字体反爬虫处理猫眼(数字)
环境:Windows7 +Python3.6+Pycharm2017
目标:猫眼电影票房
前言:字体反爬,也是一种常见的反爬技术,例如猫眼电影票房,汽车之家,天眼查等网站。这些网站采用了自定义的字体文件,在浏览器上正常显示,但是爬虫抓取下来的数据要么就是乱码,要么就是变成其他字符。采用自定义字体文件是CSS3的新特性,详情参考 CSS3字体
一、猫眼电影
打开猫眼电影票房 https://piaofang.maoyan.com/?ver=normal ,打开浏览器开发者模式,可以看到这些票房数据在HTML代码中是显示不了的。
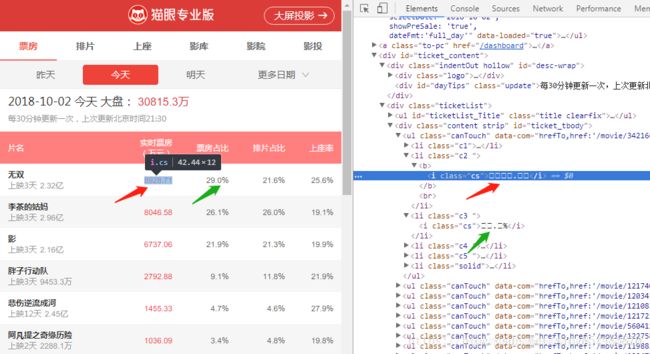
点击上图右上角的Sources,把这个html文档下载下来,在编辑器打开,就可以看到这些方框对应的是一个个编码,这些编码是自定义的,所以用utf-8编码方式是显示不出来的。浏览器显示的时候因为采用了自定义的字体文件,所以显示正常。
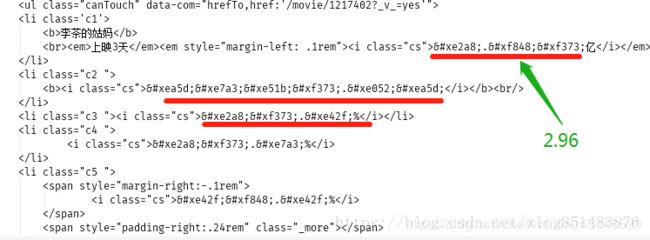
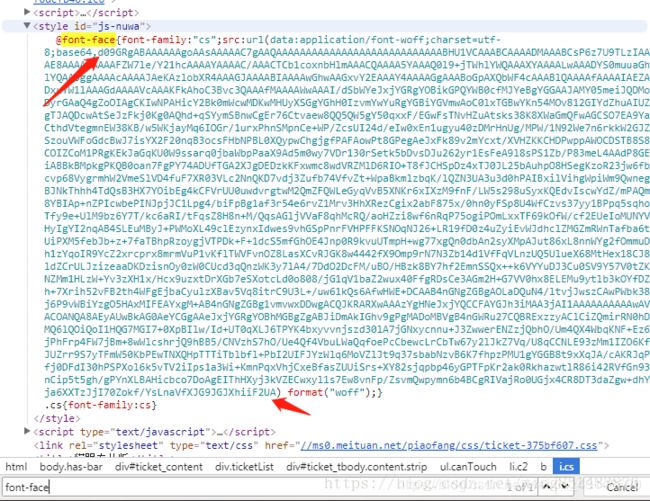
我们来找一下这个字体文件 ,在html页面中搜索关键字:font-face,找到如下内容。一大串字符串,从base64后面开始一直到后面format前面的括号中的内容,应该是字体文件的内容。是经过了base64编码后的形式。把这一段字符串考出来,用base64解码后再保存成本地ttf文件(ttf是字体的一种类型)。
处理代码如下,先解码,再保存成本地文件 zt02.ttf:
import base64
font_face='d09GRgABAAAAAAgoAAsAAAAAC7gAAQAAAAAAAAAAAAAAAAAAAAAAAAAAAABHU1VCAAABCAAAADMAAABCsP6z7U9TLzIAAAE8AAAARAAAAFZW7le/Y21hcAAAAYAAAAC/AAACTCb1coxnbHlmAAACQAAAA5YAAAQ0l9+jTWhlYWQAAAXYAAAALwAAADYS0muuaGhlYQAABggAAAAcAAAAJAeKAzlobXR4AAAGJAAAABIAAAAwGhwAAGxvY2EAAAY4AAAAGgAAABoGpAXQbWF4cAAABlQAAAAfAAAAIAEZADxuYW1lAAAGdAAAAVcAAAKFkAhoC3Bvc3QAAAfMAAAAWwAAAI/dSbWYeJxjYGRgYOBikGPQYWB0cfMJYeBgYGGAAJAMY05meiJQDMoDyrGAaQ4gZoOIAgCKIwNPAHicY2Bk0mWcwMDKwMHUyXSGgYGhH0IzvmYwYuRgYGBiYGVmwAoC0lxTGBwYKn54MOv812GIYdZhuAIUZgTJAQDcwAtSeJzFkj0Kg0AQhd+qSYymSBnwCgEr76Ctvaew8QQ5QW5gY50qxxF/EGwFsTNvHZuAtsks38K8XWaGmQFwAGCSO7EA9YaCthdVtegmnEW38KB/w5WKjayMq6IOGr/1urxPhnSMpnCe+WP/ZcsUI24d/eIw0xEn1ugyu40zDMrHnUg/MPW/1N92We7n6rkkW2GJZSzouVWFoGdcBwJ7isYX2F20nqB3ocsFHbNPBL0XQypwChgjgfPAFAowPt8GPegAeJxFk89v2mYcxt/XVHZKKCHDPwppAWOCDSTB8S8COIZCoM1PRgKEkJaGqKU0W9ssarq0jbaWbpPaaX9Ad5m0wy7VDr130rSetk5bDvsDJu262yr1EsFeA9l8sPS1Zb/P83meL4AAdP8GEiABBkBMpkgPKQB0oan7FgPY74ADUfTGA2XJgDEDzkKFxwmc8wdVRZMlD6RIO+T8fJCHSpDz4xTJ0JL25bAuhpO8HSegKzoR23jw6fbcvp68VygrmhW2VmeSlVD4fuF7XR03VLc2NnQKD7vdj3Zufb74VfvZt+WpaBkmlzbqK/lQZN3UA3u3d0hPAIBxilVihgWpiWm9QwnegBJNkThhh4TdQsB3HX7YOibEg4kCFVrUU0uwdvrgtwM2QmZFQWLeGyqVvB5XNKr6xIXzM9fnF/LW5s298uSyxKQEdvIscwYdZ/mPAQm8YBIAp+nZPIcwbePINJpjJC1Lpg4/biFpBg1af3r54e6rvZ1Mrv3HhXRezCgix2abF875x/0hn0yFSp8U4WfCzvs37yy1BPpq5sqhoTfy9e+UlM9bz6Y7T/kc6aRI/tFqsZ8H8n+M/QqsAGljVVaF8qhMcRQ/aoHZzi8wf6nRqP75ogiPOmLxxTF69kOfW/cf2EUeIoMUNYVHyIgYI2nqAB4SLEuMByJ+PWMoXL49clEzynxIdwes9vhGSpPnrFVHPFFKSNOqNJ26+LR19fD0z4uZyiEvWJdhclZMGZmRWnTafba6tUiPXM5febJb+z+7faTBhpRzoygjVTPDk+F+1dcS5mfGhOE4Jnp0R9kvuUTmpH+wg77xgQn0dbAn2syXMpAJut86xL8nnWYg2fOmmuDh1zYqoIR9YcZ2xrcprx8mrmVuP1vKflTWVFvnOZ8LasXCvRJGK8w4442fX9Omp9rN7N3Zb14d1VfFqVLnzUQ5UlueX68MtHex18CJ8ldZCrULJzizeaaDKDzisnOy0zW0CUcd3qQnzWK3y7lA4/7DdO2DcFM/uBO/HBzk8BY7hf2EmnSSQx++k6VYYuDJ3Cu0SV9Y57V0tZKNZMm1HLzW+Yv3zXH1x/Hcx9uzxtDrXGb7eSXotcLd0o808/jG1qV1baZ2wux40FfgRDsCe3AGm2H+G7VV0hx8ELEMu9ytlb3kOYfDZh+7Xrih52vFB2th4WFgEjbaCyulzXBav5Vq8itrC9U3L+/uw61kQs6AfwHWE+DCAAB4nGNgZGBgAOLaDQuN4/ltvjJwszCAwPWbk38j6P9vWBiYzgO5HAxMIFEAYxgM+AB4nGNgZGBg1vmvwxDDwgACQJKRARXwAAAzYgHNeJxjYQCCFAYGJh3iMAA3jAI1AAAAAAAAAAwAVACOANQA8AEyAUwBkAG0AeYCGgAAeJxjYGRgYOBhMGBgZgABJiDmAkIGhv9gPgMADoMBVgB4nGWRu27CQBRExzzyAClCiZQmirRN0hDMQ6lQOiQoI1HQG7MGI7+0XpBIlw/Id+UT0qXLJ6TPYK4bxyvvnjszd30lA7jGNxycnnu+J3ZwwerENZzjQbhO/Um4QX4WbqKNF+Ez6jPhFrp4FW7jBm+8wWlcshrjQ9hBB5/CNVzhS7hO/Ue4Qf4VbuLWaQqfoePcCbewcLrCbTw67y2lJkZ7Vq/U8qCCNLE93zMm1IZO6KfJUZrr9S7yTFmW50KbPEwTNXQHpTTTiTblbfl+PbI2UIFJYzWlq6MoVZlJt9q37sbabNzvB6K7fhpzPMU1gYGGB8t9xXqJA/cAKRJqPfj0DFdI30hPSPXol6k5vTV2iIps1a3Wi+KmnPqxVhjCxeBfasZUUiSrs+XY82sjqpbp46yGPTFpKr2ak0RkhazwtlR86i42RVfGn93nCip5t5gh/gPYnXLBAHicbco7DoAgEIThHXyj3kVZECwxyl1s7Ew8vnFp/ZsvmQwpymn6b4BCgRIVajRo0UGjx4CR8DT3daZgw+dhYja6XXTzJjI70Zokf/YsLnaVfXJG9JGJXhiiF2UA'
