数据分为序列式容器和关联式容器两种。
序列式容器强调值的排序,序列式容器中的每个元素均有固定的位置,除非用删除或插入的操作改变这个位置。Vector容器、Deque容器、List容器等。
关联式容器是非线性的树结构,更准确的说是二叉树结构。各元素之间没有严格的物理上的顺序关系,也就是说元素在容器中并没有保存元素置入容器时的逻辑顺序。关联式容器另一个显著特点是:在值中选择一个值作为关键字key,这个关键字对值起到索引的作用,方便查找。Set/multiset容器 Map/multimap容器
<2> 算法
算法,问题之解法也。
以有限的步骤,解决逻辑或数学上的问题,这一门学科我们叫做算法(Algorithms).
广义而言,我们所编写的每个程序都是一个算法,其中的每个函数也都是一个算法,毕竟它们都是用来解决或大或小的逻辑问题或数学问题。STL收录的算法经过了数学上的效能分析与证明,是极具复用价值的,包括常用的排序,查找等等。特定的算法往往搭配特定的数据结构,算法与数据结构相辅相成。
算法分为:质变算法和非质变算法。
质变算法:是指运算过程中会更改区间内的元素的内容。例如拷贝,替换,删除等等
非质变算法:是指运算过程中不会更改区间内的元素内容,例如查找、计数、遍历、寻找极值等等。
<3> 迭代器
迭代器(iterator)是一种抽象的设计概念,现实程序语言中并没有直接对应于这个概念的实物。在<>一书中提供了23中设计模式的完整描述,其中iterator模式定义如下:提供一种方法,使之能够依序寻访某个容器所含的各个元素,而又无需暴露该容器的内部表示方式。
迭代器的设计思维-STL的关键所在,STL的中心思想在于将容器(container)和算法(algorithms)分开,彼此独立设计,最后再一贴胶着剂将他们撮合在一起。从技术角度来看,容器和算法的泛型化并不困难,c++的class template和function template可分别达到目标,如果设计出两这个之间的良好的胶着剂,才是大难题。
迭代器的种类:
输入迭代器 提供对数据的只读访问 只读,支持++、、!=
输出迭代器 提供对数据的只写访问 只写,支持++
前向迭代器 提供读写操作,并能向前推进迭代器 读写,支持++、、!=
双向迭代器 提供读写操作,并能向前和向后操作 读写,支持++、–,
随机访问迭代器 提供读写操作,并能以跳跃的方式访问容器的任意数据,是功能最强的迭代器 读写,支持++、–、[n]、-n、<、<=、>、>=
二. 容器、迭代器、算法初体验
#include
#include
for_each算法的本质:
for (; _First != _Last; ++_First)
_Func(*_First);
vector::iterator it = v.begin() ;
v.begin()指向第一个数据 v.end() 指向最后一个数据的下一个地址
*it类型为vector<>括号里的类型
1. vector基础用法
void test01()
{
vectorv;
v.push_back(66);
v.push_back(881);
//1.通过迭代器遍历
//for (vector::iterator it = v.begin(); it != v.end(); it++) {
// cout << *it << endl;
//}
//通过算法foreach遍历 //
for_each(v.begin(), v.end(), call_back);
}
2. vector容器放自定义数据类型
class person
{
public:
person(string m_name, int m_age):name(m_name),age(m_age){}
string name;
int age;
};
void call_back(person &val) //函数传参传引用,能节省一份开销,不然会调用拷贝构造
{
cout << val.name << " age is " << val.age << endl;
}
void test()
{
vectorv;
person p1("xiao hong", 17);
person p2("xiao liang", 271);
v.push_back(p1); //调用拷贝构造,拷贝一份p1放入容器
v.push_back(p2);
//1.通过迭代器遍历
//for (vector::iterator it = v.begin(); it != v.end(); it++) {
// cout << (*it).name << " age is " << it->age << endl;
//}
//通过算法foreach遍历 使用STL库算法需要包含#include
for_each(v.begin(), v.end(), call_back);
}
3. vector容器中放自定义数据类型的指针
void test()
{
vectorv;
person p1("xiao hong", 17); person p2("xiao liang", 28);
v.push_back(&p1); v.push_back(&p2);
for (vector::iterator it = v.begin(); it != v.end(); it++) {
cout << (*it)->name << " age is " << (*(*it)).age << endl;
}
}
4. 容器嵌套容器
void test()
{
vector>v; vectorvbase1; vectorvbase2;
for(int i = 0; i < 2; i++) {
vbase1.push_back(i+1);
vbase2.push_back(i+100);
}
v.push_back(vbase1); v.push_back(vbase2);
for (vector>::iterator it = v.begin(); it != v.end(); it++)
{
for (vector::iterator ich = (*it).begin(); ich != (*it).end(); ich++) {
cout << *ich << " ";
}
cout << endl;
}
}
void test()
{
vector>v; vectorvbase1; vectorvbase2;
vbase1.push_back("一年级三班");vbase1.push_back("王小利");vbase1.push_back("赵玉田 ");
vbase2.push_back("一年级四班");vbase2.push_back("王大拿");vbase2.push_back("老刘");
v.push_back(vbase1); v.push_back(vbase2);
for (vector>::iterator it = v.begin(); it != v.end(); it++)
{
for (vector::iterator ich = (*it).begin(); ich != (*it).end(); ich++) {
cout << *ich << " ";
}
cout << endl;
}
}
三. 容器
3.1 string容器
#include
1. string容器基本概念:
C风格字符串(以空字符结尾的字符数组)太过复杂难于掌握,不适合大程序的开发,所以C++标准库定义了一种string类,定义在头文件。
String和c风格字符串对比:
Char*是一个指针,String是一个类
string封装了char*,管理这个字符串,是一个char*型的容器。
String封装了很多实用的成员方法
查找find,拷贝copy,删除delete 替换replace,插入insert
不用考虑内存释放和越界
string管理char*所分配的内存。每一次string的复制,取值都由string类负责维护,不用担心复制越界和取值越界等。
2. string容器常用操作:
(1) 构造函数
string(); //创建一个空的字符串 例如: string str;
string(const string& str); //使用一个string对象初始化另一个string对象
string(const char* s); //使用字符串s初始化
string(int n, char c); //使用n个字符c初始化
(2) 基本赋值操作
string& operator=(const char* s); //char*类型字符串 赋值给当前的字符串
string& operator=(const string &s); //把字符串s赋给当前的字符串
string& operator=(char c); //字符赋值给当前的字符串
string& assign(const char *s); //把字符串s赋给当前的字符串
string& assign(const char *s, int n); //把字符串s的前n个字符赋给当前的字符串
string& assign(const string &s); //把字符串s赋给当前字符串
string& assign(int n, char c); //用n个字符c赋给当前字符串
string& assign(const string &s, int start, int n);//将s从start开始n个字符赋值给字 符串,start最小值是0
示例代码:
void test() {
const char *cstr = "beijing";
string str0 = cstr;
string str2(8, '8');
string str3(str0);
string str4, str5;
str4.assign("abcdef");
str4.assign("abcdef", 4); //abcd 把字符串s的前n个字符赋给当前的字符串
str5.assign(str4, 1, 2); //bc 将s从start开始n个字符赋值给字符串, bc
cout << str4 << endl;
cout << str5 << endl;
}
(3) 存取字符操作
char& operator[](int n); //通过[]方式取字符
char& at(int n); //通过at方法获取字符
//[] 和at区别?[]访问越界 直接挂掉 at会抛出异常
示例代码:
void test() {
string str0 = "ab cdef";
for (int i = 0; i < str0.size(); i++) {
//cout << str0[i] << endl;
cout << str0.at(i) << endl;
}
try {
//str0[10] = 'a';
str0.at(10) = 'a';
}
//catch (...) {
// cout << "yue jie yi chang" << endl;
//}
//使用系统提供的异常类 #include
catch (out_of_range &e){
cout << e.what() << endl;
}
}
(4) 拼接操作
string& operator+=(const string& str); //重载+=操作符
string& operator+=(const char* str); //重载+=操作符
string& operator+=(const char c); //重载+=操作符
string& append(const char *s); //把字符串s连接到当前字符串结尾
string& append(const char *s, int n); //把字符串s的前n个字符连接到当前字符串结尾
string& append(const string &s); //同operator+=()
string& append(const string &s, int pos, int n);//把字符串s中从pos开始的n个字符连 接到当前字符串结尾
string& append(int n, char c); //在当前字符串结尾添加n个字符c
示例代码:
void test() {
string str0 = "我爱";
string str1 = "北京";
string str3 = "12345";
str0 += str1;
str0 += '! ';
str0.append("我爱阜阳");
str0.append(3, '!');
str0.append(str3, 0, 3);
cout << str0 << endl;
}
(5) 查找和替换
int find(const string& str, int pos = 0) const; //查找str第一次出现位置,从pos开始查找
int find(const char* s, int pos = 0) const; //查找s第一次出现位置,从pos开始查找
int find(const char* s, int pos, int n) const; //从pos位置查找s的前n个字符第一次位置
int find(const char c, int pos = 0) const; //查找字符c第一次出现位置
int rfind(const string& str, int pos = npos) const; //查找str最后一次位置,从pos开始查找
int rfind(const char* s, int pos = npos) const; //查找s最后一次出现位置,从pos开始查找
int rfind(const char* s, int pos, int n) const; //从pos查找s的前n个字符最后一次位置
int rfind(const char c, int pos = 0) const; //查找字符c最后一次出现位置
string& replace(int pos, int n, const string& str); //替换从pos开始n个字符为字符串str
string& replace(int pos, int n, const char* s); //替换从pos开始的n个字符为字符串s
(6) 比较操作
compare函数在>时返回 1,<时返回 -1,==时返回 0。
比较区分大小写,比较时参考字典顺序,排越前面的越小。大写的A比小写的a小。
int compare(const string &s) const; //与字符串s比较
int compare(const char *s) const; //与字符串s比较
(7) string子串
string substr(int pos = 0, int n = npos) const; //返回由pos开始的n个字符组成的字符串
(8) 插入和删除操作
string& insert(int pos, const char* s); //插入字符串
string& insert(int pos, const string& str); //插入字符串
string& insert(int pos, int n, char c); //在指定位置插入n个字符c
string& erase(int pos, int n = npos); //删除从Pos开始的n个字符
示例代码:
void test()
{
string str0 = "ab dcde";
cout << str0.find("dc") << endl; //3
cout << str0.find(' ') << endl; //2
cout << (int)(str0.find("dd", 0, 2)) << endl; //找不到返回-1
cout << str0.rfind('b') << endl; //1
cout << str0.rfind('d') << endl; //5 不是3
cout << str0.compare("ab dcde") << endl; //相同返回0
cout << str0.substr(1, 3) << endl;
cout << str0.insert(1, "888") << endl;
cout << str0.erase(0, 3) << endl;
}
(9) string和c-style字符串转换
string str = "itcast";
const char* cstr = str.c_str(); //string 转 char*
char* s = "itcast";
string str(s); //char* 转 string
void test01(const char *) {}
void test02(string) {}
void test()
{
string str0 = "abdcde";
//test01(str0); //string 不能隐式类型转换为 char *
const char* p = str0.c_str();
test02(p); //const char * 隐式类型转换为 string
}
在c++中存在一个从const char*\到string的隐式类型转换,却不存在从一个string对象到C_string的自动类型转换。对于string类型的字符串,可以通过c_str()函数返回string对象对应的C_string.
通常,程序员在整个程序中应坚持使用string类对象,直到必须将内容转化为char*时才将其转换为C_string.
为了修改string字符串的内容,下标操作符[]和at都会返回字符的引用。但当字符串的内存被重新分配之后,可能发生错误.
void test()
{
string str0 = "abdcde";
char &c = str0.at(2), &d = str0[3];
c = '1'; d = '2';
cout << str0 << endl << (int *)(str0.c_str()) << endl;
str0 = "1234abdefe3646757868qweewqw"; //会重新分配地址
//c = '1';
cout << (int *)(str0.c_str()) << endl;
}
(10) 字符大小写转换toupper tolower
void test()
{
string str0 = "ab7dTa";
for (int i = 0; i < str0.size(); i++) {
//str0[i] = toupper(str0[i]); //转大写
str0[i] = tolower(str0[i]); //转小写
}
cout << str0 << endl;
}
3.2 vector容器
#include

1. vector容器基本概念
(1) vector迭代器是随机访问迭代器
vector维护一个线性空间,所以不论元素的型别如何,普通指针都可以作为vector的迭代器,因为vector迭代器所需要的操作行为,如operaroe*, operator->, operator++, operator–, operator+, operator-, operator+=, operator-=, 普通指针天生具备。Vector支持随机存取,而普通指针正有着这样的能力。所以vector提供的是随机访问迭代器(Random Access Iterators).
