机器学习笔记(七)——逻辑回归算法
逻辑回归(Logistic Regression,LR)。在Kaggle竞赛的统计中,LR算法以63.5%的出产率,荣获各领域中“出场率最高的算法”这一殊荣。在实际场景中,逻辑回归同样应用广泛,大到国家各项经济政策的制定,小到计算广告CTR,都能看到LR算的身影。
除了应用广泛外,LR的建模过程还体现了数据建模中很重要的思想:对问题划分层次,并利用非线性变换和线性模型的组合,将未知的复杂问题分解为已知的简单问题。因此,我们可以说:理解好逻辑回归的细节,就掌握了数据建模的精髓。
一、什么时候逻辑回归
1线性回归能解决分类问题么?
其实,线性回归是不能解决分类问题的。因为我们在使用线性回归模型时,我们实际上做了3个假设(实际上有更多的假设,这里只讨论最基本的三个):
- 因变量y_i和自变量x_i之间呈线性相关。
- 自变量x_i与干扰项ε_i相互独立。
- 没被线性模型捕捉到的随机因素ε_i服从正态分布。
从理论上来说,任何数据放在任何模型里都会得到相应的参数估计,进而通过模型对数据进行预测。但是这并不一定能保证模型效果,有时会得到“错且无用”的模型,因此建模的过程中需要不断提出假设和检验假设。
2.用逻辑回归解决分类问题
有些算法,表面上叫“XX回归”,背地里却是解决分类问题的。
其原理是将样本的特征和样本发生的概率联系起来,即,预测的是样本发生的概率是多少。由于概率是一个数,因此被叫做“逻辑回归”。
在线性回归算法的例子中,我们进行房价预测得到的结果值 y ^ = f ( x ) \hat y=f(x) y^=f(x),就是我们预测的房价,是一个数值。
但是我们在逻辑回归算法中,得到的预测值是一个概率,然后在概率的基础上多做一步操作,得到分类的结果。比如某银行使用逻辑回归做风控模型,先设置一个阈值0.5,如果得到它逾期的概率大于0.5,就不放款;否则就放款。对于“放款” or “不放款”来说,实际上是一个标准的分类问题。
p ^ = f ( x ) \hat p=f(x) p^=f(x)
y ^ = { 0 , p ^ ⩽ 0.5 1 , p ^ > 0.5 \hat y=\begin{cases} 0,& \hat p\leqslant 0.5\\ 1,& \hat p>0.5 \end{cases} y^={0,1,p^⩽0.5p^>0.5
通过这个小例子我们可以看到,在回归问题上再多做一步,就可以作为分类算法来使用了。逻辑回归只能解决二分类问题,如果是多分类问题,LR本身是不支持的。
对于线性回归来说,通过传递的自变量x来计算预测值: y ^ = f ( x ) \hat y=f(x) y^=f(x)。其中f(x)实际上就是参数与样本的矩阵相乘, y ^ = θ T ⋅ x b \hat y =\theta^T\cdot x_b y^=θT⋅xb。那我们可不可以找到一组参数,与特征矩阵相乘,直接得到表示概率的结果呢?
单单从应用的角度来说,是可以的,但是并不好。这是因为线性回归得到值是没有限制的,值域从负无穷到正无穷的值。而对于概率来说,其值域为[0,1],是有限制的。如果直接使用线性回归得到的结果,使得最终拟合的结果可信程度较差。
那么下面我们就看一看,逻辑回归背后的数学原理。
(二)LR算法数学推导
1.决策背后的博弈
逻辑回归使用什么样的方式来得到一个事件发生的概率值的呢?分类的背后又是什么呢?
