用Gym学习强化学习之Policy Gradient
作者:Cloudyyyyy@HIT
兴趣方向:自然语言处理、人工智能
目录
- 什么是强化学习
- 强化学习的问题要素
- Gym简介
- Policy Gradient实战
- 总结
- 参考
1 什么是强化学习
强化学习在机器学习的应用分类里常常和监督学习和非监督学习并列。
在监督学习和非监督学习中,我们可以获得固定的数据集,将数据集喂给特定的模型,拟合数学公式,学习其特征规律。

监督学习 VS 非监督学习
在上述问题中,我们需要考虑的问题是如何将已有数据集的知识迁移到新的数据集中。
然而,强化学习并不属于这类问题。在强化学习里,我们没有现成的数据集可以学习,而是需要在环境中“试错”,根据环境给我们的反馈进行模型参数的调整。
所以,反馈即是强化学习独特的问题特征。
2 强化学习的问题要素
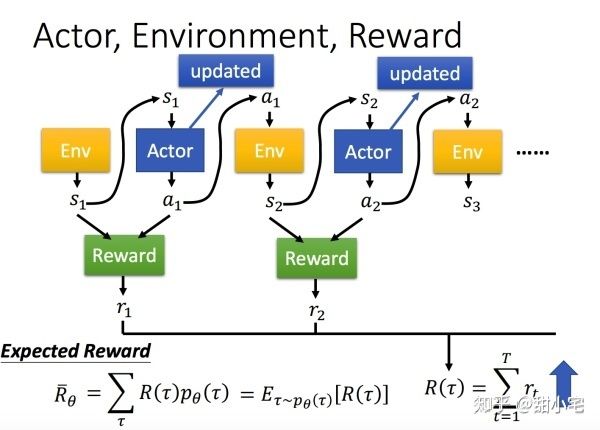
在强化学习中,三个重要的要素是:Actor(Agent)、Environment、Reward。
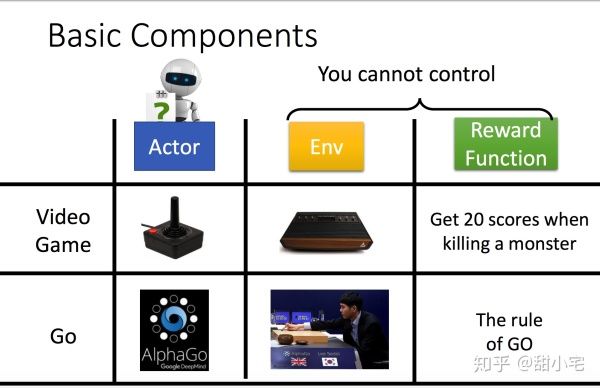
这三者的关系可以表示为:
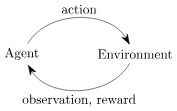
Agent是我们学习的对象,Agent可以做出自己的行为action,然后获取Environment反馈的信息observation(state)。根据observation(state)附带的激励reward,Agent可以判断本次action的好坏,进而调整自己的参数。同时,本次observation(state)将继续作为Agent的输入进行下一次行为action的判断。
这种根据环境反馈来进行模型学习的方式就是强化学习。
3 Gym简介
听完上面的描述,读者可能对强化学习还存在较为模糊的认知,这里选择Gym平台来让大家直观感受强化学习的训练过程。
Gym 环境示意
Gym是Openai开发的一个用来测试强化学习算法的工具。当我们使用Gym的时候,我们只需要重点关注Agent的训练过程,而Environment、reward这些信息都将由Gym平台提供,无需我们进行额外的设计和开发。
这里我们选择较为简单的CartPole-v1 1进行强化学习算法Policy Gradient的实现:
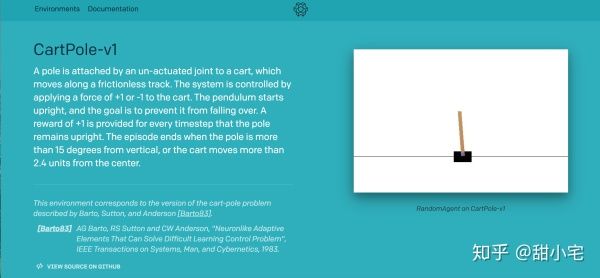
在这个任务中,小车Cart通过左移和右移来保证竿子Pole的平衡,时间越久奖励reward越高。
在使用前,请根据官方文档安装其Gym,本文选择的工具为Python 3.6,Pytorch 0.4。
4 Policy Gradient实战
在Policy Gradient中,我们需要训练一个Agent。这个Agent相当于一个分类器,其输入是观测到环境的信息observation(state),输出为行为action的概率分布。我们可以用简单的多层感知机去实现这个分类器:
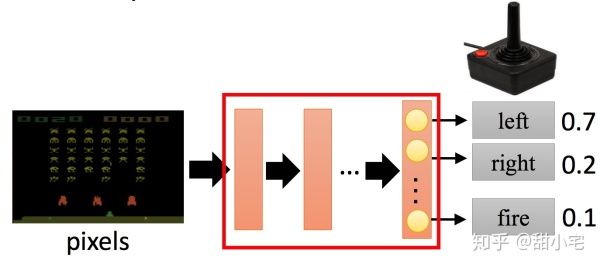
在该任务中,可以查看输入observation(state)和输出action的维度:
import gym
env = gym.make('CartPole-v1')
print(env.action_space)
# Discrete(2)
print(env.observation_space)
# Box(4,)
我们可以构建一个简单的多层感知机充当二分类器:
class PGN(nn.Module):
def __init__(self):
super(PGN, self).__init__()
self.linear1 = nn.Linear(4, 24)
self.linear2 = nn.Linear(24, 36)
self.linear3 = nn.Linear(36, 1)