b=base64.b64decode(font_face)
with open('zt02.ttf','wb')as f:
f.write(b)
接下来我们要查看和处理这个字体文件,这里要用到两个工具。一个是软件 FontCreator,可以直接打开ttf字体文件,查看每一个字符对应的编码。还有一个是python第三方库fontTools,借助这个库可以用python代码来操作ttf文件。
FontCreator安装:
安装包下载地址 :链接:https://pan.baidu.com/s/1zKIr7EcGlMSSF6e9Z6IZmw 提取码:d4gm (如果无效的话自己百度下)
安装好后,不用激活也能免费试用30天,Use Evaluation Version 。然后点击左上角打开文件,打开我们上面保存的zt02.ttf文件。
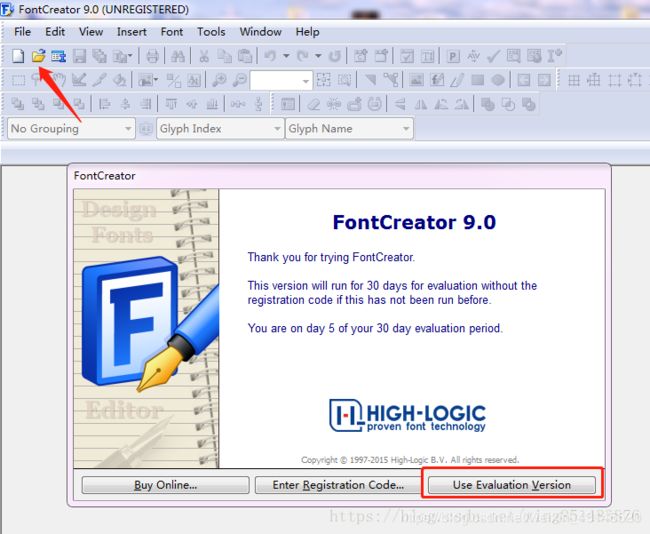
打开后看到如下界面,可以看到数字2 9 6上面的编码和我们之前html中看到的编码是一致的。
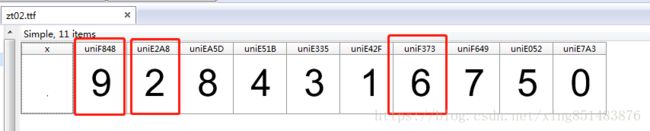

思路分析
这里补充一点就是你每次访问加载的字体文件中的字符的编码可能是变化的,就是说网站有多套的字体文件。
既然编码是不固定的,那就不能用编码的一一对应关系来处理字体反爬。这里要用到上面说的三方库fontTools,利用fontTools可以获取每一个字符对象,这个对象你可以简单的理解为保存着这个字符的形状信息。而且编码可以作为这个对象的id,具有一一对应的关系。像猫眼电影,虽然字符的编码是变化的,但是字符的形状是不变的,也就是说这个对象是不变的。
基本思路:先下载一个字体文件保存到本地(比如叫01.ttf),人工的找出每一个数字对应的编码。当我们重新访问网页时,同样也可以把新的字体文件下载下来保存到本地ttf(比如叫02.ttf)。网页中的一个数字的编码比如为AAAA,如何确定AAAA对应的数字。我们先通过编码AAAA找到这个字符在02.ttf中的对象,并且把它和01.ttf中的对象逐个对比,直到找到相同的对象,然后获取这个对象在01.ttf中的编码,再通过编码确认是哪个数字。
具体实现:
先安装 fontTools,应该是直接 pip install fonttools 就可以
基本命令介绍:
from fontTools.ttLib import TTFont
font=TTFont('01.ttf') #打开本地字体文件01.ttf
font.saveXML('01.xml') #将ttf文件转化成xml格式并保存到本地,主要是方便我们查看内部数据结构
先把字体文件转化成xml格式,以便打开查看里面的数据结构。打开xml文件可以看到类似html标签的结构。这里我们用到的标签是
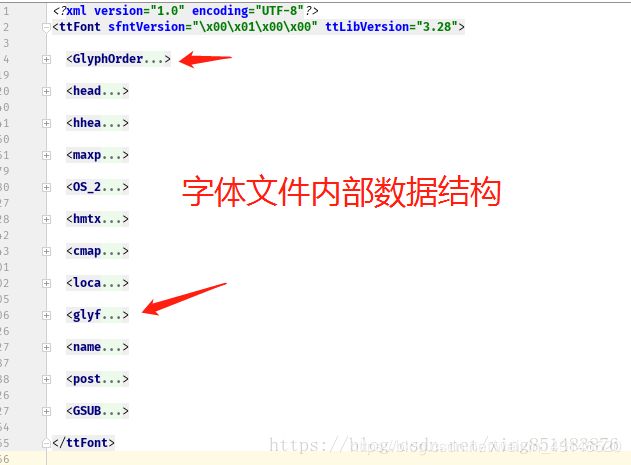
点开标签内部,
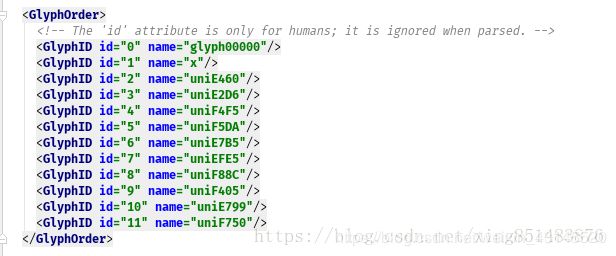

点开对象,里面的信息如下,是一些坐标点的信息,可以联想到这些点应该是描绘字体形状的,后面再讲。

实现步骤:先在本地保存字体文件01.ttf,并手动确认编码和数字的对应关系,保存到字典中。然后重新访问网页的时候,把网页中新的字体文件也下载保存到本地02.ttf。对于02中的编码uni2,先获取uni2的对象obj2,与01中的每一个对象注逐一对比,直到找到相同的对象obj1,再根据obj1的编码,在字典中找到对应的数字。
获取猫眼数据完整代码:
import requests
from fontTools.ttLib import TTFont
from lxml import etree
import lxml.html as H
import base64