(2) vector动态增加大小
所谓动态增加大小,并不是在原空间之后续接新空间(因为无法保证原空间之后尚有可配置的空间),而是一块更大的内存空间,然后将原数据拷贝新空间,并释放原空间。因此,对vector的任何操作,一旦引起空间的重新配置,指向原vector的所有迭代器就都失效了。这是程序员容易犯的一个错误,务必小心。所以使用迭代器时,要注意这一点。迭代器最好在使用时进行赋值。
示例代码:
int main()
{
vectorv;
vector::iterator it = v.begin();
v.push_back(1);
v.push_back(2);
//it = v.begin();
cout << *it << endl;
cout << "Hello World";
return 0;
}
/usercode/script.sh: line 62: 13 Segmentation fault $output - < "/usercode/inputFile"
int main()
{
vectorv;
vector::iterator it;
v.push_back(1);
v.push_back(2);
it = v.begin();
cout << *it << endl;
v.reserve(40);
cout << *it << endl;
cout << "Hello World";
return 0;
}
1
19607552
Hello World
(3) vector中文翻译向量(有大小和方向)
2. vector容器常用操作
(1) 随机访问
void test()
{
vector v;
for (int i = 0; i < 10; i++) v.push_back(i);
vector::iterator it = v.begin();
it += 2; //如果这个写法不报错,这个迭代器是随机访问迭代器
*it = 888;
cout << "v[0]的地址 = " << (int*)(&v[0]) << endl;
cout << "v[1]的地址 = " << (int*)(&v[1]) << endl;
printVector(v);
}
(2) 构造函数
vector v; //采用模板实现类实现,默认构造函数
vector(v.begin(), v.end()); //将v[begin(), end())区间中的元素拷贝给本身。参数是地址。
vector(n, elem); //构造函数将n个elem拷贝给本身。
vector(const vector &vec); //拷贝构造函数。
//例子 使用第二个构造函数 我们可以…
int arr[] = {2,3,4,1,9};
vector v1(arr, arr + sizeof(arr) / sizeof(int));
(3) 常用赋值操作
assign(beg, end); //将[beg, end)区间中的数据拷贝赋值给本身。
assign(n, elem); //将n个elem拷贝赋值给本身。
vector& operator=(const vector &vec); //重载等号操作符
swap(vec); //将原先容器的capacity包含所有放入元素与vec互换。
(4) 大小操作
size(); //返回容器中元素的个数
empty(); //判断容器是否为空
resize(int num);
//重新指定容器size,如果新的size小于等于原先的capacity,capacity不变,反之capacity变大。
//若新的size变大,则以默认值填充size大于原先size部分,默认使用0,填充的这些位置可以访问。
//如果size变小,则末尾超出部分的元素被删除。
resize(int num, elem);
//重新新指定容器size, 若num大于原先的size,则超出部分以elem值填充新位置。反之,超出部分的元素被删除。
capacity(); //容器的容量
reserve(int len); //重新指定容器的capacity。未放入元素的位置不可访问。
//如果len>原先的capacity,reserver重新指定的capacity生效。原先放入的元素依旧存在
//如果reserve小于原先的capacity,reserve不生效。
示例代码:
void printVector(vector &v) {
for (vector::iterator it = v.begin(); it < v.end(); it++) {
cout << *it << " ";
}
cout << endl;
}
void test() {
int a[] = {1, 2, 3, 4, 5, 6, 7, 8, 9};
vector v(a, a + sizeof(a)/sizeof(int)); // 1 2 3 4 5 7 8 9
printVector(v);
cout << "v.size: " << v.size() << " v.capacity: " << v.capacity() << endl; //9 9
vector v2;
//v2.assign(a, a+2); // 1 2
v2.assign(v.begin(), v.begin()+2); //1 2
//v2.assign(3, 4); // 4 4 4
printVector(v2);
cout << "v2.size: " << v2.size() << " v2.capacity: " << v2.capacity() < // 开辟100000数据用了多少次
void test() {
vector v;
int *p = NULL, num = 0;
//v.reserve(100000); //容器预留len个元素长度,预留位置不初始化,元素不可访问。只开 //辟一次空间
if (v.empty())
cout << "v 为空" << endl;
for (int i = 0; i < 100000; i++) {
v.push_back(i); //必须先填充,才能访问
if (p != &v[0]) {
p = &v[0];
num++;
}
}
cout << "填入100000个数据开辟了" << num << "次空间" << endl; // 30次 1次
}
(5) 数据存取操作
at(int idx); //返回索引idx所指的数据,如果idx越界,抛出out_of_range异常。必须先使用push_back放入元素了,才能访问at []
operator[]; //返回索引idx所指的数据,越界时,运行直接报错
front(); //返回容器中第一个数据元素
back(); //返回容器中最后一个数据元素
(6) 插入和删除操作
insert(const_iterator pos, int count,ele);
//迭代器指向位置pos 插入count个元素ele. Count可以不填,插入一个
push_back(ele); //尾部插入元素ele
pop_back(); //删除最后一个元素
erase(const_iterator start, const_iterator end);//删除迭代器从start到end之间的元素
erase(const_iterator pos); //删除迭代器指向的元素
clear(); //删除容器中所有元素
示例代码:
void test()
{
vector v;
for (int i = 0; i < 10; i++) v.push_back(i);
cout << "第1个元素 :" << v.front() << endl;
cout << "第2个元素 :" << v[1] << endl;
cout << "第3个元素 :" << v.at(2) << endl;
cout << "最后1个元素:" << v.back() << endl;
v.insert(v.begin() + 1, 888); printVector(v);
v.pop_back(); printVector(v);
v.erase(v.begin(), v.begin() + 1); printVector(v);
v.erase(v.begin()); printVector(v);
v.clear(); printVector(v);
}
(7) 逆序遍历 reverse_iterator rbegin rend
void test()
{
vector v;
for (int i = 0; i < 10; i++) v.push_back(i);
for (vector::reverse_iterator it = v.rbegin(); it != v.rend(); it++)
cout << *it << endl;
}
(8) 巧用swap,收缩内存空间
void test()
{
vector v;
for (int i = 0; i < 100000; i++) v.push_back(i);
cout << "v的大小:" << v.size() << " v的容量" << v.capacity() << endl;
v.resize(10);
printVector(v);
cout << "v的大小:" << v.size() << " v的容量" << v.capacity() << endl;
//容量不发生变量,还是13万多
//vector(v) 用v初始化匿名对象,用v的有效数据来初始化,所以匿名对象的容量是10.
//然后调用swap交换指针,v这时的容量就变成了10.而匿名对象在这句之后就被释放了
vector(v).swap(v);
cout << "v的大小:" << v.size() << " v的容量" << v.capacity() << endl; // 10 10
}
(9) vector排序
//序列式容器可以使用系统提供的sort算法进行排序,关联式容器(list.map等)不能使用
bool myCompare(int a1, int a2) {
return (a1 > a2); //从大到小排
}
void test() {
int a[7] = {1, 8, 3, 15, 52, 23, 45};
vectorv;
v.assign(&a[0], &a[7]);
for (vector::iterator itin = v.begin(); itin != v.end(); itin++) {
cout << *itin << " ";
}
cout << endl;
sort(v.begin(), v.begin() + 4); //对前4个排序 sort默认是从小到大排序
//sort(v.begin(), v.end()); //对所有排序
for (vector::iterator itin = v.begin(); itin != v.end(); itin++) {
cout << *itin << " ";
}
cout << endl;
sort(v.begin(), v.end(), myCompare); //改为从大到小排序
for (vector::iterator itin = v.begin(); itin != v.end(); itin++) {
cout << *itin << " ";
}
}
3.3 deque容器
#include

1. deque容器基本概念
Vector容器是单向开口的连续内存空间,deque则是一种双向开口的连续线性空间。所谓的双向开口,意思是可以在头尾两端分别做元素的插入和删除操作,当然,vector容器也可以在头尾两端插入元素,但是在其头部操作效率奇差,无法被接受。
deque容器和vector容器最大的差异,一在于deque允许使用常数项时间对头端进行元素的插入和删除操作。二在于deque没有容量的概念,因为它是动态的以分段连续空间组合而成,随时可以增加一段新的空间并链接起来,换句话说,像vector那样,”旧空间不足而重新配置一块更大空间,然后复制元素,再释放旧空间”这样的事情在deque身上是不会发生的。也因此,deque没有必须要提供所谓的空间保留(reserve)功能.