def forward(self, x):
x = F.relu(self.linear1(x))
x = F.relu(self.linear2(x))
x = torch.sigmoid(self.linear3(x))
return x
我们的需要训练一个CartAgent,应当至少具备以下接口:
class CartAgent(object):
def __init__(self, learning_rate, gamma):
self.pgn = PGN()
self.gamma = gamma
self._init_memory()
self.optimizer = torch.optim.RMSprop(self.pgn.parameters(), lr=learning_rate)
def memorize(self, state, action, reward):
# save to memory for mini-batch gradient descent
self.state_pool.append(state)
self.action_pool.append(action)
self.reward_pool.append(reward)
self.steps += 1
def learn(self):
pass
def act(self, state):
return self.pgn(state)
前面提过,强化学习不同于监督学习(能够直接使用训练语料中的X和Y拟合该模型)。在Policy Gradient中,我们需要使用特殊的损失函数:
其中 由Agent模型计算得出, 即Reward,由环境给出。这个损失函数能够提高reward值大的action出现的概率。loss的核心实现为:
def learn(self):
self._adjust_reward()
# policy gradient
self.optimizer.zero_grad()
for i in range(self.steps):
# all steps in multi games
state = self.state_pool[i]
action = torch.FloatTensor([self.action_pool[i]])
reward = self.reward_pool[i]
probs = self.act(state)
m = Bernoulli(probs)
loss = -m.log_prob(action) * reward
loss.backward()
self.optimizer.step()
self._init_memory()
想要让该损失函数得到训练,我们就必须获得多组state,action,reward。在实际应用中,这样的组合需要我们在游戏过程中随机抽样出来。
对于某次游戏,我们可以抽样出多组state、action、reward:
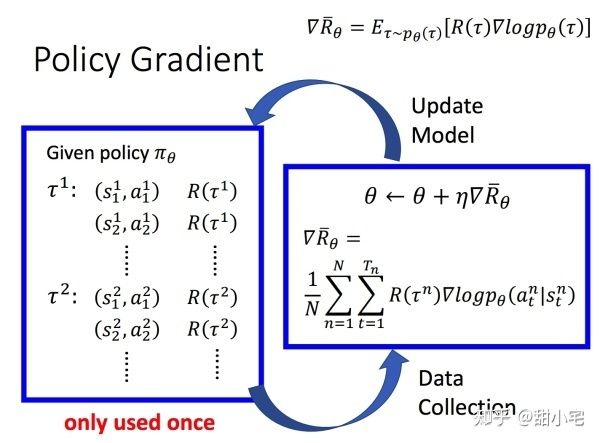
具体的实现为:
# hyper parameter
BATCH_SIZE = 5
LEARNING_RATE = 0.01
GAMMA = 0.99
NUM_EPISODES = 500
env = gym.make('CartPole-v1')
cart_agent = CartAgent(learning_rate=LEARNING_RATE, gamma=GAMMA)
for i_episode in range(NUM_EPISODES):
next_state = env.reset()
env.render(mode='rgb_array')
for t in count():
state = torch.from_numpy(next_state).float()
probs = cart_agent.act(state)
m = Bernoulli(probs)
