数据分析-项目实战:Kaggle泰坦尼克号(Titanic)沉船幸存者预测(易懂快速上手版)-二元分类-自读
#前言
Kaggle上的泰坦尼克项目,对于初学机器学习的朋友来说,是一个很好的练手机会,能大概了解整个机器学习的全过程。下面我把自己做这个项目的经验分享一下,希望对想了解机器学习的朋友有所帮助,里面结合很多前辈的智慧,大家可以参考最后的链接。
在文章最开头,我分享一下实际应用项目和竞赛项目的区别,实际应用中,训练的样本相对于实际的数据集总是少的,而它的评分标准,是以实际的数据集的准确度作为参考的,而在竞赛项目中,用于检验结果的测试集相对于训练集是偏少的,但是竞赛的评估结果,是以测试集的匹配度作为依据的,所以有可能会出现实际应用中比较好的模型,但是在竞赛项目中,因为测试集特有的偏差,而导致竞赛的结果并不好,这是很正常的现象。而泰坦尼克号这个项目,就存在这个问题,因为我们最后的标准是那个测试集,所以要达到最好的竞赛结果,需要去迎合那个测试集的分布特征。因为这点差异,所以竞赛项目中要想获得好名次,所要采取的战略是不一样的,泰坦尼克号适合你熟悉整个的机器学习流程,但是对于要想获得好的结果,就需要不断的去调整特征工程,模型和超参数,而且最关键的是要有一个参考点,类似于A/B测试,发现哪些特征适用于这个测试集,不能盲目的尝试。
一般的机器学习分为以下几个步骤:
1、定义问题
2、导入数据
3、理解分析数据
4、清洗转换数据
5、特征工程
6、模型选择及超参数调优
7、模型融合
8、获得问题的答案
在这几个步骤中,有一些操作是会反复出现的,比如说交叉验证,网格搜索,特征选择,管道(算法链),评估指标等等。我会在具体的步骤中解释。
对于一个具体的项目,如何去评估这个项目的优劣很重要,因为每一个项目都是基于真实场景的,我举一个简单的例子,比如说测试癌症的患病率,如果没有患癌症,却被误断出来癌症,对于病人的损失可能是多做几次治疗和所花的费用,这种情况的评估指标就是测准度(precision),也就是预测的结果中,实际存在不正确的例子。另外一种情况,如果一个人患癌了,但是却检测出来没患病,那对于患者的损失可能就是生命了,衡量这种情况的指标,就是测全度(recall)。回到泰坦尼克号的例子,我们判别的指标其实相对比较简单,就是判断预测出来的存活情况是否正确,不存在说,实际是存活了,我们却预测他遇难了,会带来什么实质的影响,这个就叫做精度。当然,精度对于相对平衡(0:1在0.5~2之间)的二分类数据集还是很好的指标,但是对于不平衡的数据集,那么精度就不是很好的度量了,这个时候要用到f-分数。只是给大家开一个头,具体的信息,大家需要到相关统计学或者机器学习的书籍中查找。
对于泰坦尼克号这个项目,我们的指标选择精度就够了。
那么有哪些因素是影响最后的指标的呢,主要是以下四个方面:
1、特征工程的质量
2、样本的数量
3、模型的类型和结合方式
4、模型的超参数
其实就是上面8个步骤的5-7。
下面我就从上面讲的8个步骤,4个要点,来详细演示一下这个项目。
#1、定义问题
这个项目的目的,是预测测试集中人员是否生还,也就是肯定当作二元分类的预测问题,因为是相对平衡的数据集,可以用精度作为衡量指标,而且生还和遇难并没有实质的区别(在数据层面上),所以不考虑准确度和召回率。
简单点说,就是利用训练数据集,训练模型,然后用测试数据集预测模型的精度。
#2、导入数据
该项目的数据源可以在这个链接下载,点这里下载项目数据
##导入需要用到的模块(我写这篇分享,是基于一个脚本写的,所以会把模块一次性全部导入,这样的好处是,所有的过程复现程度很快,实际挖掘过程中,刚开始是探索型的,很多子模块是根据需求加进去的)
#基础模块
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import numpy as np
import warnings
warnings.filterwarnings('ignore')
#模型预处理
from sklearn.preprocessing import StandardScaler
from sklearn.preprocessing import LabelEncoder
from sklearn.pipeline import Pipeline
from sklearn.feature_selection import RFECV
from sklearn.model_selection import KFold
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import GridSearchCV
#回归模型模块
from sklearn.ensemble import GradientBoostingRegressor
from sklearn.linear_model import LinearRegression
from sklearn.ensemble import RandomForestRegressor
#分类模型模块
from sklearn.linear_model import LogisticRegression
from sklearn.linear_model import LogisticRegressionCV
from sklearn.linear_model import Perceptron
from sklearn.linear_model import SGDClassifier
from sklearn.linear_model import PassiveAggressiveClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.svm import SVC, LinearSVC
from sklearn.gaussian_process import GaussianProcessClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.naive_bayes import BernoulliNB
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import AdaBoostClassifier
from sklearn.ensemble import BaggingClassifier
from sklearn.ensemble import ExtraTreesClassifier
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.ensemble import RandomForestClassifier