虽然deque容器也提供了Random Access Iterator,但是它的迭代器并不是普通的指针,其复杂度和vector不是一个量级,这当然影响各个运算的层面。因此,除非有必要,我们应该尽可能的使用vector,而不是deque。对deque进行的排序操作,为了最高效率,可将deque先完整的复制到一个vector中,对vector容器进行排序,再复制回deque.
deque容器迭代器也是随机访问迭代器。deque容器也是序列式容器。
deque中文翻译:双端队列。
2. deque容器实现原理
deque容器是连续的空间,至少逻辑上看来如此,连续现行空间总是令我们联想到array和vector,array无法成长,vector虽可成长,却只能向尾端成长,而且其成长其实是一个假象,事实上
(1) 申请更大空间
(2) 原数据复制新空间
(3) 释放原空间
三步骤,如果不是vector每次配置新的空间时都留有余裕,其成长假象所带来的代价是非常昂贵的。
deque是由一段一段的定量的连续空间构成。一旦有必要在deque前端或者尾端增加新的空间,便配置一段连续定量的空间,串接在deque的头端或者尾端。deque最大的工作就是维护这些分段连续的内存空间的整体性的假象,并提供随机存取的接口,避开了重新配置空间,复制,释放的轮回,代价就是复杂的迭代器架构。
既然deque是分段连续内存空间,那么就必须有中央控制,维持整体连续的假象,数据结构的设计及迭代器的前进后退操作颇为繁琐。deque代码的实现远比vector或list都多得多。
deque采取一块所谓的map(注意,不是STL的map容器)作为主控,这里所谓的map是一小块连续的内存空间,其中每一个元素(此处成为一个结点)都是一个指针,指向另一段连续性内存空间,称作缓冲区。缓冲区才是deque的存储空间的主体。
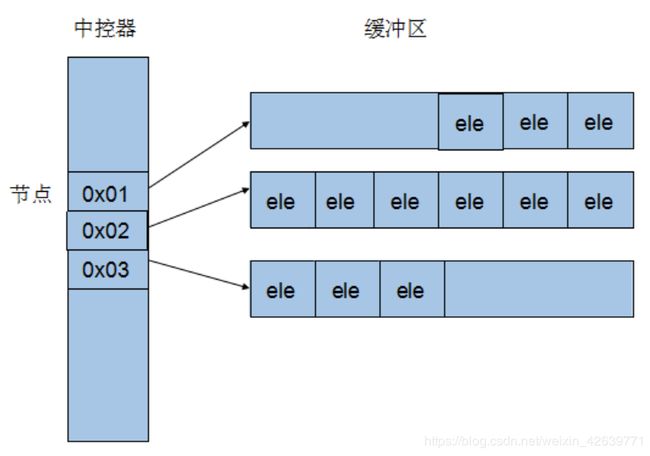
3 deque常用API
(1) deque构造函数
deque deqT; //默认构造形式
deque(beg, end); //构造函数将[beg, end)区间中的元素拷贝给本身。
deque(n, elem); //构造函数将n个elem拷贝给本身。
deque(const deque &deq);//拷贝构造函数。
(2) deque赋值操作
assign(beg, end); //将[beg, end)区间中的数据拷贝赋值给本身。
assign(n, elem); //将n个elem拷贝赋值给本身。
deque& operator=(const deque &deq); //重载等号操作符
swap(deq); // 将deq与本身的元素互换
(3) deque大小操作
deque.size(); //返回容器中元素的个数
deque.empty(); //判断容器是否为空
deque.resize(num); //重新指定容器的长度为num,若容器变长,则以默认值填充新位置。如果容器变短,
则末尾超出容器长度的元素被删除。
deque.resize(num, elem); //重新指定容器的长度为num,若容器变长,则以elem值填充新位置,如果容器变短,
则末尾超出容器长度的元素被删除。
(4) deque双端插入和删除操作
push_back(elem); //在容器尾部添加一个数据
push_front(elem); //在容器头部插入一个数据
pop_back(); //删除容器最后一个数据
pop_front(); //删除容器第一个数据
(5) deque数据存取
at(idx); //返回索引idx所指的数据,如果idx越界,抛出out_of_range。
operator[]; //返回索引idx所指的数据,如果idx越界,不抛出异常,直接出错。
front(); //返回第一个数据。
back(); //返回最后一个数据
示例代码:
void printDeque(deque &v) {
for (deque::iterator it = v.begin(); it < v.end(); it++) {
cout << *it << " ";
}
cout << endl;
}
void test()
{
deque deq;
int a[3] = {1, 22, 31};
deq.assign(a, a + sizeof(a)/sizeof(int));
printDeque(deq);
deq.push_back(80); printDeque(deq);
deq.push_front(28); printDeque(deq);
cout << "deq的大小:" << deq.size() << endl;
deq.pop_back(); printDeque(deq); cout << "deq的大小:" << deq.size() << endl;
deq.pop_front(); printDeque(deq); cout << "deq的大小:" << deq.size() << endl;
deq.resize(2); printDeque(deq);
deq.resize(5); printDeque(deq);
cout << "deq第1个元素:" << deq.front() << endl;
cout << "deq第2个元素:" << deq.at(1) << endl;
cout << "deq第3个元素:" << deq[2] << endl;
cout << "deq最后1个元素:" << deq.back() << endl;
}
(6) deque插入操作
insert(pos,elem); //在pos位置插入一个elem元素的拷贝,返回新数据的位置。
insert(pos,n,elem); //在pos位置插入n个elem数据,无返回值。
insert(pos,beg,end);//在pos位置插入[beg,end)区间的数据,无返回值。
(7) deque删除操作
clear(); //移除容器的所有数据
erase(beg,end); //删除[beg,end)区间的数据,返回下一个数据的位置。删除元素的个数等于end-beg
erase(pos); //删除pos位置的数据,返回下一个数据的位置。
示例代码:
//deque容器支持随机访问
void test()
{
deque deq;
//deque::iterator pos = deq.begin(); //迭代器不能先指定,在使用时赋值
deq.push_back(80); deq.push_front(28); printDeque(deq); //28 80
deque::iterator pos = deq.begin();
pos += 2; deq.insert(pos, 10); printDeque(deq); //28 80 10
deq.erase(deq.begin()+=1);printDeque(deq); //28 10
}
(8) 只读迭代器const_iterator 逆序迭代器reverse_iterator
void printDeque(const deque &v) {
for (deque::const_iterator it = v.begin(); it < v.end(); it++) {
cout << *it << " ";
}
cout << endl;
}
void test() {
dequedeq;
deq.push_back(12); deq.push_back(1); deq.push_back(9);
printDeque(deq);
for (deque::reverse_iterator it = deq.rbegin(); it != deq.rend(); it++) {
cout << *it << " ";
}
}
(9) deque排序
deque与vector同是序列式容器,所以可以用系统的sort算法进行排序,排序方法完全一致。
bool myCompare(int a1, int a2) {
return (a1 > a2);
}
void test() {
deque deq;
int a[7] = {1, 8, 3, 15, 52, 23, 45};
deq.assign(&a[0], &a[sizeof(a)/sizeof(int) - 1]); printDeque(deq);
sort(deq.begin(), deq.begin() + 4); printDeque(deq);
sort(deq.begin(), deq.end(), myCompare); printDeque(deq); //改为从大到小排序
}
(10) 作业案例,评委打分
测试发现,在需要产生随机数的地方,只需要产生一个随机种子就行了,如果调用多次srand,产生的随机数会重复。
产生随机数
//错误用法1
int main()
{
int i, j;
int defen;
for(i = 0; i < 2; i++)
{
srand(time(NULL));
for(j =0; j < 3; j++) {
defen = rand() % 100;
cout << defen << endl;
}
cout << "------" << endl;
}
return 0;
}
3
43
56
------
3
43
56
------
//错误用法2
for(i = 0; i < 2; i++)
{
for(j =0; j < 3; j++) {
srand(time(NULL));
defen = rand() % 100;
cout << defen << endl;
}
cout << "------" << endl;
}
71
71
71
------
71
71
71
//正确用法
srand(time(NULL));
for(i = 0; i < 2; i++)
{
for(j =0; j < 3; j++) {
defen = rand() % 100;
cout << defen << endl;
}
cout << "------" << endl;
}
24
57
84
------
96
73
68
打分案例
void test() {
vectorv;
string name = "选手"; string xuhao = "abcd";
for (int i = 0; i < xuhao.size(); i++) {
string m_name = name + xuhao[i];
person p(m_name); v.push_back(p);
}
srand((unsigned int)time(NULL)); //调用一次srand就行了,不能在下面的循环里调用
for (vector::iterator it = v.begin(); it != v.end(); it++)
{
dequedeq; int score;
for (int i = 0; i < 5; i++) {
score = rand() % 41 + 60;
deq.push_back(score);
}
sort(deq.begin(), deq.end());
cout << "5位评委的打分分别都是:";
for (deque::iterator it = deq.begin(); it != deq.end(); it++) {
cout << *it << " ";
}
cout << endl;
deq.pop_front();
deq.pop_back();
int sumScore = 0;
for (deque::iterator it = deq.begin(); it != deq.end(); it++) {
sumScore += *it;
}
it->score = sumScore/deq.size();
cout<<"姓名:"<name<<" 得分:"<score< 3.4 stack容器
#include
stack中文意思:栈
1 stack容器基本概念
stack是一种先进后出(First In Last Out,FILO)的数据结构,它只有一个出口,形式如图所示。stack容器允许新增元素,移除元素(从栈顶弹出),取得栈顶元素(只能取得栈顶元素),但是除了最顶端外,没有任何其他方法可以存取stack的其他元素。换言之,stack不允许有遍历行为。
有元素推入栈的操作称为:push,将元素推出stack的操作称为pop.
