决策树实战系列(一)——泰坦尼克号生还预测
1. 下载数据集
链接:https://pan.baidu.com/s/1Z570Ri3d2UMEPP2Nz-Q1lw
提取码:mfof
2.代码实现
2.1 引包
[1]:import pandas as pd
import numpy as np
from sklearn.tree import DecisionTreeClassifier # 分类树
import matplotlib.pyplot as plt # 画图
from sklearn.model_selection import GridSearchCV,cross_val_score # 网格搜索,交叉验证
from sklearn.model_selection import train_test_split # 切分训练集和测试集
2.2 读取数据
[2]:data = pd.read_csv("E:/project_data/train.csv")
2.3 分析数据
该训练集共有12列数据,其中包含11个特征feature和一个标签label(Survived )。其中英文对照表如下:
| PassengerId | 乘客ID |
| Survived | 存活情况 |
| Pclass | 客舱等级 |
| Name | 乘客姓名 |
| Sex | 性别 |
| Age | 年龄 |
| SibSp | 同代直系亲属人数 |
| Parch | 不同代直系亲属人数 |
| Ticket | 船票编号 |
| Fare | 票价 |
| Cabin | 船舱号 |
| Embarked | 登船港口 |
[3]:data.head()

info()此方法显示有关DataFrame的信息,包括索引dtype和列dtype,非空值和内存使用情况。从结果中可以看出包含缺失值的特征有Age,Cabin,Embarked,所以我们需要对缺失值进行预处理。
[4]:data.info()

2.4 数据预处理
2.4.1 特征筛选
在所有的特征中,根据我们的生活经验知道,其中一些特征对乘客是否能够存活几乎没什么帮助。比如姓名和船票编号,不可能因为你很出名以及你编号比较好,就能优先上救生艇。且由于船舱号缺失量确实比例很高,于是我们将这三个特征删除。
[5]:data.drop(["Name","Cabin","Ticket"],inplace = True,axis=1)
[6]:data.head()
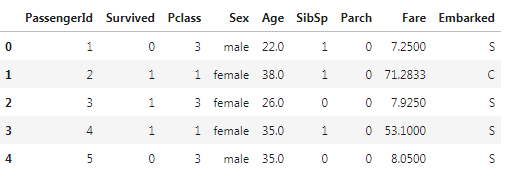
2.4.2 处理缺失值
对于含有缺失值的特征,通常有三种处理方法:
- 直接删除
- 填补缺失值
- 直接使用
对于Cabin这个特征,由于其缺失比例太高,所以我们使用第一种方法,直接删除该特征。但是对于Age,缺失值不多且较为重要。所以我们对于Age使用均值填补;Embarked只是缺失两个,所以我们删除缺失值所在的两行即可,对整体数据影响不大。
[7]:data["Age"] = data["Age"].fillna(data["Age"].mean())
data.info()