##导入数据
train_raw=pd.read_csv('train.csv')
test_raw=pd.read_csv('test.csv')
#创建新的整体列表
alldata=pd.concat([train_raw,test_raw],ignore_index=True)
#3、理解分析数据
理解分析数据包括两个方面:
1、检查数据是否有缺失,异常,大体的描述统计情况
2、理解数据在实际场景中的含义
##info()和describe()两个方法是对数据大体了解的不错选择,还可以用head(),tail(),或者loc,都是不错的方式
train_raw.info()
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
PassengerId 891 non-null int64
Survived 891 non-null int64
Pclass 891 non-null int64
Name 891 non-null object
Sex 891 non-null object
Age 714 non-null float64
SibSp 891 non-null int64
Parch 891 non-null int64
Ticket 891 non-null object
Fare 891 non-null float64
Cabin 204 non-null object
Embarked 889 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 83.6+ KB
test_raw.info()
RangeIndex: 418 entries, 0 to 417
Data columns (total 11 columns):
PassengerId 418 non-null int64
Pclass 418 non-null int64
Name 418 non-null object
Sex 418 non-null object
Age 332 non-null float64
SibSp 418 non-null int64
Parch 418 non-null int64
Ticket 418 non-null object
Fare 417 non-null float64
Cabin 91 non-null object
Embarked 418 non-null object
dtypes: float64(2), int64(4), object(5)
memory usage: 36.0+ KB
##还可以用isnull直接得到所有的缺失值,这种方式比较容易发现缺失值,方式其实很多啦,大家可以多试试。
train_raw.isnull().sum(0)
Out[23]:
PassengerId 0
Survived 0
Pclass 0
Name 0
Sex 0
Age 177
SibSp 0
Parch 0
Ticket 0
Fare 0
Cabin 687
Embarked 2
dtype: int64
test_raw.isnull().sum(0)
Out[24]:
PassengerId 0
Pclass 0
Name 0
Sex 0
Age 86
SibSp 0
Parch 0
Ticket 0
Fare 1
Cabin 327
Embarked 0
dtype: int64
接下来我们来讲讲,各数据的真实场景含义。
PassengerId:客户的编号,可以当作SQL中的键值,没有实际的含义;
Pclass:船舱的等级,一般和票价是成正比的,但是我发现不少船票价格是0英镑的乘客,可能还有一些其他的因素;
Name:乘客的姓名,最基本的就是姓名加一个称呼;
Sex:性别;
Age:乘客的年龄;
SibSp:乘客的非直系亲戚数量;
Parch:乘客的直系亲戚数量(父母和孩子);
Ticket:船票号码,有连号的说明是一起购买的;
Fare:船票的价格;
Cabin:具体的船舱位置;
Embarked:登陆的港口位置。
我们先对这些数据有一个感性的认识,具体的影响,还要在数据的图像化中发现。
#4、清洗转换数据
##4.1、清洗数据
数据清洗的第一步,先是处理缺失值,因为很多模型在缺失值存在的情况下,是无法运算的,而缺失值处理,一般先从缺的最少的开始,因为其他的缺失字段,比如年龄,我们可以考虑用回归的方式预测,比简单的分组平均要更准确。
##清洗转换数据
#Embarked:用众数处理空缺值
alldata.Embarked.fillna(alldata.Embarked.mode()[0],inplace=True)
#Ticket和Fare:计算重票的人数,仔细点会发现,原数据中的票价,其实是和自己同票的人的总票价,所以需要重新整理一下。
alldata['NTickets']=alldata.groupby('Ticket')['Ticket'].transform('count')
alldata['Fare_S']=alldata.Fare/alldata.NTickets
#用平均值填补空缺
alldata.Fare_S.fillna(alldata.Fare_S.mean(),inplace=True)
#Fare_S:根据每个价位段,合理的分配各价位,我选择的分配方式如下:
alldata['Fare_0']=np.where(alldata.Fare_S==0,1,0)
alldata['Fare_0_10']=np.where(((alldata.Fare_S>0)&(alldata.Fare_S<=10)),1,0)
alldata['Fare_10_15']=np.where(((alldata.Fare_S>10)&(alldata.Fare_S<=15)),1,0)
alldata['Fare_15_45']=np.where(((alldata.Fare_S>15)&(alldata.Fare_S<=45)),1,0)
alldata['Fare_45']=np.where(alldata.Fare_S>45,1,0)
#NTickets:查看NTickets和存活率之间的关系,按照1张,2-4张,5张以上分成三组
def NTickets_grouping(x):
if x==1:
x='Single'
elif 1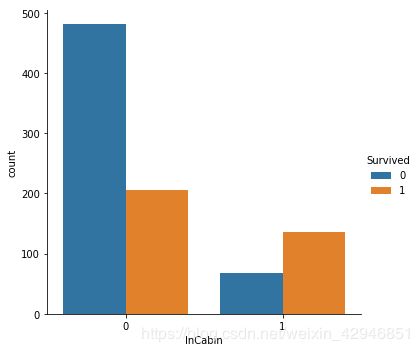
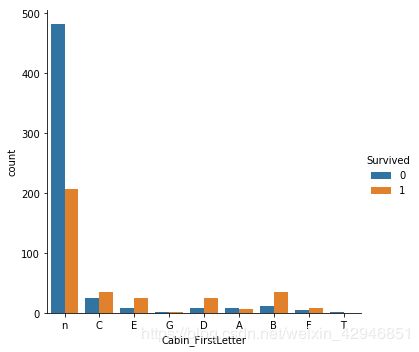