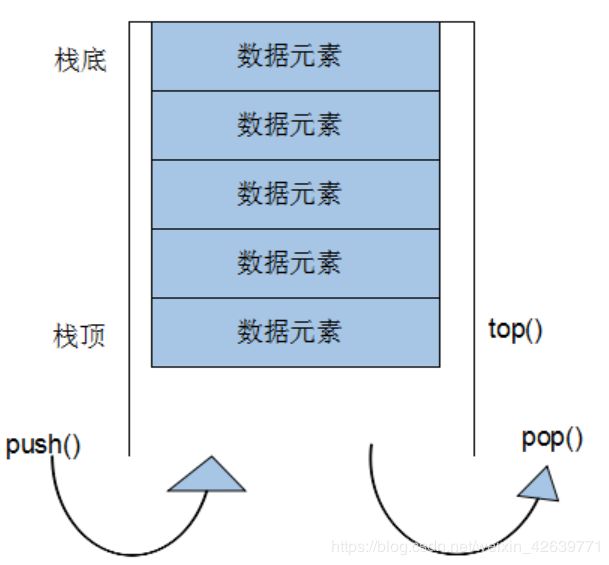

2 stack没有迭代器
Stack所有元素的进出都必须符合”先进后出”的条件,只有stack顶端的元素,才有机会被外界取用。Stack不提供遍历功能,也不提供迭代器。
3 stack常用API
(1) 构造函数
stack stkT; //stack采用模板类实现, stack对象的默认构造形式:
stack(const stack &stk); //拷贝构造函数
(2) 赋值操作
stack& operator=(const stack &stk); //重载等号操作符
(3) stack数据存取操作
push(elem); //向栈顶添加元素
pop(); //从栈顶移除第一个元素
top(); //返回栈顶元素
(4) stack大小操作
empty(); //判断堆栈是否为空
size(); //返回堆栈的大小
示例代码:
void test()
{
stackst, st2;
st.push(12);
st.push(13);
cout << "st的大小" << st.size() << endl;
st2 = st;
while (!st2.empty()) {
cout << "st栈顶元素:" << st2.top() << endl;
st2.pop();
}
}
3.5 queue容器
#include
queue中文翻译:队列
1 queue容器基本概念
Queue是一种先进先出(First In First Out,FIFO)的数据结构,它有两个出口,queue容器允许从一端新增元素,从另一端移除元素。
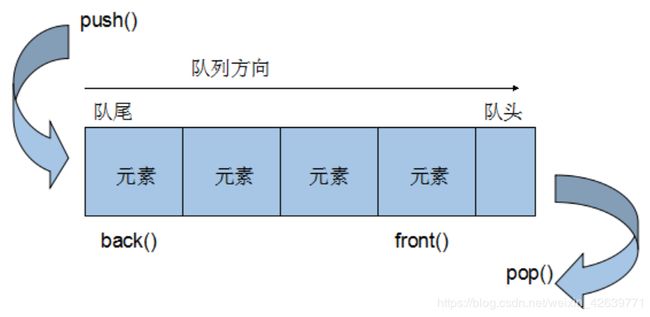
2. queue没有迭代器
Queue所有元素的进出都必须符合”先进先出”的条件,只有queue的顶端元素,才有机会被外界取用。Queue不提供遍历功能,也不提供迭代器。
3. queue常用API
(1) 构造函数
queue queT; //queue采用模板类实现,queue对象的默认构造形式:
queue(const queue &que);//拷贝构造函数
(2) 存取、插入和删除操作
push(elem); //往队尾添加元素
pop(); //从队头移除第一个元素
back(); //返回最后一个元素
front(); //返回第一个元素
(3) 赋值操作
queue& operator=(const queue &que);//重载等号操作符
(4) 大小操作
empty(); //判断队列是否为空
size(); //返回队列的大小
示例代码:
void test()
{
queueqe, qe2;
qe.push(12);
qe.push(13);
cout << "qe的大小" << qe.size() << endl;
cout << "qw队头元素:" << qe.front() << endl;
cout << "qw队尾元素:" << qe.back() << endl;
qe2 = qe;
while (!qe2.empty()) {
cout << "qw队头元素:" << qe2.front() << endl;
qe2.pop();
}
}
3.6 list容器
#include
list:链表,这里是双向链表
1. list容器基本概念
链表是一种物理存储单元上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的。链表由一系列结点(链表中每一个元素称为结点)组成,结点可以在运行时动态生成。每个结点包括两个部分:一个是存储数据元素的数据域,另一个是存储下一个结点地址的指针域。
相较于vector的连续线性空间,list就显得负责许多,它的好处是每次插入或者删除一个元素,就是配置或者释放一个元素的空间。因此,list对于空间的运用有绝对的精准,一点也不浪费。而且,对于任何位置的元素插入或元素的移除,list永远是常数时间。
list和vector是两个最常被使用的容器。
list容器是一个双向链表。
 采用动态存储分配,不会造成内存浪费和溢出
采用动态存储分配,不会造成内存浪费和溢出
链表执行插入和删除操作十分方便,修改指针即可,不需要移动大量元素
链表灵活,但是空间和时间额外耗费较大
2. list容器的迭代器
list容器不能像vector一样以普通指针作为迭代器,因为其节点不能保证在同一块连续的内存空间上。List迭代器必须有能力指向list的节点,并有能力进行正确的递增、递减、取值、成员存取操作。所谓”list正确的递增,递减、取值、成员取用”是指,递增时指向下一个节点,递减时指向上一个节点,取值时取的是节点的数据值,成员取用时取的是节点的成员。
由于list是一个双向链表,迭代器必须能够具备前移、后移的能力,所以list容器提供的是Bidirectional Iterators.