import re
#破解猫眼数据字体加密
url='https://piaofang.maoyan.com/?ver=normal'
headers={"User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36"}
#获取猫眼字体库
def ziti_ku():
response=requests.get(url,headers=headers)
session = requests.session()
con = session.get(url, headers=headers)
doc = H.document_fromstring(con.content)
#用正则匹配获取字体代码(记得改变格式.decode('utf-8'))
font_data_origin = re.search(r'base64,(.*?)\)', con.content.decode('utf-8'), re.S).group(1)
font_data_after_decode = base64.b64decode(font_data_origin)
#创建字体文件
new_font_name = "maoyan1.ttf"
with open(new_font_name, 'wb') as f:
f.write(font_data_after_decode)
#新旧字体对照表,方便破解字体加密使用
def duizhao_biao():
font1 = TTFont('zt02.ttf') # 打开本地字体文件zt02.ttf
obj_list1 = font1.getGlyphNames()[1:-1] ##获取所有字符的对象,去除第一个和最后一个
uni_list1 = font1.getGlyphOrder()[2:] # 获取所有编码,去除前两个
# 手动确认编码和数字之间的对应关系,保存到字典中
dict = {'uniE624': '4', 'uniE219': '7', 'uniEE6C': '2', 'uniE5F8': '8', 'uniEA0C': '5', 'uniE32A': '3',
'uniE0F1': '9', 'uniE1CC': '6', 'uniF24D': '0', 'uniF842': '1'}
font2 = TTFont('maoyan1.ttf') # 打开访问网页新获取的文字字体maoyan.ttf
obj_list2 = font2.getGlyphNames()[1:-1]
uni_list2 = font2.getGlyphOrder()[2:]
for uni2 in uni_list2:
obj2 = font2['glyf'][uni2] # 获取编码uni2在02.ttf中对用的对象
for uni1 in uni_list1:
obj1 = font1['glyf'][uni1]
if obj1 == obj2:
print(uni2, dict[uni1]) # 打印结果,编码uni2和对应的数字
#字体加密破解
def zhiti_transfrom():
##=================分析出新旧字体库对应码======================================================
font1 = TTFont('zt02.ttf') # 打开本地字体文件zt02.ttf
obj_list1 = font1.getGlyphNames()[1:-1] ##获取所有字符的对象,去除第一个和最后一个
uni_list1 = font1.getGlyphOrder()[2:] # 获取所有编码,去除前两个
# 手动确认编码和数字之间的对应关系,保存到字典中
dict = {'uniE624': '4', 'uniE219': '7', 'uniEE6C': '2', 'uniE5F8': '8', 'uniEA0C': '5', 'uniE32A': '3',
