js学习笔记基础分享--正则表达式
语法:/正则表达式主体/修饰符(可选)
var a = /number/i解析:
/number/i 是一个正则表达式。
number 是一个正则表达式主体 (用于检索)。
i 是一个修饰符 (搜索不区分大小写)。
使用字符串方法
//search() 方法 用于检索字符串中指定的子字符串,或检索与正则表达式相匹配的子字符串,并返回子串的起始位置。
var str = "Visit kjk!";
var n = str.search(/kjk/i);
console.log(n); //搜索字符串 "kjk", 并显示匹配的起始位置:6exec()
//exec()一次仅返回一个匹配结果
var str = 'AbC123abc456';
var reg1 = /abc/i; // 定义正则对象,i不分大小写,g全局匹配
var reg2 = /abc/g; // 定义正则对象,i不分大小写,g全局匹配
alert(reg1.exec(str)); //AbC
alert(reg2.exec(str)); //abcmatch()方法
//根据正则匹配出所有符合要求的内容,匹配成功后将其保存到数组中,匹配失败则返回null。
var str = "It's is the shorthand of it is";
var reg1 = /it/gi; //g表示全局匹配,用于在找到第一个匹配之后仍然继续查找。
console.log(str.match(reg1)); // 匹配结果:Array (2) ["It", "it"]
var reg2 = /^it/gi; //定位符“^”,可用于匹配字符串开始的位置。
console.log(str.match(reg2)); // 匹配结果:Array ["It"]
var reg3 = /s/gi;
console.log(str.match(reg3)); // 匹配结果:Array (4) ["s", "s", "s", "s"]
var reg4 = /s$/gi; //定位符“$”,可用于匹配字符串结尾的位置。
console.log(str.match(reg4)); // 匹配结果:Array ["s"]创建正则对象
//创建正则对象
var str = '^abc\\1.23*edf$';
var reg1 = /\.|\$|\*|\^|\\/gi; // 字面量方式创建正则对象
var reg2 = RegExp('\\.|\\$|\\*|\\^|\\\\', 'gi'); // 构造函数方式创建正则对象
console.log(str.match(reg1)); // 匹配结果:(5) ["^", "\", ".", "*", "$"]
console.log(str.match(reg2)); // 匹配结果:(5) ["^", "\", ".", "*", "$"]
//选择符“|”表示“或”,查找条件只要其中一个条件满足即可成立。
// JavaScript中字符串存在转义问题,因此代码中str里的“\\”表示反斜线“\”。
// 在正则中匹配特殊字符时,也需要反斜线(\)对特殊字符进行转义。例如,“\\\\”经过字符串转义后变成“\\”,然后正则表达式再用“\\”去匹配“\”。字符类别
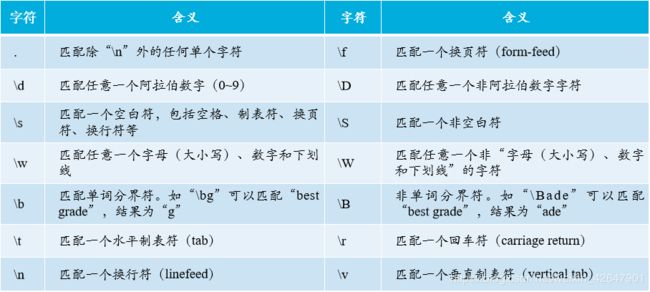
var str = 'good idea';
// 正则对象
var reg = /\s../gi;
// 匹配结果:[" id"]
console.log(str.match(reg));
//正则对象reg用于匹配空格符及空格符后的任意两个字符(除换行外)。
//在控制台查看到的结果中,id前有一个空格。字符集合的表示方式:“[]”可以实现一个字符集合。
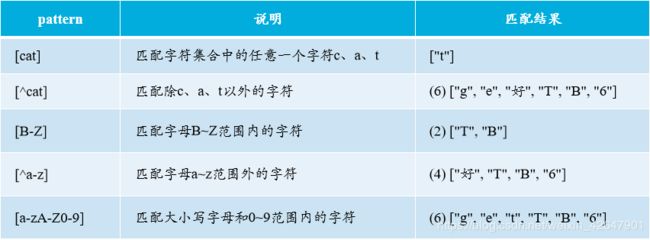
字符范围:与连字符“-”一起使用时,表示匹配指定范围内的字符。
反义字符:元字符“^”在“[]”内使用时,称为反义字符。
不在某范围内: “^”与“[]”一起使用,表示匹配不在指定字符范围内的字符。
案例:以字符串 'get好TB6'.match(/pattern/g) 为例演示其常见的用法。
字符限定
使用限定符(?、+、*、{ })完成某个字符连续出现的匹配。
如正则对象/\d{6}/gi。
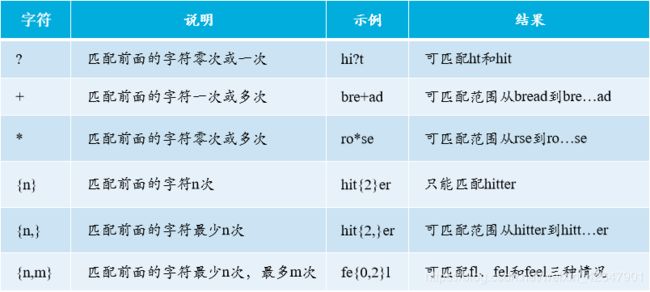
当点字符(.)和限定符连用时,可以实现匹配指定数量范围的任意字符。
举例:“^hello.*world$”。
说明:可匹配从hello开始到world结束,中间包含零个或多个任意字符的字符串。
正则在实现指定数量范围的任意字符匹配时,支持贪婪匹配和惰性匹配两种方式。
所谓贪婪表示匹配尽可能多的字符,而惰性表示匹配尽可能少的字符。在默认情况下,是贪婪匹配。
若想要实现惰性匹配,需在上一个限定符的后面加上“?”符号。
//正则在实现指定数量范围的任意字符匹配时,支持贪婪匹配和惰性匹配两种方式。
var str = 'webWEBWebwEb';