list有一个重要的性质,插入操作和删除操作都不会造成原有list迭代器的失效。这在vector是不成立的,因为vector的插入操作可能造成记忆体重新配置,导致原有的迭代器全部失效,甚至List元素的删除,也只有被删除的那个元素的迭代器失效,其他迭代器不受任何影响。
list容器的迭代器不是随机访问迭代器,所以不能使用at []随机访问容器中的元素,不能迭代器+=运算(list::iterator it; it += x),可以使用++运算,最好是前置++。
int main()
{
listlst;
lst.push_back(12);
lst.push_back(13);
lst.push_back(7);
lst.insert((lst.begin()+1), 31);
//lst.resize(2);
printlist(lst);
}
/usercode/file.cpp: In function ‘int main()’:
/usercode/file.cpp:36:28: error: no match for ‘operator+’ (operand types are ‘std::list::iterator {aka std::_List_iterator}’ and ‘int’)
lst.insert((lst.begin()+1), 31);
int main()
{
listlst;
lst.push_back(12);
lst.push_back(13);
lst.push_back(7);
lst.insert(++++lst.begin(), 31);
//lst.resize(2);
printlist(lst);
}
12
13
31
7
3. list容器的数据结构
list容器不仅是一个双向链表,而且还是一个循环的双向链表。
示例代码:
//list是双向循环链表
void test()
{
list myList;
listmylist;
for (int i = 0; i < 10; i++) {
mylist.push_back(i);
}
list::_Nodeptr node = mylist._Myhead->_Next;
for (int i = 0; i < mylist._Mysize * 2; i++) {
cout << "Node:" << node->_Myval << endl;
node = node->_Next;
if (node == mylist._Myhead) {
node = node->_Next;
}
}
}
4 list常用API
(1) 构造函数
list lstT; //list采用采用模板类实现,对象的默认构造形式:
list(beg,end); //构造函数将[beg, end)区间中的元素拷贝给本身。
list(n,elem); //构造函数将n个elem拷贝给本身。
list(const list &lst);//拷贝构造函数。
(2) 数据元素插入和删除操作
push_back(elem); //在容器尾部加入一个元素
pop_back(); //删除容器中最后一个元素
push_front(elem); //在容器开头插入一个元素
pop_front(); //从容器开头移除第一个元素
insert(pos,elem); //在pos位置插elem元素的拷贝,返回新数据的位置。
insert(pos,n,elem); //在pos位置插入n个elem数据,无返回值。
insert(pos,beg,end);//在pos位置插入[beg,end)区间的数据,无返回值。
clear(); //移除容器的所有数据
erase(beg,end); //删除[beg,end)区间的数据,返回下一个数据的位置。
erase(pos); //删除pos位置的数据,返回下一个数据的位置。
remove(elem); //删除容器中所有与elem值匹配的元素。
(3) list大小操作
size(); //返回容器中元素的个数
empty(); //判断容器是否为空
resize(num); //重新指定容器的长度为num,若容器变长,则以默认值填充新位置。
如果容器变短,则末尾超出容器长度的元素被删除。
resize(num, elem); //重新指定容器的长度为num,若容器变长,则以elem值填充新位置。
如果容器变短,则末尾超出容器长度的元素被删除。
(4) list赋值操作
assign(beg, end); //将[beg, end)区间中的数据拷贝赋值给本身。
assign(n, elem); //将n个elem拷贝赋值给本身。
list& operator=(const list &lst);//重载等号操作符
swap(lst); //将lst与本身的元素互换。
(5) list数据的存取
front(); //返回第一个元素。
back(); //返回最后一个元素。
(6) list反转排序
reverse(); //反转链表,比如lst包含1,3,5元素,运行此方法后,lst就包含5,3,1元素。
sort(); //list排序不能使用algorithem的sort,因为list不支持随机访问,
这里使用的是list类提供的sort方法 所有不支持随机访问的迭代器 不可以用系统提供的算法,
如果不支持用系统提供算法,那么这个类内部会提供
示例代码1:
void printList(const list&lis) {
for (list::const_iterator it = lis.begin(); it != lis.end(); it++) {
cout << *it << " ";
}
cout << endl;
}
bool myCompare(int a, int b)
{
return (a > b);
}
//list是双向循环链表
void test()
{
int a[4] = {1, 23, 12, 23};
listmylist(a, a+4); printList(mylist);
mylist.push_front(33); mylist.push_back(666); printList(mylist);
mylist.pop_front(); mylist.pop_back(); printList(mylist);
//mylist.insert(mylist.begin()+2, 3); //不支持随机访问
mylist.insert(mylist.begin(), 3); printList(mylist);
mylist.erase(mylist.begin()); printList(mylist);
mylist.remove(23); printList(mylist);
mylist.resize(10, 888); printList(mylist);
//逆序迭代器
for (list::reverse_iterator it = mylist.rbegin(); it != mylist.rend(); it ++) {
cout << *it << " ";
}
cout << endl;
cout << "第1个元素" << mylist.front() << endl;
cout << "最后第1个元素" << mylist.back() << endl;
//reverse();//反转链表,比如lst包含1,3,5元素,运行此方法后,lst就包含5,3,1元素。
mylist.reverse(); printList(mylist);
//sort(); //list排序
mylist.sort(); printList(mylist); //默认从小到大
mylist.sort(myCompare); printList(mylist); //回调,从大到小
}
示例代码2:
class person
{
public:
person(string m_name ,int m_age):name(m_name),age(m_age) {}
bool operator==(const person &p) { //const必不可少
if ((this->name == p.name) && (this->age == p.age))
return true;
return false;
}
string name;
int age;
};
bool myCompare(person &p1, person &p2)
{
return (p1.age < p2.age);
}
//list是双向循环链表
void test() {
listmylist;
person p1("小王", 17), p2("小刘", 20), p3("小赵", 16);
mylist.push_back(p1); mylist.push_back(p2); mylist.push_back(p3);
mylist.sort(myCompare); //回调函数
for (list::iterator it = mylist.begin(); it != mylist.end(); it++) {
cout << "姓名:" << it->name << " 年龄:" << it->age << endl;
}
mylist.remove(p2); //重载==
for (list::iterator it = mylist.begin(); it != mylist.end(); it++) {
cout << "姓名:" << it->name << " 年龄:" << it->age << endl;
}
}
3.7 set/multiset容器
#include
1. set/multiset容器基本概念
set的特性是:所有元素都会根据元素的键值自动被排序。Set的元素不像map那样可以同时拥有实值和键值,set的元素即是键值又是实值。Set不允许两个元素有相同的键值。
我们可以通过set的迭代器改变set元素的值吗?不行,因为set元素值就是其键值,关系到set元素的排序规则。如果任意改变set元素值,会严重破坏set组织。换句话说,set的iterator是一种const_iterator.