'uniE0F1': '9', 'uniE1CC': '6', 'uniF24D': '0', 'uniF842': '1'}
font2 = TTFont('maoyan1.ttf') # 打开访问网页新获取的文字字体maoyan.ttf
obj_list2 = font2.getGlyphNames()[1:-1]
uni_list2 = font2.getGlyphOrder()[2:]
for uni2 in uni_list2:
obj2 = font2['glyf'][uni2] # 获取编码uni2在02.ttf中对用的对象
for uni1 in uni_list1:
obj1 = font1['glyf'][uni1]
if obj1 == obj2:
print(uni2, dict[uni1]) # 打印结果,编码uni2和对应的数字
##================================对新的网页的数据进行字体解码======================================================
response=requests.get(url,headers=headers)
response.encoding=('utf-8')
html=response.text
html=etree.HTML(html)
content=html.xpath('//*[@id="ticket_tbody"]/ul')
for i in content:
film_name=i.xpath('li[1]/b/text()')[0] #电影名称
#==========================实时票房===========================
real_piaofang=i.xpath('li[2]/b/i/text()') #实时票房
real_piaofang=str(real_piaofang).replace('.','').replace("['",'').replace("']",'').replace('\\',',').strip(',').split(',')
t=len(real_piaofang)
a=[]
for t1 in range(t):
pf='uni'+real_piaofang[t1].replace('u','').upper()
obj2 = font2['glyf'][pf] # 获取编码uni2在02.ttf中对用的对象
for uni1 in uni_list1:
obj1 = font1['glyf'][uni1]
if obj1 == obj2:
d=dict[uni1]
# print(pf, dict[uni1]) # 打印结果,编码uni2和对应的数字
a.append(d)
real_piaofang=''.join(a)
real_piaofang=real_piaofang[:-2] +'.'+real_piaofang[-2:]
#===============================#票房占比============================================
piaofang_zb=i.xpath('li[3]/i/text()')
piaofang_zb = str(piaofang_zb).replace('.', '').replace("['", '').replace("']", '').replace('%','').replace('\\',',').strip( ',').split(',')
t = len(piaofang_zb)
a = []
for t1 in range(t):
pf = 'uni' + piaofang_zb[t1].replace('u', '').upper()
obj2 = font2['glyf'][pf] # 获取编码uni2在02.ttf中对用的对象