action = m.sample()
action = action.data.numpy().astype(int).item()
next_state, reward, done, _ = env.step(action)
env.render(mode='rgb_array')
# end action's reward equals 0
if done:
reward = 0
cart_agent.memorize(state, action, reward)
if done:
logger.info({'Episode {}: durations {}'.format(i_episode, t)})
break
# update parameter every batch size
if i_episode > 0 and i_episode % BATCH_SIZE == 0:
cart_agent.learn()
上述state、action、reward组合存在一定的问题。在这个游戏中所有的reward均为0或1,但是某次游戏实际进行了多轮,某次action产生的效益可能远远大于其他相同reward的action。因此,我们需要在某次游戏中结合整个马尔科夫链去考虑某次action的潜在reward。
一种很容易想到的思路是,如果某次action之后的reward很大,说明这次action更好,我们可以将这种潜在的reward添加进来:
def _adjust_reward(self):
# backward weight
running_add = 0
for i in reversed(range(self.steps)):
if self.reward_pool[i] == 0:
running_add = 0
else:
running_add = running_add * self.gamma + self.reward_pool[i]
self.reward_pool[i] = running_add
此外,我们需要reward进行适当的均一化。如果reward均为正,则在抽样过程中可能会让一些本应当降低概率的action获得更大的概率提升;如果reward没有进行平均,则游戏行为更多的action组倾向于获得更大的概率提升。
# normalize reward
reward_mean = np.mean(self.reward_pool)
reward_std = np.std(self.reward_pool)
for i in range(self.steps):
self.reward_pool[i] = (self.reward_pool[i] - reward_mean) / reward_std
完成代码后,可以看到实验结果。在起初的时候,小车只能坚持较短的时间:
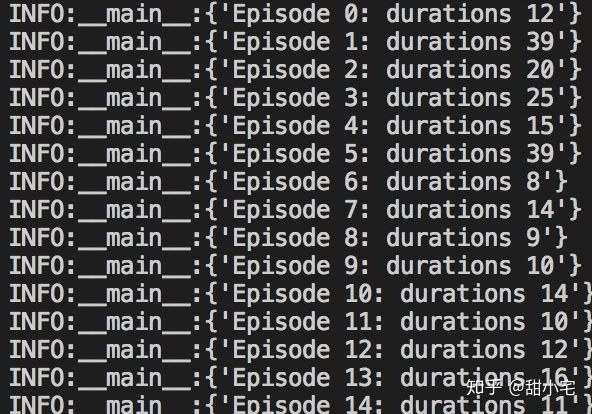
进行150次游戏后,小车坚持的时间已经有了显著的提高。
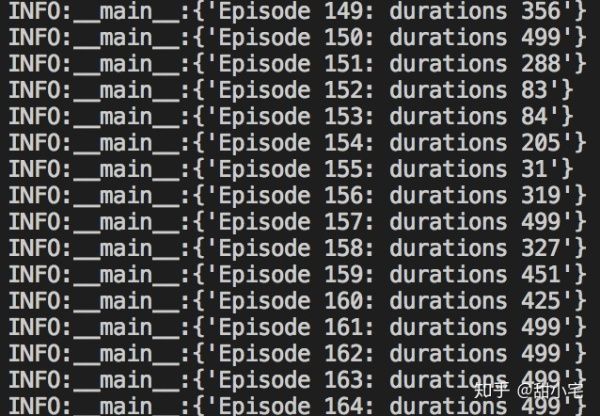
完全版的Demo在这里:github.com/cloudyyyyy/pytorch-rl-demo 4。
5 总结
从实践结果看,实现一个Demo级别的Policy Gradient算法就可以取得较好的效果。如果你想学习强化学习算法,Gym将会是一个测试这些算法的好帮手。
6 参考
- Gym: A toolkit for developing and comparing reinforcement learning algorithms
- 台湾大学-李宏毅《Deep Reinforcement Learning》
- Reinforcement Learning (DQN) tutorial
- Finspire13/pytorch-policy-gradient-example