当然,你也可以取出每一个Cabin的首字母,或者看有几个号的Cabin和单个号的,以及没有号的具体区别。
##Cabin首字母
for data in combine:
f=lambda x:str(x)[0]
data['Cabin_FirstLetter']=data.Cabin.map(f)
sns.catplot('Cabin_FirstLetter',hue='Survived',data=train,kind='count')
##4.2、转换数据
现在,我们除了年龄等着之后回归分析之外,其他的空缺值都处理好了,下一步就是转换数据了,转换数据主要包括:
1、从字符串中抽出有价值的信息,转换成分类变量或者One-Hot变量
2、分析数值变量,处理异常值,必要时进行分箱操作
3、将单变量进行转换,可以是单变量变成多项式,也可以是单变量有线性的变为非线性的
4、将多变量组合成单变量
###4.2.1、SibSp和Parch数据整合
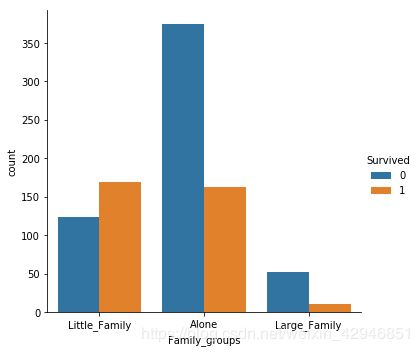
##家属数据的整合,因为从数据中可以看出,存活率跟家庭人数有关,所以分三个部分,1个人是Alone,2-4个人是Little_Family,5人以上是Large_Family。
for data in combine:
data['Family']=data.eval('SibSp+Parch+1')
sns.catplot('Family',hue='Survived',data=train,kind='count')
def Family_grouping(x):
if x==1:
x='Alone'
elif 1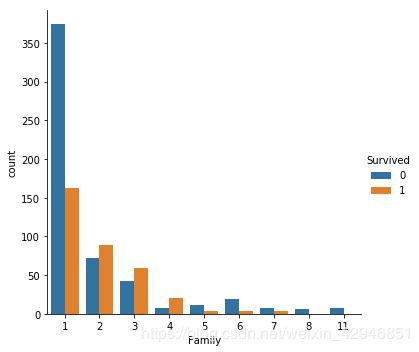
###4.2.2、Name转换
Name这一列数据涵盖的信息非常广,我看Kaggle的kernel上有人只靠这列数据,拿到了82%的精度,因为是用R写的,所以没有去尝试。我这里先就将Name中的Title提取出来。
##提取出Name中的Title
for data in combine:
data['Title'] = data.Name.str.extract(' ([A-Za-z]+)\.', expand=False)
#看一下具体有哪些Title,显然我们需要将其划归5个以下的小类
train.Title.value_counts()
Out[92]:
Mr 517
Miss 182
Mrs 125
Master 40
Dr 7
Rev 6
Mlle 2
Col 2
Major 2
Countess 1
Jonkheer 1
Ms 1
Lady 1
Sir 1
Don 1
Mme 1
Capt 1
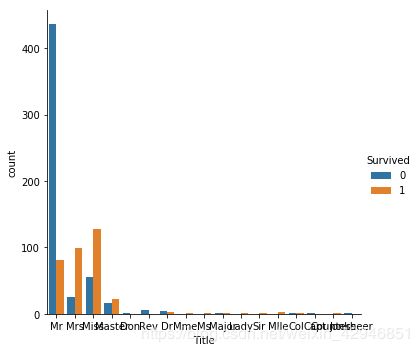
sns.catplot('Title',hue='Survived',data=train,kind='count')
#然后根据存活率和具体的数量,将Title划归成几个小类,这里使用字典替换名称时,需要注意一下,如果在字典中没有该键,则会直接跳过,所以我们需要用一个字典的get方法
mapping_title={'Capt':'Rare','Lady':'Mrs', 'Countess':'Miss', 'Col':'Rare','Don':'Rare', 'Dr':'Rare', 'Major':'Rare', 'Rev':'Rare', 'Sir':'Rare','Jonkheer':'Rare', 'Dona':'Rare','Mlle':'Miss','Ms':'Miss','Mme':'Mrs'}
for data in combine:
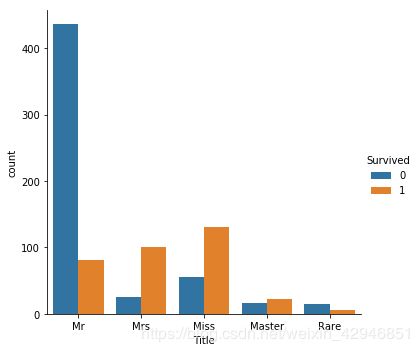
data['Title']=data.Title.map(lambda x:mapping_title.get(x,x))
sns.catplot('Title',hue='Survived',data=train,kind='count')
###4.2.3、Ticket处理
船票第一眼看实在是杂乱到不行,但是进行统计之后,发现船票居然有同号的,说明有人是用同一张船票的,那么我们可以假设,如果是几个人用一张船票的话,会不会存活率不同呢?
##将船票统计起来的步骤稍微繁琐一些,因为训练数据集和测试数据集需要统一起来统计,然后再拆开到各自的数据集中
ticket=pd.concat([train[['PassengerId','Ticket']],test[['PassengerId','Ticket']]],ignore_index=True)
ticket['NTickets']=ticket.groupby('Ticket').transform('count')
for data in combine:
data=pd.merge(data,ticket[['PassengerId','NTickets']],how='left',on='PassengerId')
#检查一下联票的情况,决定是不是需要继续处理
sns.catplot('NTickets',hue='Survived',data=train,kind='count')
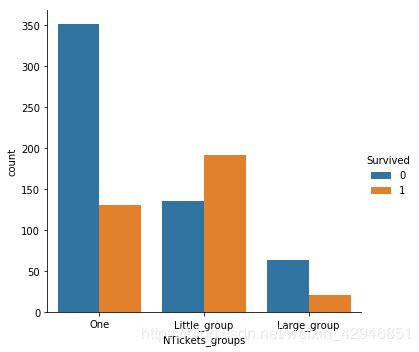
#发现NTickets的情况和Family的情况极其相似,所以可以以相似的方式,将NTickets分成3个部分,之后我们的特征工程选择会自动的将相关性不大的特征工程排除的。
def Ticket_grouping(x):
if x==1:
x='One'
elif 1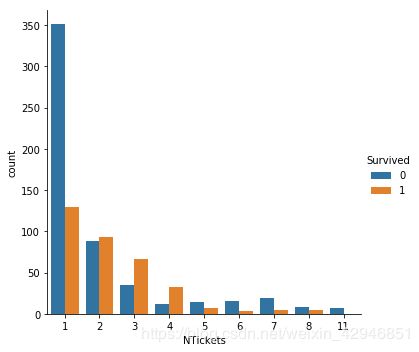
###4.2.4、分类变量One-Hot化
检查一遍数据之后,发现能处理的基本都处理了,还剩下年龄没有补充空缺值,在进行年龄预测前,现将分好类的特征进行One-Hot化。
这里解释一下原因,一般最后进行模型预测的数据,可以分成三类数据:
1、连续的数值变量(比如说从0-100,连续变化的数值)
2、离散的数值变量(比如说0,1,2,3,4)
3、布尔分类变量(0,1,变成布尔变量的情况一般是从字符串分类变量或者从离散的数值变量转化过来,为什么不将字符串转化成离散的数值变量呢,主要原因是因为,离散的数值变量有大小区分,我拿泰坦尼克号登船的地点来举例,Embarked一共有S,C,Q三个变量,如果将其转化成1,2,3的话,在计算机看来,可以等价于S+C=Q,从逻辑上理解,这是显然错的,所以我们需要将这类字符串数据One-Hot成布尔分类变量类型)