set拥有和list某些相同的性质,当对容器中的元素进行插入操作或者删除操作的时候,操作之前所有的迭代器,在操作完成之后依然有效,被删除的那个元素的迭代器必然是一个例外。
multiset特性及用法和set完全相同,唯一的差别在于它允许键值重复。set和multiset的底层实现是红黑树,红黑树为平衡二叉树的一种。
树的简单知识:
二叉树就是任何节点最多只允许有两个字节点。分别是左子结点和右子节点。
 二叉树示意图
二叉树示意图
二叉搜索树,是指二叉树中的节点按照一定的规则进行排序,使得对二叉树中元素访问更加高效。二叉搜索树的放置规则是:任何节点的元素值一定大于其左子树中的每一个节点的元素值,并且小于其右子树的值。因此从根节点一直向左走,一直到无路可走,即得到最小值,一直向右走,直至无路可走,可得到最大值。那么在儿茶搜索树中找到最大元素和最小元素是非常简单的事情。下图为二叉搜索树:

上面我们介绍了二叉搜索树,那么当一个二叉搜索树的左子树和右子树不平衡的时候,那么搜索依据上图表示,搜索9所花费的时间要比搜索17所花费的时间要多,由于我们的输入或者经过我们插入或者删除操作,二叉树失去平衡,造成搜索效率降低。
所以我们有了一个平衡二叉树的概念,所谓的平衡不是指的完全平衡。
 RB-tree(红黑树)为二叉树的一种。
RB-tree(红黑树)为二叉树的一种。
2. set常用API
(1) set构造函数
set st; //set默认构造函数:
mulitset mst; //multiset默认构造函数:
set(const set &st);//拷贝构造函数
(2) set赋值操作
set& operator=(const set &st);//重载等号操作符
swap(st); //交换两个集合容器
(3) set大小操作
size();//返回容器中元素的数目
empty();//判断容器是否为空
(4) set插入和删除操作
insert(elem); //在容器中插入元素。
clear(); //清除所有元素
erase(pos); //删除pos迭代器所指的元素,返回下一个元素的迭代器。
erase(beg, end);//删除区间[beg,end)的所有元素 ,返回下一个元素的迭代器。
erase(elem); //删除容器中值为elem的元素。
(5) set查找操作
find(key); //查找键key是否存在,若存在,返回该键的元素的迭代器;若不存在,返回set.end();
count(key); //查找键key的元素个数 0或1 set容器不能有重复的key
lower_bound(keyElem); //返回第一个key >= keyElem元素的迭代器。
upper_bound(keyElem); //返回第一个key > keyElem元素的迭代器。
equal_range(keyElem);
//返回容器中key与keyElem相等的上下限的两个迭代器。上下限就是lower_bound和upper_bound
//两个迭代器返回第一个first是lower_bound,第二个是upper_bound
示例代码:
void printSet(const set&myset) {
for (set::iterator it = myset.begin(); it != myset.end(); it++) {
cout << *it << " "; //set容器里面的值不允许通过迭代器修改,iterator实际上就是 //const_iterator
}
cout << endl;
}
//list是双向循环链表
void test() {
setmyset;
myset.insert(10); myset.insert(21); myset.insert(20); myset.insert(21);
myset.insert(7); myset.insert(13);
printSet(myset); //7 10 13 20 21 二叉树,自动排序
cout << "20的个数为:" << myset.count(10) << endl; //1
cout << "15的个数为:" << myset.count(15) << endl; //0
int a = 20;
if (myset.find(a) != myset.end()) {
cout << a << "在容器中" << endl;
}
myset.erase(20); //删除值为20的元素
printSet(myset); //7 10 13 21
//lower_bound(keyElem);//返回第一个key>=keyElem元素的迭代器。
set::iterator pos = myset.lower_bound(13); //13
if (pos != myset.end()) {
cout << "找到了>=13的数:" << *pos << endl;
}
pos = myset.upper_bound(13);
if (pos != myset.end()) {
cout << "找到了>13的数:" << *pos << endl; //21
}
//equal_range(keyElem);//返回容器中key与keyElem相等的上下限的两个迭代器。
//上下限 就是lower_bound upper_bound
pair::iterator, set::iterator> ret = myset.equal_range(13);
if (ret.first != myset.end()) {
cout << "找到了>=13的数:" << *(ret.first) << endl;
}
if (ret.second != myset.end()) {
cout << "找到了>13的数:" << *(ret.second) << endl;
}
}
(6) set的insert返回值,指定set排序规则
示例代码1:set容器不允许插入重复的键值
void test() {
setmyset;
pair::iterator, bool> ret; //set的inset返回值pair对组
ret = myset.insert(20);
if (ret.second) {
cout << "插入成功" << endl; //成功
} else {
cout << "插入失败" << endl;
}
ret = myset.insert(20);
if (ret.second) {
cout << "插入成功" << endl;
} else {
cout << "插入失败" << endl; //失败
}
}
示例代码2:指定set排序规则,构造时就指定,采用仿函数。这时候set的类型就变了,如果需要类型,或者迭代器,也需要修改,带上仿函数。
class myCompare
{
public:
bool operator()(int a, int b) {
return a > b;
}
};
void printSet(const set&myset) { //set的类型已经变了,迭代器必须一样
for (set::iterator it = myset.begin(); it != myset.end(); it++) {
cout << *it << " ";
}
cout << endl;
}
void test() {
setmyset;
myset.insert(5); myset.insert(21); myset.insert(15);
printSet(myset); //从大到小
}
示例代码3:插入自定义数据类型,构造时就要指定排序规则
class person
{
public:
person(string m_name, int m_age):name(m_name), age(m_age) {}
string name;
int age;
};
class myCompare
{
public:
bool operator()(const person &p1, const person &p2) {
return p1.age > p2.age;
}
};
void test() {
setmyset;
person p1("xiao hong", 17), p2("xiao liang", 15), p3("xiao gang", 15);
myset.insert(p1); myset.insert(p2);
pair::iterator, bool>ret;
ret = myset.insert(p3);
if (ret.second) { //插入失败,不允许插入键值相同的
cout << "插入成功" << endl;
} else {
cout << "插入失败" << endl;
}
for (set::iterator it = myset.begin(); it != myset.end(); it++) {
cout << it->name << " 年龄:" << it->age << endl;
}
}
(7) multiset的使用
multiset可以插入键值相同的,insert的返回值是迭代器,跟set不一样
class person
{
public:
person(string m_name, int m_age):name(m_name), age(m_age) {}
string name;
int age;
};
class myCompare
{
public:
bool operator()(const person &p1, const person &p2) {
return p1.age > p2.age;
}
};
void test() {
multisetmyset;
person p1("xiao hong", 17), p2("xiao liang", 15), p3("xiao gang", 15);
myset.insert(p1); myset.insert(p2); myset.insert(p3);
for (multiset::iterator it = myset.begin(); it != myset.end(); it++) {
cout << it->name << " 年龄:" << it->age << endl;
}
multiset::iterator pos = myset.find(p3);
if (pos != myset.end()) {
cout << "p3 在容器中" << endl;
}
}
3.8 对组(pair)
对组(pair)将一对值组合成一个值,这一对值可以具有不同的数据类型,两个值可以分别用pair的两个公有属性first和second访问。
使用pair不需要包含头文件。
类模板:template
如何创建对组?
