python战反爬虫:爬取猫眼电影数据 (一)
非常荣幸邀请到 赛迪人工智能大赛(简称AI世青赛)全球总决赛银奖的获得者 隋顺意 小朋友为本公众号投稿,隋小朋友虽然小小年纪,但编程能力已经比大多数大学生强非常多了,欢迎大家关注,捧场。
姓名:隋顺意
CSDN博客:Suidaxia
微信名:世界上的霸主
本篇文章未涉及猫眼反爬,主要介绍爬取无反爬内容,战反爬内容请去
python战反爬虫:爬取猫眼电影数据 (二)(https://blog.csdn.net/Sui_da_xia/article/details/106051519 )
欢迎加声明转载,下载使用
前言:
如今,所有人无时无刻在使用互联网。它就像一张大网,将所有人联系在一起。而总有些可恶的刺头,只让他人看他的内容,不把他的数据给大家用。
正因为如此,我们有了伟大的爬虫工程师,他们手持利剑,突破刺头设置的重重难关,获取数据。今天,就让我们一起,共同大战“猫眼电影”设置的障碍吧!
获取初步信息:
我们这次爬取的是猫眼电影前100名排行榜,网址:https://maoyan.com/board/4?
导入python的各种库:
import requests as req
import re
from bs4 import BeautifulSoup as bs
import time as ti
若是没有以上的requests和bs4,请先安装。只需在终端输入:
pip install requests
pip install bs4
先试试直接get页面:
url = "https://maoyan.com/board/4?"
res = req.get(url)
print(res.status_code)
print(res.text)
我们会发现状态是,200,但是text却是一堆乱码,很不巧,遇到了第一个障碍,也是最容易解决的。只需要加上headers即可:
url = "https://maoyan.com/board/4?"
header = {
"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.122 Safari/537.36",
}
res = req.get(url,headers = header)
print(res.status_code)
print(res.text)
至于获取headers,可以在浏览器输入栏里输入 about:version,找到用户代理那一栏即可。
解析:
我们可以使用BeautifulSoup和正则表达式(re)我们先看看我们在这一页面可以爬取到什么信息:
 我是用绿框标出我们这页课爬取的信息:排行,片名,主演,分数,上映时间。按下F12,打开开发者工具,查找相应的位置。
我是用绿框标出我们这页课爬取的信息:排行,片名,主演,分数,上映时间。按下F12,打开开发者工具,查找相应的位置。
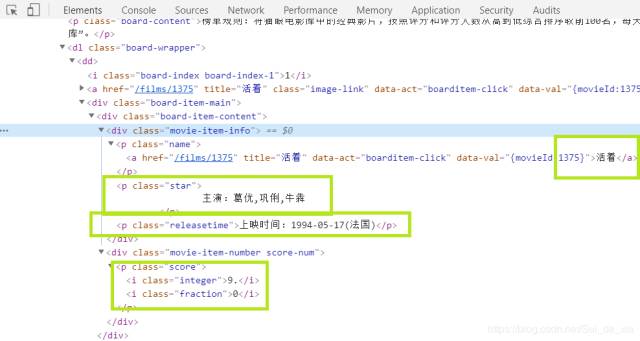 利用正则表达式和解析库BeautifulSoup,取出内容:
利用正则表达式和解析库BeautifulSoup,取出内容:
num = i.find("i").text #排行
name = i.find("a").get("title") #片名
actor = re.findall("主演:(.*)",i.find("p",class_ = "star").text)[0] #主演
when = re.findall("上映时间:(.*)",i.find("p",class_ = "releasetime").text)[0] #上映时间
score = i.find("i",class_ = "integer").text + i.find("i",class_ = "fraction").text #评分
#这种取变量名的习惯极其不好,期望大家更改
但是这样依旧获取的信息太少,不足以满足需求。为了进一步的爬取信息,我们可以到每一部电影的详细信息里查看。先用解析库和正则表达式把网址抠出来:
url1 = "https://maoyan.com" + i.find("p",class_ = "name").a.get("href")
把获取页面的函数整理一下,获取详细信息的页面:
def link(url):
header = {
"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.122 Safari/537.36",
}
res = req.get(url,headers = header)
if res.status_code == 200:
return bs(res.text,"lxml")
return None
movie = link(url1)
print(movie)
但是,你不觉得对于返回的东西太奇怪了吗?
去 python战反爬虫:爬取猫眼电影数据 (二)(Requests, BeautifulSoup, MySQLdb,re等库) 吧(https://blog.csdn.net/Sui_da_xia/article/details/106051519)
后记:
完结了?不,还早着呢!
那下文在哪里呢?看后文之前,要做好与反爬虫斗争的准备。
在下一篇文章:python战反爬虫:爬取猫眼电影数据 (二)(Requests, BeautifulSoup, MySQLdb,re等库) 将会谈论到两道猫眼电音为我们设计的反爬:美团拦截,及多页面爬取。他们都是可恶的反爬虫师,为伟大的爬虫勇士准备着的。
(至于美团的字体加密,会在python战反爬虫:爬取猫眼电影数据 (三)(Requests, BeautifulSoup, MySQLdb,re等库) 谈论到)
附上作者的赞赏码!欢迎大家支持!

本文完!!!
欢迎关注,更精彩的内容等着你!

点击阅读原文,为作者博客捧场!