对于其他的变量,计算机模拟时,是一律识别不了的。
另外再补充一下,连续的数值变量可以通过分箱的操作,变成离散的数值变量,再通过One-Hot化,变成布尔类变量,具体的操作要看选择的模型类型。
一般规则:
1、对于线性的模型,连续的数值变量是低于离散的数值变量的;
2、对于决策树模型,连续的数值变量是优于离散的数值变量的。
从变量的角度来说:
1、连续的数值变量,如果使用线性模型,最好分箱成离散的数值变量;
2、离散的数值变量,如果数值之间不存在大小关系,最好One-Hot化成布尔变量。
##将分类变量bool化
train_before_get_dummies=train.copy()
test_before_get_dummies=test.copy()
predictors_bool=['Pclass','Embarked','Family_groups','Title','NTickets_groups']
for data in combine:
data=pd.get_dummies(data,columns=predictors_bool)
#如果想直接将分类字符串转换成离散数值变量,也是有办法的,就是用LabelEncoder,这里因为没有必要,所以就不在这里展示了,大家知道有这么函数就好哦,
#from sklearn.preprocessing import LabelEncoder
#Label=LabelEncoder()
#train['Title_Code']=Label.fit_transform(train['Title'])
#再将多余的特征删除
for data in combine:
data.drop(['Name','Sex','PassengerId','Ticket','Cabin','Cabin_FirstLetter','Family','NTickets'],axis=1,inplace=True)
###4.2.5、年龄的模型融合
#用回归模型预测年龄
predictors_age=test.columns
predictors_age=predictors_age.drop('Age')
#定义一个模型融合函数
def Age_Predict(data,columns):
train_set=data[data.Age.notnull()]
test_set=data[data.Age.isnull()]
X_train=train_set[columns]
y_train=train_set['Age']
X_test=test_set[columns]
gbr=GradientBoostingRegressor()
lr=LinearRegression()
rfr=RandomForestRegressor()
MLAs=[gbr,lr,rfr]
predictdict={}
for mla in MLAs:
mla.fit(X_train,y_train)
predictdict[mla.__class__.__name__]=mla.predict(X_test)
df_age=pd.DataFrame(predictdict)
predict_age=df_age.mean(axis=1)
return predict_age.values
#将train和test数据集中的Age列填满
train['Age'][train.Age.isnull()]=Age_Predict(train,predictors_age)
test['Age'][test.Age.isnull()]=Age_Predict(test,predictors_age)
sns.distplot(train.Age,bins=30)
#专题、数据可视化
python中,matplotlib是最底层的数据可视化工具,但是因为它本身比pandas早蛮久出来的,所以和pandas上有很多不兼容的地方,seaborn就是为了解决这个问题而诞生的,自己研究了一下seaborn的绘图方法,趁着这个项目,跟大家分享一下,seaborn画图的经验。
##专题1、数据准备
##整理一份便于画图的数据集
figdata=train_before_get_dummies.copy()
figdata.Age=train.Age
##专题2、一维数据
pandas自身带有plot绘图,所以对于一维的数据,还是使用pandas自带的绘图功能会更方便一些。
##数值变量,一般分为四种图形,直方图,密度图,箱型图和折线图(折线图一般会以索引为x轴,如果索引是时间序列的话,那就变量随时间的变化,但折线图本质上是两维数据的结果了)
figdata.Age.plot(kind='hist')
figdata.Age.plot(kind='kde')
figdata.Age.plot(kind='box')
figdata.Age.plot()
##一维的分类变量的画图就相对很简单了,只有柱形图一种
figdata.Embarked.value_counts().plot(kind='bar')
#直接用figdata.Embarked.plot(kind='bar')会报错,因为都是字符串
##专题3、二维数据
二维数据有以下三种组合:
1、分类-分类
2、分类-数值
3、数值-数值
我按顺序一一讲解这三类的画图步骤。对于二维数据,这个时候用seaborn的感觉就很好了。不然需要将数据集通过分组,聚合,函数运算,索引转换到相应的形式,才好使用pandas自带的plot,会比较不方便,不过我会演示一下,具体怎么操作。
###专题3.1、分类-分类
对于此类数据组合,需要从一维的分类数值说起,我们知道,一维的分类数值只能用柱形图画出,x坐标是含有的类别数,y坐标是各个类别数的数量,那么多了一个分类变量之后,我们可以想象把数据先按照第一组分类变量分组,然后计算各个分组中的函数,因为还是分类变量,所以我们只能计算其数量,如果这个分类变量是bool数,那么还可以计算其0和1的比例。
##下面的是用pandas的plot实现画图的代码
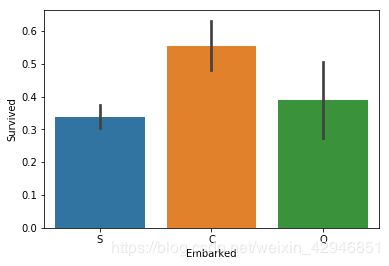
sns.barplot('Embarked','Survived',data=figdata)
sns.catplot('Embarked','Survived',data=figdata,kind='bar')
#figdata.groupby(['Embarked'])['Survived'].mean().plot(kind='bar')