for uni1 in uni_list1:
obj1 = font1['glyf'][uni1]
if obj1 == obj2:
d = dict[uni1]
# print(pf, dict[uni1]) # 打印结果,编码uni2和对应的数字
a.append(d)
piaofang_zb = ''.join(a)
piaofang_zb = piaofang_zb[:-1] + '.' + piaofang_zb[-1:] +'%'
#=============================#排片占比======================================================
paipian_zb=i.xpath('li[4]/i/text()') #排片占比
paipian_zb = str(paipian_zb).replace('.', '').replace("['", '').replace("']", '').replace('%','').replace('\\', ',').strip( ',').split(',')
t = len(paipian_zb)
a = []
for t1 in range(t):
pf = 'uni' + paipian_zb[t1].replace('u', '').upper()
obj2 = font2['glyf'][pf] # 获取编码uni2在02.ttf中对用的对象
for uni1 in uni_list1:
obj1 = font1['glyf'][uni1]
if obj1 == obj2:
d = dict[uni1]
# print(pf, dict[uni1]) # 打印结果,编码uni2和对应的数字
a.append(d)
paipian_zb = ''.join(a)
paipian_zb = paipian_zb[:-1] + '.' + paipian_zb[-1:]+'%'
#==============================上座率====================================================
shangzl=i.xpath('li[5]/span[1]/i/text()') #上座率
shangzl = str(shangzl).replace('.', '').replace("['", '').replace("']", '').replace('%', '').replace('\\',',').strip(',').split(',')
t = len(shangzl)
a = []
for t1 in range(t):
pf = 'uni' + shangzl[t1].replace('u', '').upper()
obj2 = font2['glyf'][pf] # 获取编码uni2在02.ttf中对用的对象
for uni1 in uni_list1:
obj1 = font1['glyf'][uni1]
if obj1 == obj2:
d = dict[uni1]
# print(pf, dict[uni1]) # 打印结果,编码uni2和对应的数字
a.append(d)
shangzl = ''.join(a)
shangzl = shangzl[:-1] + '.' + shangzl[-1:] + '%'
print(film_name,real_piaofang,piaofang_zb,paipian_zb,shangzl)
if __name__=='__main__':
ziti_ku()
# duizhao_biao()
zhiti_transfrom()
作者:Mars_DD
来源:CSDN
原文:https://blog.csdn.net/xing851483876/article/details/82928607