python数据挖掘实战笔记——文本挖掘(5):词云美化之绘制《红楼梦》词云图
词云图的美化就是把词云图的背景和颜色进行美化,以《红楼梦》词云图为例,如下所示:


首先绘制词云,跟之前的代码操作一样:
import jieba
import numpy
import codecs
import pandas
#读取红楼梦文本
file = codecs.open(
r"C:\Users\www12\Desktop\data\2.5\红楼梦.txt", 'r', 'utf-8'
)
content = file.read()
file.close()
#导入专用词库
jieba.load_userdict(r'C:\Users\www12\Desktop\data\2.5\红楼梦词库.txt');
#分词
segments = []
segs = jieba.cut(content)
for seg in segs:
if len(seg.strip())>1:#去掉单字词
segments.append(seg);
#分词结果添加到数据框中
segmentDF = pandas.DataFrame({'segment':segments})
#移除停用词
stopwords = pandas.read_csv(
r"C:\Users\www12\Desktop\data\2.5\StopwordsCN.txt",
encoding='utf8',
index_col=False,
quoting=3,
sep="\t"
)
segmentDF = segmentDF[
~segmentDF.segment.isin(stopwords.stopword)
]
#移除无效词
wyStopWords = pandas.Series([
# 42 个文言虚词
'之', '其', '或', '亦', '方', '于', '即', '皆', '因', '仍', '故',
'尚', '呢', '了', '的', '着', '一', '不', '乃', '呀', '吗', '咧',
'啊', '把', '让', '向', '往', '是', '在', '越', '再', '更', '比',
'很', '偏', '别', '好', '可', '便', '就', '但', '儿',
# 高频副词
'又', '也', '都', '要',
# 高频代词
'这', '那', '你', '我', '他',
#高频动词
'来', '去', '道', '笑', '说',
#空格
' ', ''
]);
segmentDF = segmentDF[
~segmentDF.segment.isin(wyStopWords)
]
#词频统计
segStat = segmentDF.groupby(
by=["segment"]
)["segment"].agg({
"计数":numpy.size
}).reset_index().sort_values(
by=["计数"],
ascending=False
);
segStat.head(100)
#绘制词云
#http://www.lfd.uci.edu/~gohlke/pythonlibs/
from wordcloud import WordCloud
import matplotlib.pyplot as plt
wordcloud = WordCloud(
font_path='D:\\simhei.ttf',
background_color="black"
)
words = segStat.set_index('segment').to_dict()
wordcloud = wordcloud.fit_words(words['计数'])
plt.imshow(wordcloud
plt.close()

得到了和之前类似的词云,下面在此基础上进行词云的美化:
首先选取一张背景图

#词云美化
首先导入需要的包:
from scipy.misc import imread
import matplotlib.pyplot as plt
from wordcloud import WordCloud, ImageColorGenerator
#导入背景图
bimg = imread(r"C:\Users\www12\Desktop\data\2.5\贾宝玉.png")
wordcloud = WordCloud(
background_color="white",
mask=bimg, font_path='D:\\PDM\\2.5\\simhei.ttf'
)
#将图片赋值给mask参数
wordcloud = wordcloud.fit_words(words['计数']) #绘制词云图
#设置词云颜色
bimgColors = ImageColorGenerator(bimg)
plt.axis("off")
plt.imshow(wordcloud.recolor(color_func=bimgColors))
plt.show()
结果如图:
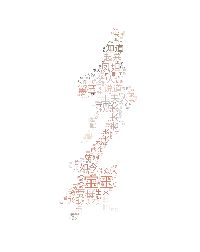
噢,腿太长了,效果并不好,原图截掉一部分,重新绘制。

这次大功告成!宝玉C位妥妥的!