sns.pointplot('Embarked','Survived',data=figdata)
#figdata.groupby(['Embarked'])['Survived'].mean().plot()
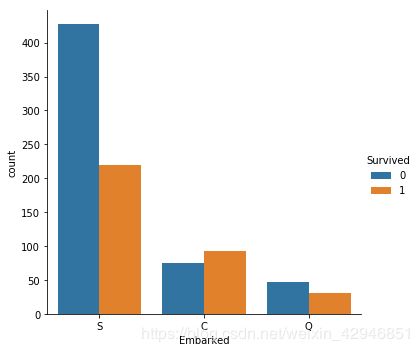
sns.catplot('Embarked',hue='Survived',data=figdata,kind='count')
#figdata.groupby(['Embarked','Survived'])['Survived'].count().unstack().plot(kind='bar')


##专题3.2、分类-数值
在了解这类组合前,先思考一个问题,二维的坐标中,x是自变量,y是因变量,那么可能自变量比因变量多吗?显然是不可能的,那么分类就很明显了,分类变量只能作为自变量,而数值变量作为因变量,这种情况下,数量变量的一维表现有几种,分类-数值变量的形式就有几种。
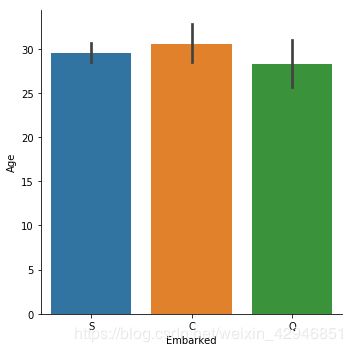
#柱形图,这种形式和分类-分类的类似,展示出来的是均值,方差以及各类别的比较
sns.catplot(x='Embarked',y='Age',data=figdata,kind='bar')
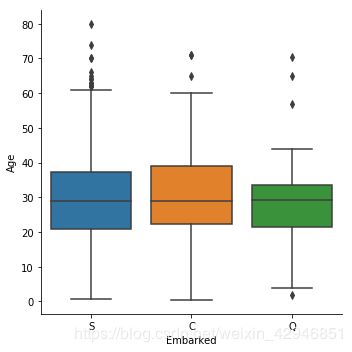
#箱型图,可以当作柱形图的升级版,因为它展示的信息更多,还有异常值也在箱型图中展示了
sns.catplot(x='Embarked',y='Age',data=figdata,kind='box')
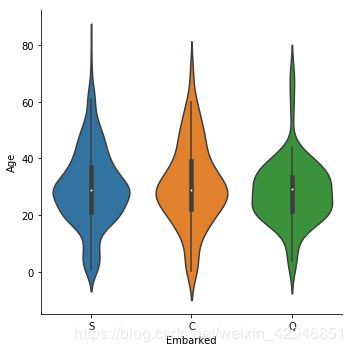
#小提琴图,实质上是将kde图纵向的展示了
sns.catplot(x='Embarked',y='Age',data=figdata,kind='violin')
##专题3.3、数值-数值
数值数值变量这种情况在坐标轴展示出来,就是数值和数值之间的关系了,具体的绘图有四种形式
#kdeplot绘图,因为titanic上Age和Fare的数据实在分布太不均匀,所以图像确实不怎么好看
sns.kdeplot(figdata.Age,figdata.Fare)
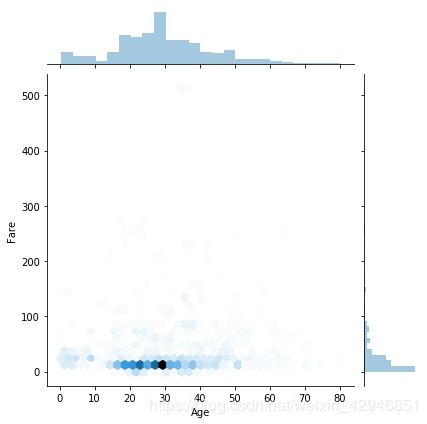
#jointplot绘图,kind可以选择多种,比如'scatter','kde'等等,具体看帮助文档
sns.jointplot('Age','Fare',data=figdata,kind='hex')
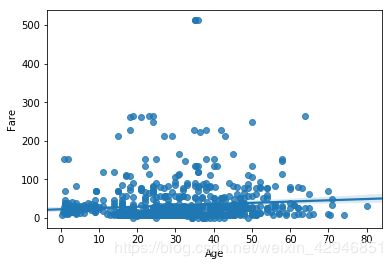
#regplot绘图,这是回归散点图
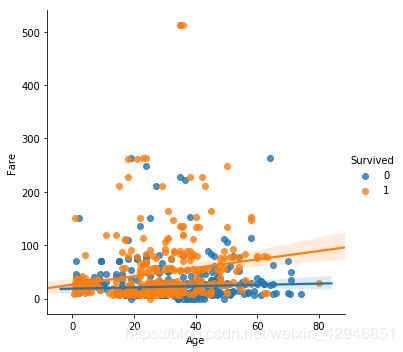
sns.regplot('Age','Fare',data=figdata)
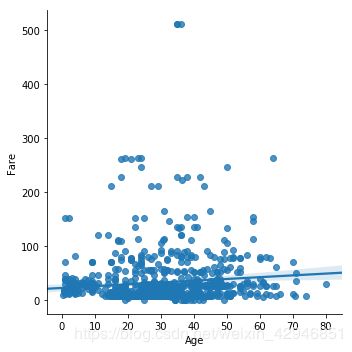
#lmplot绘图,这是regplot和FacetGrid结合的绘图函数,lmplot主要负责回归,catplot主要负责分类,其实掌握这两个函数,就基本能满足大部分的绘图需求了。
sns.lmplot('Age','Fare',data=figdata)
#专题4、多维数据
其实图像越复杂,并不代表可视化的效果越好,因为人接收信息的,理解信息的带宽是有限的,所以最好的可视化是简单明了的表达出数据中的含义。
多维数据的表达有三种方式:
1、二维图像的多维表达
2、多个二维图像的分类表达
3、三维图像的表达
我自己目前只了解到了前面两种,三维的表达还没有学习总结,暂时先介绍前面两种哦。
专题4.1、二维图像的多维表达
这一部分和前面的类似,关键的参数就是hue,一般有四种组合:
1、分类-分类-分类
2、分类-分类-数值
3、分类-数值-数值
4、数值-数值-数值
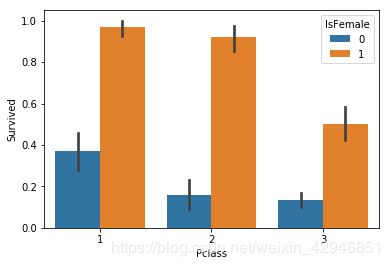
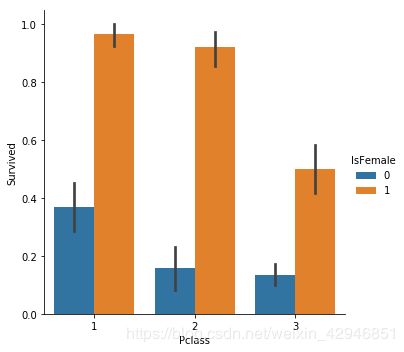
##分类-分类-分类,这里有一点需要注意,就是y轴的分类,一定要是bool变量,这是各舱位和性别的存活率比较。
sns.barplot('Pclass','Survived',hue='IsFemale',data=figdata)
sns.catplot('Pclass','Survived',hue='IsFemale',data=figdata,kind='bar')
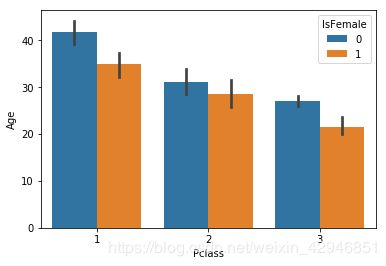
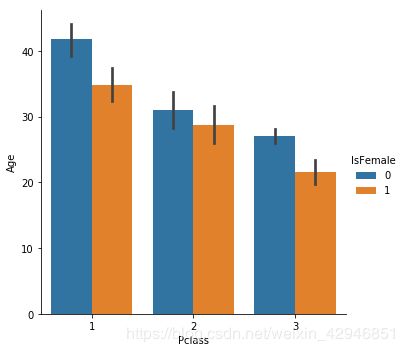
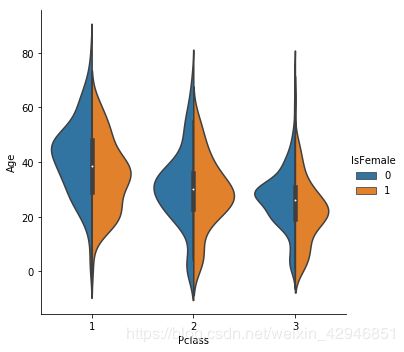
##分类-分类-数值,和上面类似,y轴为数值变量,y轴的表现形式很多,不过无外乎两类,一类是描述性统计(箱型图和均值方差图),一类是概率分布图(小提琴)
sns.barplot('Pclass','Age',hue='IsFemale',data=figdata)
sns.catplot('Pclass','Age',hue='IsFemale',data=figdata,kind='bar')
sns.catplot('Pclass','Age',hue='IsFemale',data=figdata,kind='violin',split=True)
sns.catplot('Pclass','Age',hue='IsFemale',data=figdata,kind='box')
##分类-数值-数值,这类的基础就是散点回归图了,然后再用hue进行区分
sns.lmplot('Age','Fare',hue='Survived',data=figdata)
##数值-数值-数值,这类的基础也是散点回归图,然后把hue换成数值变量就可以了,因为titanic中只有两个数值变量,我就不演示了

专题4.2、多个二维图像的分类表达
对于三维的数据,上面介绍的内容已经完全足够了,但是如果想表达出4维或者5维,甚至数据集所有维度的关系,那么就可以用到下面几个函数了:
1、sns.catplot,单张图的表现形式是x轴为分类变量,最多表现出五维数据,可以表现数值变量在0-1组;
2、sns.lmplot,单张图的表现形式是散点回归图,最多表现出5维数据,可以表现数值变量在2-3组;
3、sns.relplot,单张图的表现形式是散点图或者直线图,最多表现出六维数据,可以变现数值变量在2-4组,气泡图就能;
