python爬虫之爬取起点中文原创小说排行榜
学习python有段时间了,最近做了一个网上爬虫工具爬取起点中文原创小说排行榜数据,作为最近学习python的一个阶段性成果。
工具
对于做网络爬虫工具经常用到的就是chrome浏览器,主要用于抓取网页中的关键有效信息,F12键 使用其中的network功能可以监控其与服务器功能:
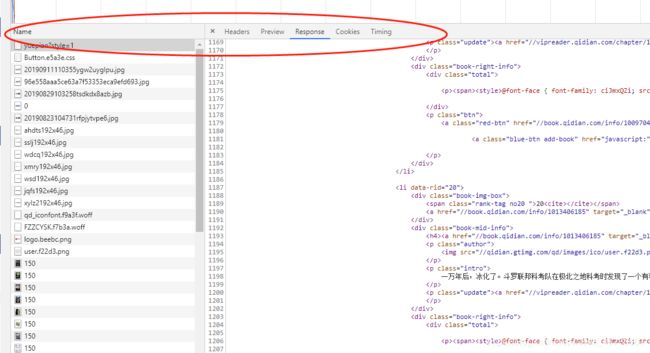
Name: 请求的名称,一般为URL的最后一部分为内容
Header:是请求的http消息头,主要包括General, Request headers,请求体,response header,响应体等主要部分,详细了解请看传送门
Preview:为收到的回应主题部分,主要为html格式,该栏为预览模式,转换成网页的显示
Respone:为查看到的html代码
Cookies:为收到的cookies数据
Timing:为响应一个网页整个过程的耗时,里面按照耗时过程,显示了整个网页交互过程每个阶段的耗时情况
分析网页信息
利用chrome分析url,以及html代码的特点,确定要抓取到的数据位置,本例程为抓取起点中文排行榜,其网页url链接为:
https://www.qidian.com/rank/yuepiao?style=1,网页内容如下:
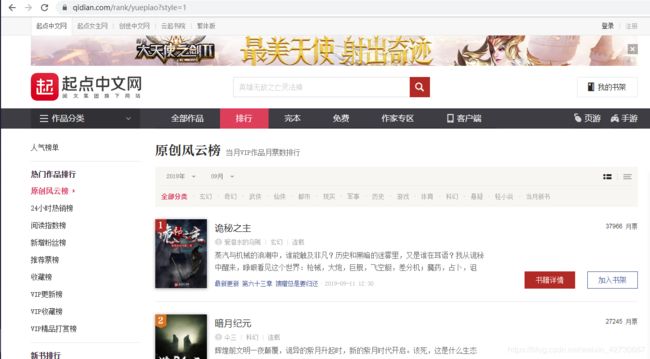
首先查看网页内容,想要抓取的是小说排名以及对于的小说书名,其他信息暂不爬取,由于小说排名较多一个网页显示不下,就需要多页显示,
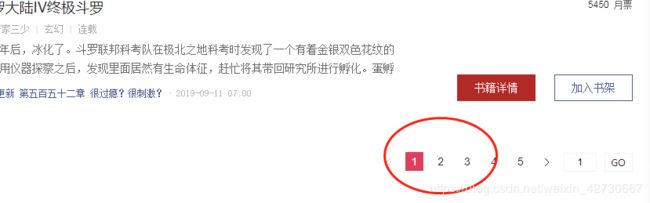
点击下面网页1,2,3,4首先分析其url地址特点,当点击第2页时,其url为如下:
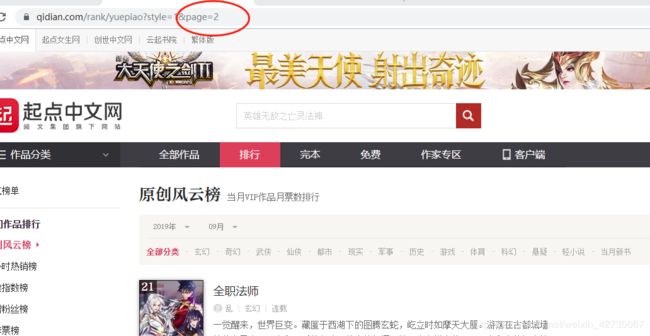
可以看到在url中,添加了page=2 这个参数表明为小说排行榜的第二页,接下来点击第三页则url 中page=3,如此可以分析到其分页网页规律,通过对url格式分析(对URL格式不了解的,可以先查看传送门)?后面为客户端向服务器端发送的query 中的参数,其中page参数表明为请求的第几个网页,连续修改page大小,发现最多只有25个page,至此我们需要的爬虫url规律以及分析完毕,即page表明为,申请的第几个网页,那么这段代码如下:
def get_one_page(url):
return None
def main():
print("起点原创小说排行榜")
for index in range(1,25):
url = 'https://www.qidian.com/rank/yuepiao?style=1&page=%d'%(index)
html = get_one_page(url)
main() 在该程序中,定义main()函数为主程序,首先我们将分析到的url特点 利用字符串格式化输出拼装成完整的url地址
,由上述尝试可知,page最多只能到15页,利用循环分别格式化输出每个页的url,方便后续进行操作。get_one_page()函数目前为空,该函数准备用来打开一个url,并获取到相关内容。
打开网页并获取到内容
使用chrome分析其html头部信息
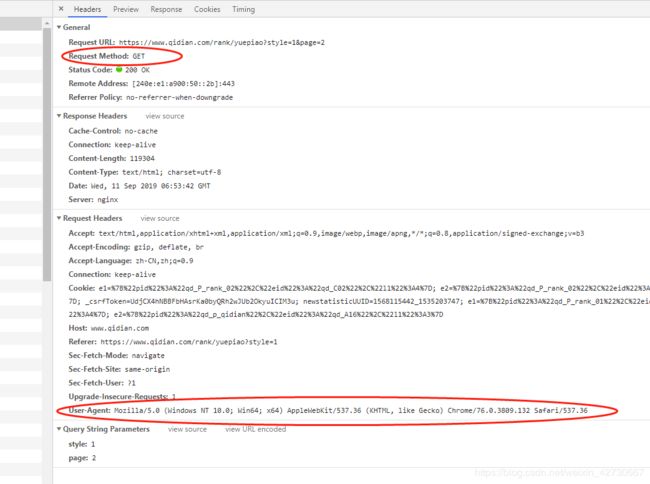
主要获取到两个信息,该url请求方法为GET,以及User-Agent信息,该信息主要用于防止网站服务器进行反爬虫链接,表明使用的浏览器版本信息等。
接下来完成get_one_page()函数里面的内容,打开一个网页并获取到其内容,代码如下:
def get_one_page(url):
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.132 Safari/537.36'
}
response = requests.get(url, headers=headers)
if response.status_code == 200:
return response.text
return None在这里使用到的requests库中的Get 方法,主要功能时向一个url发送一个GET请求,并获取到其内容,然后将上述获取到的User-Agent信息封装到GET请求中,防止进行反爬虫,返回结果查看服务器返回状态是否为200, 200表明GET该url成功,否则返回None, GET url成功之后将服务器返回的Body部分返回,response.txt,运行结果如下:

使用print打印其返回结果为html body与chrome response中的代码一样
分析html代码
可以使用chrome中的response分析其html代码,html代码为标签格式,每个标签都是有开始<和结束>成对出现的,我们要抓取小说排行榜信息,查看html代码,发现其

进一步查看每本书的信息使用

其中dat-rid标签代表的是这本身在该网页中属于第几个,pan class="rank-tag noXX"代表的是这本身的排行榜 book-mid-info标签中的 XX
中有书名信息,可知道《全职法师》这本书在排行帮排名第21位

标签中的其他信息,href为该小说的链接,image scr为该小说的封面地址,还有一些其他信息,不是本文中抓取的重点,
由以上信息可以,我们需要抓取的排行帮以及书名信息在上面两个部分,接下来使用正则匹配表达,将每本书的上述两行信息提取出来,重新定义一个函数get_top_number_and_book_name(html),该函数主要功能数根据html信息获取到排行榜和书名的初步信息,代码如下:
def get_top_number_and_book_name(html):
it = re.finditer(r'([,A-Za-z0-9IV\u4e00-\u9fa5:]+)
|(\d+)', html, re.S)
for match in it:
print(match.group())
由于每本书要提取两行信息分别为排行榜信息以及书名行信息,需要使用匹配表达式中的多个匹配 s1|s2,表示主要匹配其中的一个,就表示规则匹配,由于html中由多行,如果要全部匹配则需要使用re.S模式,匹配表达式为:
([,A-Za-z0-9IV\u4e00-\u9fa5:]+)
|(\d+)\d表示为匹配数字,由于匹配数字时一般有多位需要使用到贪婪匹配,\d+标为匹配所有数字
由于小说名都是使用中文,所以需要用到\u4e00-\u9fa5,表示为匹配该段的中文字符,[\u4e00-\u9fa5]+,表示匹配所有中文,小说名除了中文还有英文,以及逗号,冒号等其他特殊形式的符合,所以匹配书名表达式为:
[,A-Za-z0-9IV\u4e00-\u9fa5:]+上述代码运行结果:
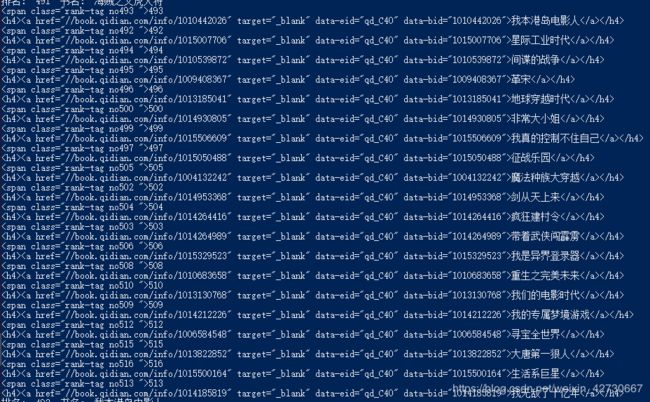
上述代码偶数行为小说排行榜,奇数行为小说书名行。
提取排行榜信息
根据上述抓取到的信息,进一步提取出小说排行榜信息,首先提取出,小说排行榜信息,代码如下:
def get_top_number(number_str):
number_Result = re.search(r'>(\d+)', number_str, re.S)
if None == number_Result:
return None
top_number = re.search(r'(\d+)', number_Result.group(0), re.S)
return top_number.group(0)定义一个新函数,用于获取说排行榜,输入的数据格式为
493使用正则匹配分两步提取其中的信息,首先提取出>XXX信息,最后提取出小说排行信息,运行结果如下:

提取书名信息,其代码如下,也是分两步提取:
def get_book_name(book_info_tr):
book_str = re.search(r'>([,A-Za-z0-9IV\u4e00-\u9fa5:]+)<', book_info_tr, re.S)
book_name = re.search(r'([,A-Za-z0-9IV\u4e00-\u9fa5:]+)', book_str.group(0))
return book_name.group(0)运行结果如下:

此时要提取的信息以及提取完毕,将上述代码进行整合
完整代码
完整代码如下:
import requests
import re
def get_one_page(url):
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.132 Safari/537.36'
}
response = requests.get(url, headers=headers)
if response.status_code == 200:
return response.text
return None
def get_top_number(number_str):
number_Result = re.search(r'>(\d+)', number_str, re.S)
if None == number_Result:
return None
top_number = re.search(r'(\d+)', number_Result.group(0), re.S)
return top_number.group(0)
def get_book_name(book_info_tr):
book_str = re.search(r'>([,A-Za-z0-9IV\u4e00-\u9fa5:]+)<', book_info_tr, re.S)
book_name = re.search(r'([,A-Za-z0-9IV\u4e00-\u9fa5:]+)', book_str.group(0))
return book_name.group(0)
def get_top_number_and_book_name(html):
it = re.finditer(r'([,A-Za-z0-9IV\u4e00-\u9fa5:]+)
|(\d+)', html, re.S)
number = 0
top_number = 0;
book_result={}
book_name =''
for match in it:
if number%2 == 0:
top_number = get_top_number(match.group())
else:
book_name = get_book_name(match.group())
book_result[top_number] = book_name
number += 1
return book_result
def main():
print("起点原创小说排行榜")
for index in range(1,25):
url = 'https://www.qidian.com/rank/yuepiao?style=1&page=%d'%(index)
html = get_one_page(url)
if None == html:
print("is none")
book_result = get_top_number_and_book_name(html)
for book_top in list(book_result.keys()):
print("排名: ", book_top, " 书名: ", book_result[book_top])
main()
将所有排行榜网页抓取,运行结果如下:

是不是很简单,代码没有超过一百行。