//第一种方法创建一个对组
pair pair1(string("name"), 20);
cout << pair1.first << endl; //访问pair第一个值
cout << pair1.second << endl;//访问pair第二个值
//第二种
pair pair2 = make_pair("name", 30);
cout << pair2.first << endl;
cout << pair2.second << endl;
//pair=赋值
pair pair3 = pair2;
示例代码:
void test() {
pairmypair("xiao liang", 18);
cout << mypair.first << endl;
cout << mypair.second << endl;
pairmypair2 = make_pair("xiao hong", 20);
cout << mypair2.first << endl;
cout << mypair2.second << endl;
pairmypair3 = mypair2;
cout << mypair3.first << endl;
cout << mypair3.second << endl;
}
3.8 map/multimap容器
1. map/multimap基本概念
Map的特性是,所有元素都会根据元素的键值自动排序(类似set)。Map所有的元素都是pair,同时拥有实值和键值,pair的第一元素被视为键值,第二元素被视为实值,map不允许两个元素有相同的键值。
我们可以通过map的迭代器改变map的键值吗?答案是不行,因为map的键值关系到map元素的排列规则,任意改变map键值将会严重破坏map组织。如果想要修改元素的实值,那么是可以的。
Map和list拥有相同的某些性质,当对它的容器元素进行新增操作或者删除操作时,操作之前的所有迭代器,在操作完成之后依然有效,当然被删除的那个元素的迭代器必然是个例外。
Multimap和map的操作类似,唯一区别multimap键值可重复。
Map和multimap都是以红黑树为底层实现机制。
2. map/multimap常用API
#include
map mapTT; //map默认构造函数:
map(const map &mp); //拷贝构造函数
(2) map赋值操作
map& operator=(const map &mp);//重载等号操作符
swap(mp); //交换两个集合容器
(3) map大小操作
size(); //返回容器中元素的数目
empty(); //判断容器是否为空
(4) map插入数据元素操作
map.insert(...); //往容器插入元素,返回pair
map mapStu;
// 第一种 通过pair的方式插入对象
mapStu.insert(pair(3, "小张"));
// 第二种 通过pair的方式插入对象
mapStu.insert(make_pair(-1, "校长"));
// 第三种 通过value_type的方式插入对象
mapStu.insert(map::value_type(1, "小李"));
// 第四种 通过数组的方式插入值
mapStu[3] = "小刘";
mapStu[5] = "小王";
(5) map删除操作
clear(); //删除所有元素
erase(pos); //删除pos迭代器所指的元素,返回下一个元素的迭代器。
erase(beg,end);//删除区间[beg,end)的所有元素 ,返回下一个元素的迭代器。
erase(keyElem);//删除容器中key为keyElem的对组。
(6) map查找操作
find(key); //查找键key是否存在,若存在,返回该键的元素的迭代器;/若不存在,返回map.end();
count(keyElem);
//返回容器中key为keyElem的对组个数。对map来说,要么是0,要么是1。对multimap来说,值可能大于1。
lower_bound(keyElem);//返回第一个key>=keyElem元素的迭代器。
upper_bound(keyElem);//返回第一个key>keyElem元素的迭代器。
equal_range(keyElem);//返回容器中key与keyElem相等的上下限的两个迭代器。
示例代码1:
void test()
{
mapmymap;
//第一种方式
mymap.insert(pair(1, 14));
//第二种方式
mymap.insert(make_pair(2, 23));
//第三种方式
mymap.insert(map::value_type(3, 14));
//第四种[],有风险 如果保证key存在 ,那么可以通过[]访问
//如果key原来不存在,使用[]的方式访问时,编译器会添加这样一个key,值为0
mymap[4] = 33;
map::iterator pos = mymap.find(2);
if (pos != mymap.end()) {
cout << "键值为2 实值为:" << pos->second << endl;
}
//键值8原来不存在,直接访问,编译器会插入一个键值为8 实值为0
cout << "键值为8 实值为:" << mymap[8] << endl;
cout << "键值为1 实值为:" << mymap[1] << endl;
for (map::iterator it = mymap.begin(); it != mymap.end(); it++) {
cout << "键值为:" << it->first << " 实值为:" << it->second << endl;
}
mymap.erase(mymap.begin()); //删除键值最小的那个
mymap.erase(4); //删除键值为4的
for (map::iterator it = mymap.begin(); it != mymap.end(); it++) {
cout << "键值为:" << it->first << " 实值为:" << it->second << endl;
}
}
示例代码2:指定排序规则
class myCompare
{
public:
bool operator()(int a1, int a2) {
return a1 > a2;
}
};
void test() {
mapmymap; //键值从大到小排序
mymap.insert(pair(1, 14));
mymap.insert(make_pair(2, 23));
mymap.insert(map::value_type(3, 14));
mymap[4] = 33;
for (map::iterator it = mymap.begin(); it != mymap.end(); it++) {
cout << "键值为:" << it->first << " 实值为:" << it->second << endl;
}
}
(7) multimap案例:员工分部门
//公司今天招聘了5个员工,5名员工进入公司之后,需要指派员工在那个部门工作
//人员信息有: 姓名 年龄 电话 工资等组成
//通过Multimap进行信息的插入 保存 显示
//分部门显示员工信息 显示全部员工信息
multimap因为键值可以重复,所以不支持map[3] = "abc"这种操作
class person
{
public:
person(string m_name, int m_age, int m_salary): name(m_name), age(m_age), salary(m_salary){}
string name;
int age, salary;
};
void createWorker(vector&v)
{
string baseName = "员工";
string baseNum = "ABCDE";
for (int i = 0; i < baseNum.size(); i++) {
string name = baseName + baseNum[i];
int salary = rand()%10001 + 10000;
int age = rand()%21 + 20;
person p(name, age, salary);
v.push_back(p);
}
}
void fenbumen(multimap &mymap, vector &v)
{
for (vector::iterator it = v.begin(); it != v.end(); it++) {
int depar = rand()%3;
cout << "部门:" << depar << " " << it->name << " 年龄:" << it->age << " 工资:" << it->salary << endl;
mymap.insert(make_pair(depar, *it));
}
}
enum
{
YANFA,
SHICHANGK,
XIAOSHOU
};
void showinfo(multimap &mymap) {
int count = mymap.count(YANFA), index = 0;
multimap::iterator it = mymap.find(YANFA);
cout << "研发--------------------" << endl;
for(; it != mymap.end(), index < count; it++, index++) {
cout << it->second.name << " 年龄:" << it->second.age << " 工资:" << it->second.salary << endl;
}
count = mymap.count(SHICHANGK); index = 0;
it = mymap.find(SHICHANGK);
cout << "市场--------------------" << endl;
for(; it != mymap.end(), index < count; it++, index++) {
cout << it->second.name << " 年龄:" << it->second.age << " 工资:" << it->second.salary << endl;
}
count = mymap.count(XIAOSHOU); index = 0;
it = mymap.find(XIAOSHOU);
cout << "销售--------------------" << endl;
for(; it != mymap.end(), index < count; it++, index++) {
cout << it->second.name << " 年龄:" << it->second.age << " 工资:" << it->second.salary << endl;
}
}
void test() {
vectorv;
multimapmymap; //键值从大到小排序
srand((unsigned int)time(NULL));
createWorker(v);
fenbumen(mymap, v);
showinfo(mymap);
}
3.9 STL容器使用时机
vector deque list set multiset map multimap
典型内存结构 单端数组 双端数组 双向链表 二叉树 二叉树 二叉树 二叉树
可随机存取 是 是 否 否 否 对key而言:不是 否
元素搜寻速度 慢 慢 非常慢 快 快 对key而言:快 对key而言:快
元素安插移除 尾端 头尾两端 任何位置 - - - -
vector的使用场景:比如软件历史操作记录的存储,我们经常要查看历史记录,比如上一次的记录,上上次的记录,但却不会去删除记录,因为记录是事实的描述。
deque的使用场景:比如排队购票系统,对排队者的存储可以采用deque,支持头端的快速移除,尾端的快速添加。如果采用vector,则头端移除时,会移动大量的数据,速度慢。
vector与deque的比较:
一:vector.at()比deque.at()效率高,比如vector.at(0)是固定的,deque的开始位置却是不固定的。
二:如果有大量释放操作的话,vector花的时间更少,这跟二者的内部实现有关。
三:deque支持头部的快速插入与快速移除,这是deque的优点。
list的使用场景:比如公交车乘客的存储,随时可能有乘客下车,支持频繁的不确实位置元素的移除插入。
set的使用场景:比如对手机游戏的个人得分记录的存储,存储要求从高分到低分的顺序排列。
map的使用场景:比如按ID号存储十万个用户,想要快速要通过ID查找对应的用户。二叉树的查找效率,这时就体现出来了。如果是vector容器,最坏的情况下可能要遍历完整个容器才能找到该用户。