4、sns.FacetGrid,上面两者的统一形式,每张图可以灵活变化,但是至少有两维的分类变量,可以表现数值变量在0-3组;
5、sns.pairplot/sns.PairGrid,表现的维度理论上无上限,但是每一张只能是散点图,或者密度图,展示的是两两变量之间的关系。适用于对于整个数据集大体的了解。PairGrid的灵活性比pairplot要高,可以设置对角类型,非对角类型,具体的列,上下面的图表格式等等,具体查看其帮助文档。
6、sns.heatmap,再加一个混淆矩阵的画图吧,严格说,它本质上是分类-分类的一种特殊变现形式,因为一般的分类-分类数值之间并不存在直接的关系,但是它可以进行各分类的比较和数量统计。
#catplot绘图,这种多维度的绘图,能比较好的发现某一些子分组中的现象
sns.catplot(x='Embarked',y='Age',hue='Survived',row='Pclass',col='Sex',data=figdata,kind='bar')
#lmplot绘图
sns.lmplot(y='Fare',x='Age',hue='Survived',row='Pclass',col='Sex',data=figdata,fit_reg=False)
#relplot绘图
sns.relplot('Age','Fare',hue='Survived',size='Pclass',col='IsFemale',row='InCabin',data=figdata)
#FacetGrid绘图,一般都是先设定row和col,然后再用map定义每一个子图
grid=sns.FacetGrid(figdata,row='Pclass',col='Sex',hue='Survived')
grid.map(sns.distplot,'Age')
#pairplot/PairGrid绘图,这里例子最好看seaborn自带的例子哦,titanic上的数据展示的比较凌乱
sns.pairplot(figdata,hue='Survived',vars=['Age','Fare','Pclass'])
#headmap绘图,headmap主要用于检验预测结果和实际结果之间的差别,我就用seaborn上的例子给大家解释展示一下哈。
uniform_data = np.random.rand(10, 12)
ax = sns.heatmap(uniform_data)
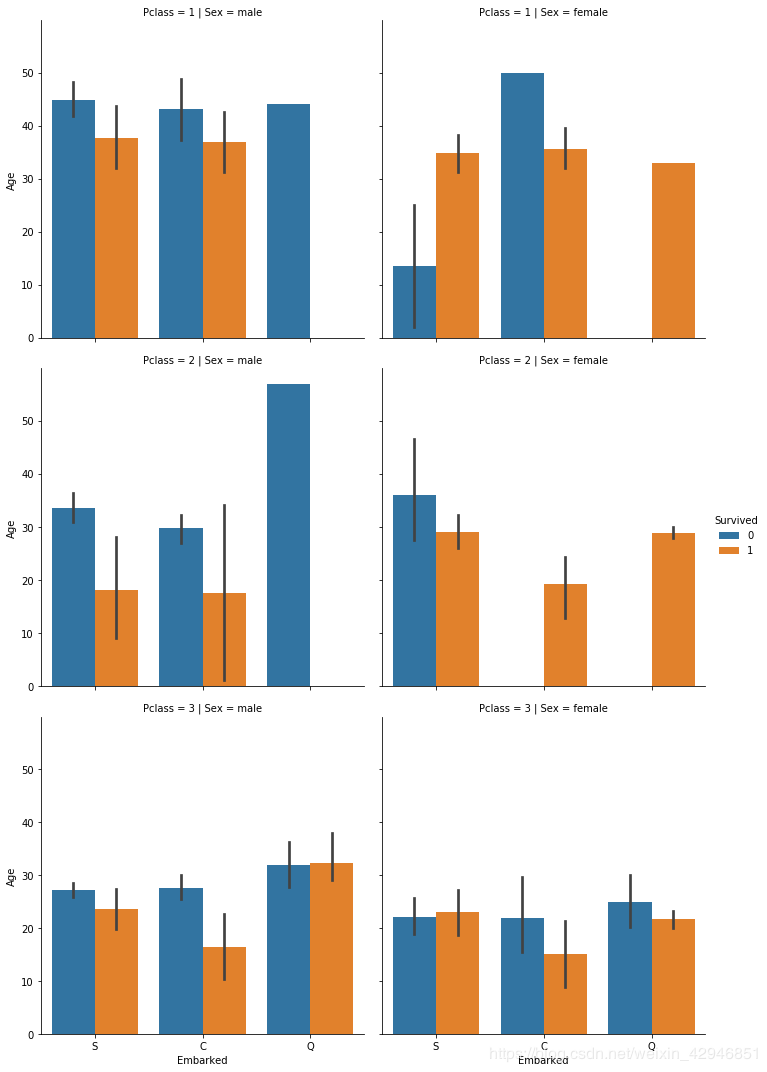
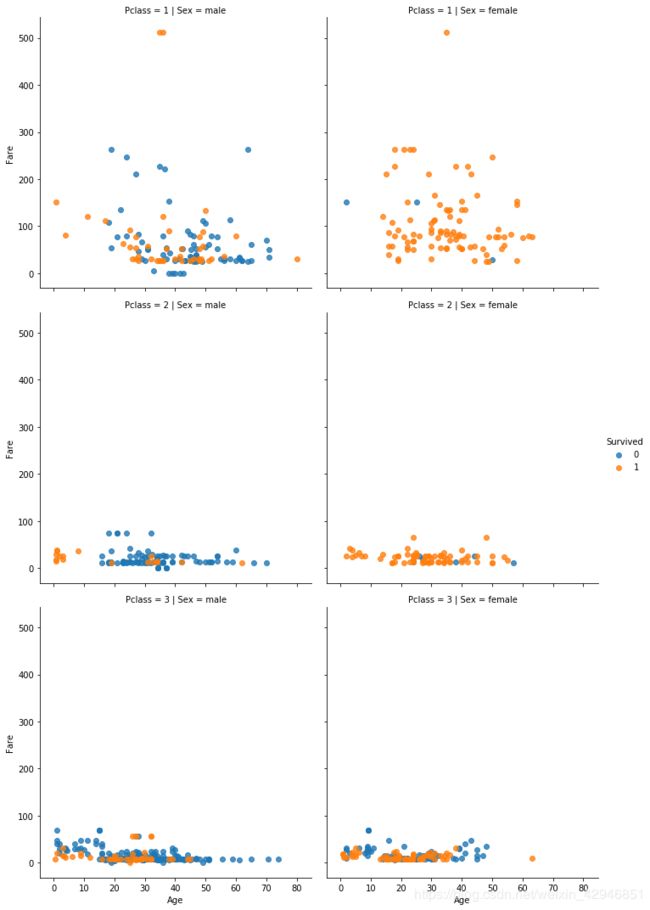


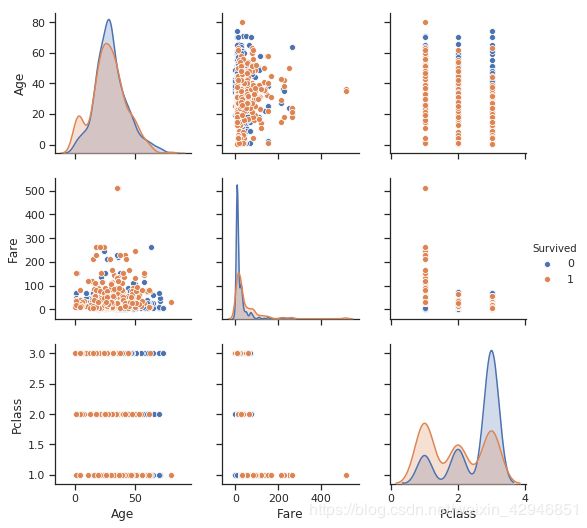
最后提示一下大家,绘图刚开始跟着一些数据分析的书本学,到了后面就可以自己直接利用帮助文档,里面的例子很详细,是自学最好的方式之一了,在IPython中,直接输入函数名,加上?号就能出来。
#5、特征工程
特征工程主要包含两个方面:
1、将原数据集转换成,机器学习能读懂,且容易理解的格式
2、通过特定的方式,选出最优的特征组合
##5.1、特征工程转换
其实之前的数据转换工作已经涉及到了部分的特征工程转换,比如说将字符串转换成离散的数值变量,将字符串One-Hot化。
主要的机器能读懂的格式之前介绍过,这里简单回顾一下:
1、连续的数值变量
2、离散的数值变量
3、布尔变量
那么根据以上格式,主要的特征工程转换分为下面几种:
1、字符串处理收集后,变成上面其中的一种
2、离散的数值变量One-Hot成布尔变量
3、连续的数值变量,分箱成离散的数值变量
4、连续的数值变量转化成多项式形式
5、连续的数值变量由线性变为非线性。
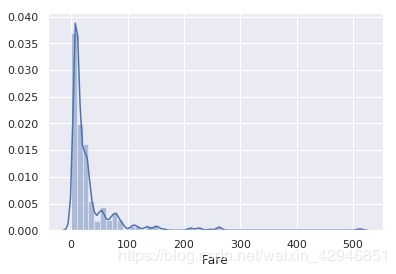
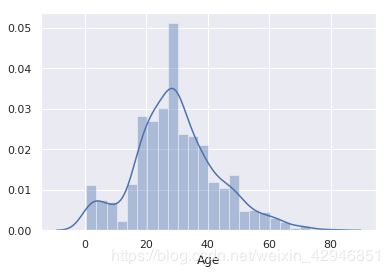
第一种和第二种我们都已经处理了,下面我们对Fare和Age进行第三种的处理。
#先看一下Fare和Age的密度分布情况
sns.distplot(train.Fare)
sns.distplot(train.Age)
#对于Fare,我们可以按照数量的百分位数进行划分,对于Age,因为它比较接近正态分布,我们可以根据Age的值进行划分。
for data in combine:
data['Age_Bins']=pd.cut(data.Age,10,labels=range(0,10))
data['Fare_Bins']=pd.qcut(data.Fare,10,labels=range(0,10))
#看一下分完之后幸存率的情况
sns.catplot('Fare_Bins',hue='Survived',data=train,kind='count')
sns.catplot('Age_Bins',hue='Survived',data=train,kind='count')

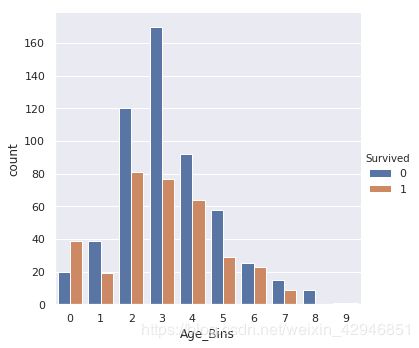
第四步和第五步,因为主要是用于线性和非线性的模拟,我们这里就不做处理,到目前为止,我们把基本的特征工程都处理好了。下一步就是对于特征的选择过程。
##5.2、特征工程选择
特征工程的选择一般分为三种情况:
1、单变量统计:就是比较单个变量和目标变量的相关性
2、基于模型的特征选择:根据各个模型,选出对结果影响最大的一定特征工程
3、迭代特征选择:第一种是,先从一个特征开始,构建模型,然后一个个添加模型量,直到满足某个条件终止;第二种是,先从全部模型开始,一个个减少,直到满足某个条件终止。
##先额外添件一个名字长度的字段,因为也是边学习边在整理,觉得这个字段还是挺重要的。
train['Name']=train_raw.Name
test['Name']=test_raw.Name
train['Name_Len']=train.Name.apply(len)
test['Name_Len']=test.Name.apply(len)
train['Name_Len_Bins']=pd.qcut(train.Name_Len,10,labels=range(0,10))
test['Name_Len_Bins']=pd.qcut(test.Name_Len,10,labels=range(0,10))
train.drop('Name',axis=1,inplace=True)
test.drop('Name',axis=1,inplace=True)
#将变量的数值类型统一转换
train.Age_Bins=train.Age_Bins.astype(int)
