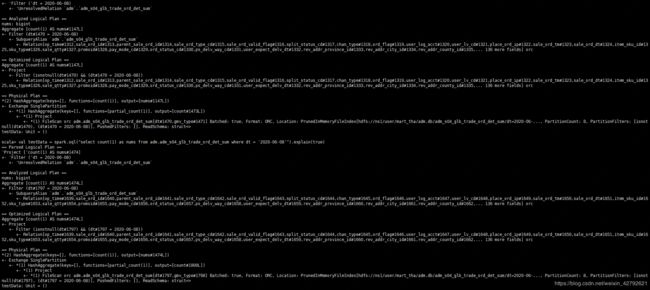
Spark-SQL 查看执行计划API
举个例子:
scala>spark.sql(“select count(1) as nums from gdm.gdm_m03_glb_item_sku_da where dt = ‘2020-06-08’”).explain(true)
在Spark.sql()方法后加 explain,入参为true
返回类型为Unit
// 解析逻辑执行计划
== Parsed Logical Plan ==
'Project ['count(1) AS nums#464]
± 'Filter ('dt = 2020-06-08)
± 'UnresolvedRelation gdm.gdm_m03_glb_item_sku_da
// 分析逻辑执行计划
== Analyzed Logical Plan ==
nums: bigint
Aggregate [count(1) AS nums#464L]
± Filter (dt#582 = 2020-06-08)
± SubqueryAlias gdm.gdm_m03_glb_item_sku_da
± Relation[item_sku_id#526,main_sku_id#527,sku_name#528,sku_name_local#529,sku_name_en#530,sku_name_cn#531,sku_valid_flag#532,sku_status_cd#533,item_id#534,item_name#535,item_name_local#536,item_name_en#537,item_name_cn#538,brand_code#539,brand_name_local#540,brand_name_en#541,brand_name_full#542,item_valid_flag#543,item_status_cd#544,data_type#545,coop_type#546,work_post_cd#547,purchaser_erp_acct#548,purchaser_name#549,… 33 more fields] orc
// 优化逻辑执行计划
== Optimized Logical Plan ==
Aggregate [count(1) AS nums#464L]
± Project
± Filter (isnotnull(dt#582) && (dt#582 = 2020-06-08))
± Relation[item_sku_id#526,main_sku_id#527,sku_name#528,sku_name_local#529,sku_name_en#530,sku_name_cn#531,sku_valid_flag#532,sku_status_cd#533,item_id#534,item_name#535,item_name_local#536,item_name_en#537,item_name_cn#538,brand_code#539,brand_name_local#540,brand_name_en#541,brand_name_full#542,item_valid_flag#543,item_status_cd#544,data_type#545,coop_type#546,work_post_cd#547,purchaser_erp_acct#548,purchaser_name#549,… 33 more fields] orc
// 物理执行计划
== Physical Plan ==
*(2) HashAggregate(keys=[], functions=[count(1)], output=[nums#464L])
± Exchange SinglePartition
± *(1) HashAggregate(keys=[], functions=[partial_count(1)], output=[count#584L])
± *(1) Project
± *(1) FileScan orc gdm.gdm_m03_glb_item_sku_da[dt#582] Batched: true, Format: ORC, Location: PrunedInMemoryFileIndex[hdfs://ns111/user/mart_thaaaxa/gdm.db/gdm_m03_glb_item_sku_da/dt=2020-06-08], PartitionCount: 1, PartitionFilters: [isnotnull(dt#582), (dt#582 = 2020-06-08)], PushedFilters: [], ReadSchema: struct<>
testData: Unit = ()
Q:字段后的 # + 数字代表什么意义
A: 当前Session 全局累加 无意义