var reg1 = /w.*b/gi; // 贪婪匹配
var reg2 = /w.*?b/gi; // 惰性匹配
// 输出结果为:"webWEBWebwEb"
alert((reg1.exec(str)));
// 输出结果为:"web"
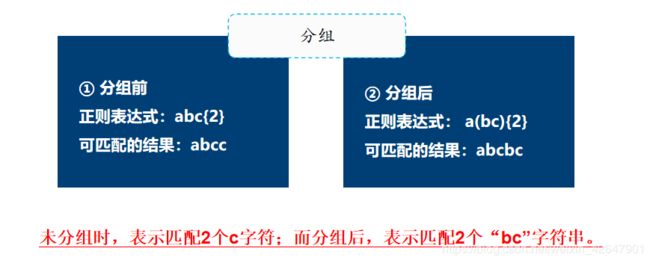
alert((reg2.exec(str)));括号字符
正则表达式中,被括号字符“()”括起来的内容,称之为“子表达式”
//括号字符
var str = "catcher";
var str1 = "vbjavascript javascript vbscript";
var str2 = "abcabcbc abcc abcbc bcbc bcc";
var reg1 = /catch|er/gi;
var reg2 = /cat(ch|er)/gi; // (a|b)表示a和b任选其一
var reg3 = /\b(VB|Java)Script\b/gi; //这个只是匹配VBScript和JavaScript
var reg4 = /\b(VB)?(Java)Script\b/gi; //这个不仅匹配VBScript和JavaScript,还匹配VBJavaScript
var reg5 = /abc{2}/gi;
var reg6 = /a(bc){2}/gi;
console.log(str.match(reg1)); //Array [ "catch" , "er" ]
console.log(str.match(reg2)); //Array [ "catch"]
console.log(str1.match(reg3)); //Array [ "javascript", "vbscript" ]
console.log(str1.match(reg4)); //Array [ "vbjavascript", "javascript" ]
console.log(str2.match(reg5));//Array [ "abcc" ]
console.log(str2.match(reg6));//Array [ "abcbc", "abcbc" ]
String类中的方法
(1)search()方法:可以返回指定模式的子串在字符串首次出现的位置,相对于indexOf()方法来说功能更强大。
var myString = "Beginning JavaScript,Beginning Java ";
var myRegExp = /\bJava\b/i;//\b匹配单词分界位置,即单词字符与非单词字符之间的位置
alert(myString.search(myRegExp)); //31search()方法的参数是一个正则对象,如果传入一个非正则表达式对象,则会使用“new RegExp(传入的参数)”隐式地将其转换为正则表达式对象。
search()方法可以在字符串中搜索字符模式,如果找到了该模式,则返回找到该模式的字符位置,否则返回-1。
(2)split()方法:用于根据指定的分隔符将一个字符串分割成字符串数组,其分割后的字符串数组中不包括分隔符。
当分隔符不只一个时,需要定义正则对象才能够完成字符串的分割操作。
var str = '[email protected]';
var reg = /[@\.]/;
var split_res = str.split(reg);
console.log(split_res);
//Array(3) [ "test", "123", "com" ]
// 按照字符串中的“@”和“.”两种分隔符进行分割。分割的位置
// split()方法的参数为正则表达式模式设置的分隔符,返回值是以数组形式保存的分割后的结果。
//当字符串为空时,split()方法返回的是一个包含一个空字符串的数组“[“”]”,如果字符串和分隔符都是空字符串,则返回一个空数组“[]”。
var str = 'We are a family';
var reg = /\s/; //匹配一个空格
var split_res = str.split(reg, 2); //分割2次
alert(split_res); //We,are
//在使用正则匹配方式分割字符串时,还可以指定字符串分割的次数。
//当指定字符串分割次数后,若指定的次数小于实际字符串中符合规则分割的次数,则最后的返回结果中会忽略其他的分割结果。表单验证:

练习:
现有一字符串“apple, 0.99, banana, 0.50, peach, 0.25, orange, 0.75”,结合正则表达式,通过split()方法拆分字符串,使结果只包含水果名称,而不包含价格,且每种水果各占一行。
var str = "apple, 0.99, banana, 0.50, peach, 0.25, orange, 0.75";
var reg = /[^a-z]+/i;//将不是字母的字符都截掉,剩下的就是想要的
var split_res = str.split(reg);
document.write(split_res.join(""));