train.Fare_Bins=train.Fare_Bins.astype(int)
train.Name_Len_Bins=train.Name_Len_Bins.astype(int)
test.Age_Bins=test.Age_Bins.astype(int)
test.Fare_Bins=test.Fare_Bins.astype(int)
test.Name_Len_Bins=test.Name_Len_Bins.astype(int)
#最后发现,One-Hot化后的数据,对于不适用于树的模型,所以需要再建立一个没有稀疏矩阵的数据集
train_without_dummies=train[['Age','SibSp','Parch','Fare','IsFemale','InCabin','Age_Bins','Fare_Bins','Name_Len','Name_Len_Bins']]
test_without_dummies=test[['Age','SibSp','Parch','Fare','IsFemale','InCabin','Age_Bins','Fare_Bins','Name_Len','Name_Len_Bins']]
train_without_dummies['Pclass']=train_before_get_dummies.Pclass
test_without_dummies['Pclass']=test_before_get_dummies.Pclass
train_without_dummies['Family_groups']=train_before_get_dummies.Family_groups
test_without_dummies['Family_groups']=test_before_get_dummies.Family_groups
train_without_dummies['Embarked']=train_before_get_dummies.Embarked
test_without_dummies['Embarked']=test_before_get_dummies.Embarked
train_without_dummies['Title']=train_before_get_dummies.Title
test_without_dummies['Title']=test_before_get_dummies.Title
train_without_dummies['NTickets_groups']=train_before_get_dummies.NTickets_groups
test_without_dummies['NTickets_groups']=test_before_get_dummies.NTickets_groups
#然后再对这四个object对象使用LabelEncoder
label=LabelEncoder()
train_without_dummies['Family_groups_Code']=label.fit_transform(train_without_dummies.Family_groups)
train_without_dummies.drop('Family_groups',axis=1,inplace=True)
test_without_dummies['Family_groups_Code']=label.fit_transform(test_without_dummies.Family_groups)
test_without_dummies.drop('Family_groups',axis=1,inplace=True)
train_without_dummies['Embarked_Code']=label.fit_transform(train_without_dummies.Embarked)
train_without_dummies.drop('Embarked',axis=1,inplace=True)
test_without_dummies['Embarked_Code']=label.fit_transform(test_without_dummies.Embarked)
test_without_dummies.drop('Embarked',axis=1,inplace=True)
train_without_dummies['Title_Code']=label.fit_transform(train_without_dummies.Title)
train_without_dummies.drop('Title',axis=1,inplace=True)
test_without_dummies['Title_Code']=label.fit_transform(test_without_dummies.Title)
test_without_dummies.drop('Title',axis=1,inplace=True)
train_without_dummies['NTickets_groups_Code']=label.fit_transform(train_without_dummies.NTickets_groups)
train_without_dummies.drop('NTickets_groups',axis=1,inplace=True)
test_without_dummies['NTickets_groups_Code']=label.fit_transform(test_without_dummies.NTickets_groups)
test_without_dummies.drop('NTickets_groups',axis=1,inplace=True)
#重新把变量标签换一下
train_dummies=train.copy()
train=train_without_dummies
test_dummies=test.copy()
test=test_without_dummies
predictors_dummies=predictors.copy()
predictors_dummies_Bins=predictors_Bins.copy()
predictors_dummies_noSP=predictors_noSP.copy()
predictors_dummies_Num=predictors_Num.copy()
predictors=train.columns