[8]:data.dropna(inplace=True)
data.info()
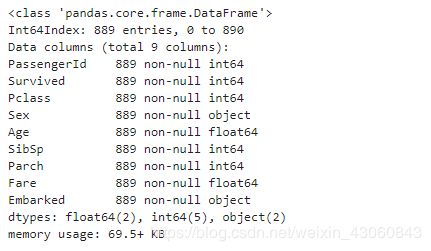
2.4.3 特征转换
由于sklearn中,决策树模型只能处理数字以及数据的类别,所以对字符串我们需要进行特征转换.
[9]:labels = data["Embarked"].unique().tolist()
labels
![]()
[10]:data["Embarked"] = data["Embarked"].apply(lambda x:labels.index(x))
data.head()
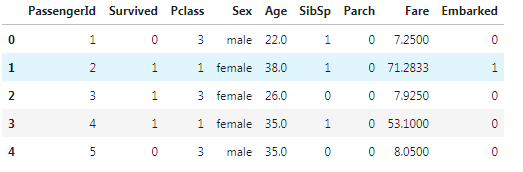
[11]:data["Sex"] = (data["Sex"] == "male").astype("int")
data.head()
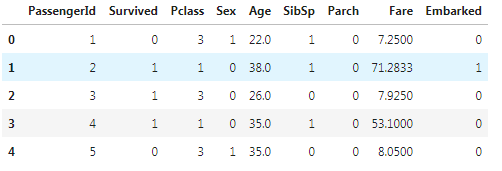
2.4.4 切分训练集和测试集
[12]:x = data.iloc[:,data.columns!="Survived"]
y = data.iloc[:,data.columns == "Survived"]
[13]:Xtrain,Xtest,Ytrain,Ytest = train_test_split(x,y,test_size = 0.3)
在切分数据集之后,index是混乱的。虽然在决策树算法中并没有影响,但是当我们使用其他模型需要使用到index时,会发生错误。所以养成习惯,每次切分完训练集和数据集,需要回复顺序索引。
[14]:for i in [Xtrain,Xtest,Ytrain,Ytest]:
i.index = range(i.shape[0])
2.5 模型构建
2.5.1 无参数建模
[15]:clf = DecisionTreeClassifier(random_state=25)
clf = clf.fit(Xtrain,Ytrain)
score = clf.score(Xtest,Ytest)
score
0.7565543071161048
2.5.2 交叉验证
[16]:clf = DecisionTreeClassifier(random_state=30)
score = cross_val_score(clf,x,y,cv=10).mean()
score
0.7514683350357507
2.5.3 使用max_depth调参
[17]:clf = DecisionTreeClassifier(random_state=30,max_depth=5)
score = cross_val_score(clf,x,y,cv=10).mean()
score
0.7941905005107252
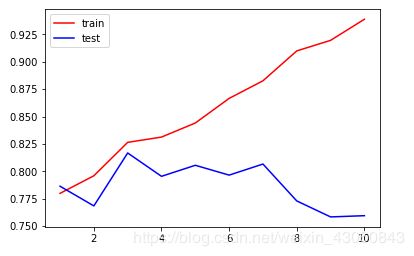
2.5.3 绘制max_depth超参数学习曲线
[18]:tr = []
te = []
for i in range(10):
clf = DecisionTreeClassifier(random_state=25,max_depth=i+1,criterion="entropy")
clf = clf.fit(Xtrain,Ytrain)
score_tr = clf.score(Xtrain,Ytrain)
score_te = cross_val_score(clf,x,y,cv=10).mean()
tr.append(score_tr)
te.append(score_te)
print(max(te))
plt.plot(range(1,11),tr,color = "red",label="train")
plt.plot(range(1,11),te,color = "blue",label = "test")
plt.legend()
plt.show()
0.8166624106230849
2.5.4 网格搜索
上面我们只是通过学习曲线找到了一个参数的最佳值,那么每一个参数都需要这样一条一条绘制学习曲线吗?sklearn为我们提供了网格搜索GridSearchCV,这个方法可以找出多个参数在各自的范围内组合后模型最好的参数。
[19]:parameters = {
"min_samples_leaf":[*range(1,50,5)],
"min_impurity_decrease":[*np.linspace(0,0.5,50)]
}
clf = DecisionTreeClassifier(random_state=25,max_depth=3)
GS = GridSearchCV(clf,parameters,cv=10)
GS = GS.fit(Xtrain,Ytrain)
best_score_属性会返回在我们给出的参数选值内,模型效果最好的那组得到的模型准确率。
[20]:GS.best_score_
0.8006430868167203
best_params_属性会返回在我们给出的参数选值内,模型效果最好的那组使用的参数信息。
[21]:GS.best_params_
{‘min_impurity_decrease’: 0.0, ‘min_samples_leaf’: 16}
2.5.5 使用最优参数训练模型并绘制树形图
[22]:clf = DecisionTreeClassifier(random_state=25,max_depth=3,criterion="entropy",min_samples_leaf=16,min_impurity_decrease=0)
clf = clf.fit(Xtrain,Ytrain)
score = clf.score(Xtest,Ytest)
score
0.7752808988764045
绘制树形图
[22]:import graphviz
from sklearn import tree
dot_data = tree.export_graphviz(clf,out_file=None,feature_names=feature_name,filled=True,rounded=True)
graph = graphviz.Source(dot_data)
graph

2.6 总结
由于此数据集更多是用来熟悉数据处理以及决策树建模流程,所以准确率并不用太过于纠结。之后会使用决策树做隐形眼镜数据预测以及球队胜率预测,感觉有帮助可以关注一下!!!
系列文章:
机器学习系列——决策树(一)
参考资料:
菜菜的sklearn