predictors_Bins=predictors.drop(['Age','Fare','Name_Len'])
predictors_noSP=predictors_Bins.drop(['SibSp','Parch'])
predictors_Num=predictors.drop(['Age_Bins','Fare_Bins','Name_Len_Bins'])
ntrain=train.shape[0]
ntest=test.shape[0]
seed=0
NFolds=5
kf=KFold(n_splits=NFolds,random_state=seed)
#定义辅助类
class SklearnHelper(object):
def __init__(self,clf,seed=0,params=None):
params['random_state']=seed
self.clf=clf(**params)
def train(self,x_train,y_train):
self.clf.fit(x_train,y_train)
def predict(self,x):
return self.clf.predict(x)
def fit(self,x,y):
return self.clf.fit(x,y)
def feature_importances(self,x,y):
print(self.clf.fit(x,y).feature_importances_)
#定义模型融合子集函数
def get_oof(clf,x_train,y_train,x_test):
oof_train=np.zeros((ntrain,))
oof_test=np.zeros((ntest,))
oof_test_skf=np.empty((NFolds,ntest))
for i,(train_index,test_index) in enumerate(kf.split(x_train)):
x_tr=x_train[train_index]
y_tr=y_train[train_index]
x_te=x_train[test_index]
clf.train(x_tr,y_tr)
oof_train[test_index]=clf.predict(x_te)
oof_test_skf[i,:]=clf.predict(x_test)
oof_test[:]=oof_test_skf.mean(axis=0)
return oof_train.reshape(-1,1),oof_test.reshape(-1,1)
params_rf={'n_estimators':500,'warm_start':True,'max_depth':6,'min_samples_leaf':2,'max_features':'sqrt','verbose':0}
params_et={'n_estimators':500,'max_depth':8,'min_samples_leaf':2,'verbose':0}
params_ada={'n_estimators':500,'learning_rate':0.75}
params_gb={'n_estimators':500,'max_depth':5,'min_samples_leaf':2,'verbose':0}
params_svc={'kernel':'rbf','C':0.025}
rf=SklearnHelper(clf=RandomForestClassifier,seed=seed,params=params_rf)
et=SklearnHelper(clf=ExtraTreesClassifier,seed=seed,params=params_et)
ada=SklearnHelper(clf=AdaBoostClassifier,seed=seed,params=params_ada)
gb=SklearnHelper(clf=GradientBoostingClassifier,seed=seed,params=params_gb)
svc=SklearnHelper(clf=SVC,seed=seed,params=params_svc)
y_train=train['Survived'].ravel()
train=train.drop('Survived',axis=1)
x_train=train.values
x_test=test.values
et_oof_train,et_oof_test=get_oof(et,x_train,y_train,x_test)
rf_oof_train,rf_oof_test=get_oof(rf,x_train,y_train,x_test)
ada_oof_train,ada_oof_test=get_oof(ada,x_train,y_train,x_test)
gb_oof_train,gb_oof_test=get_oof(gb,x_train,y_train,x_test)
svc_oof_train,svc_oof_test=get_oof(et,x_train,y_train,x_test)
1、titanic-data-science-solutions
亮点:Kaggle上泰坦尼克号项目的入门kernel,主要讲的是机器学习的基本步骤,适合刚做项目没有经验的朋友
2、a-data-science-framework-to-achieve-99-accuracy
亮点:Kaggle上该项目应该算最详细的介绍,里面有自动化特征选择,利用网格搜索进行模型选择及参数调优,二分类指标介绍以及投票评估器
3、introduction-to-ensembling-stacking-in-python
亮点:目前Kaggle上最受欢迎的泰坦尼克号项目kernel,如题,讲的主要是模型融合Stacking的操作
4、大树先生的泰坦尼克号分析
亮点:这篇博文,我收获最多的,是他关于模型融合的介绍,当然还有一些小技巧。
5、Kaggle泰坦尼克预测(完整分析)-珠穆朗玛峰
亮点:里面反复强调了对于数据分析来说最重要的几个点,大家去看看哈。
6、Kaggle泰坦尼克号生存模型——250个特征量的融合模型,排名8%
亮点:里面的对各个模型前几的特征筛选值得大家借鉴。
7、机器学习(二) 如何做到Kaggle排名前2%
亮点:作者使用R语言做的,但是里面的特征工程处理是值得大家借鉴的。
8、分分钟带你杀入Kaggle Top 1%
亮点:这篇博文是从理论上讲解了机器学习的全过程,不过主要是方法论上的,没有具体的项目,和代码。