以银行理财产品营销场景为例,对于银行来说,客户只有“买”和“不买”两种行为,但是这个行为实际上是客户在接到营销行为,如电话营销、短信营销之后,经过内心博弈产生的最终结果。
客户为什么会做出“买”或“不买”这样的被分类的行为?如果客户手里有一笔暂时不会动用的闲钱,且他希望能够通过投资行为获利,并且对盈利效果表示认可,则客户会考虑购买理财产品。但是反过来,如果客户没有钱,或者他有其他更好的投资渠道,或者厌恶投资风险,那么客户就不会购买。从经济学的角度来说,购买理财产品这一行为,既能给客户带来正效用,也能给客户带来负效用。当客户主观认为正效用大于负效用时,可就是购买行为带来的整体效用大于0时,客户就会购买,反之则不然。
2.博弈中的隐含变量
那么我们从数学角度出发,分析上述场景:假设有自变量集合X=(x1,x2,…xk,1),这些参数表示这种特征,决定购买行为对客户的效用,包括 正 效 用 y ∗ 和 负 效 用 y ~ 正效用y^*和负效用 y^~ 正效用y∗和负效用y~
。我们将客户的购买行为记为y,其中y=1表示客户购买理财产品;y=0表示客户没有购买。于是可以得到下面的公式:
y ∗ = f ( X ) , y ~ = g ( X ) , y = { 1 y ∗ > y ~ 0 y ∗ ⩽ y ~ y^*=f(X),y^~=g(X),y=\begin{cases} 1& y^*>y^~\\ 0& y^*\leqslant y^~ \end{cases} y∗=f(X),y~=g(X),y={10y∗>y~y∗⩽y~
如果,我们假设正负效用函数与自变量特征参数成线性相关,则根据y=ax+b可以得出:
y ∗ = X i φ + θ i , y ~ = X i ω + τ i 。 y^*=X_iφ+θ_i,y^~=X_iω+τ_i。 y∗=Xiφ+θi,y~=Xiω+τi。其中
θ i , τ i θ_i,τ_i θi,τi是相互独立的随机变量,且都服从正态分布。
在得到正负效用线性函数之后,就可以用正效用减去负效用的解是否大于0作为分类依据。令 z i = y ∗ − y ~ , γ = φ − ω , ε = θ − τ z_i=y^*-y^~,γ=φ-ω,ε=θ-τ zi=y∗−y~,γ=φ−ω,ε=θ−τ,则可以得到:
z = X γ + ε z=X_γ+ε z=Xγ+ε。如果我们将其转换为分类问题,则可以得到阶梯函数如下:
y = { 1 X γ + ε > 0 0 X γ + ε ⩽ 0 y=\begin{cases} 1& X_γ+ε>0\\ 0& X_γ+ε\leqslant 0 \end{cases} y={10Xγ+ε>0Xγ+ε⩽0
更进一步,我们将上面的函数转变为求概率,即客户购买理财产品的概率如下:
P ( y = 1 ) = P ( X γ + ε > 0 ) = P ( ε > − X γ ) = 1 − P ( ε ⩽ − X γ ) = 1 − F ε ( − X γ ) P(y=1)=P(X_γ+ε>0)=P(ε>-X_γ)=1-P(ε\leqslant-X_γ)=1-F_ε(-X_γ) P(y=1)=P(Xγ+ε>0)=P(ε>−Xγ)=1−P(ε⩽−Xγ)=1−Fε(−Xγ)
其中,Fε是随机变量ε的累积分布函数,P(y=1)表示客户购买的比例。
这个模型在学术上被称作是probit回归(虽然是名字中有“回归”两个字,但是实际上解决的还是分类问题)。
在模型搭建的过程中,我们假设了客户内心博弈的正负效用变量: y ∗ , y ~ y^*, y^~ y∗,y~,因此这类隐藏变量模型(latent variable model);而正负效用变量: y ∗ , y ~ y^*, y^~ y∗,y~被称为隐藏变量(latent variable)。
由此可见,对于一个分类问题,由于“窗口效用”,我们只能看见客户的购买行为,但是在分类的背后,是隐藏变量之间的博弈,我们通过搭建隐藏变量的模型,来求出客户购买的概率。
3.sigmoid函数与逻辑回归
我们得到了probit回归在数学上是比较完美的,但是正态分布的累积分布函数Fε,其表达形式很复杂(复杂到懒得把公式写出来),且没有解析表达式。因此直接在probit回归上做参数估计是比较困难的。但是好在我们可以对其做近似,让其在数学上更加简洁。
此时,神奇的数学家们发现:正态分布在线性变换下保持稳定,而逻辑分布可以很好地近似正态分布。因此可以使用标准逻辑分布的累积分布函数σ(t)来替换正态分布的累积分布函数Fε(t)。
标准逻辑分布的概率密度函数为
f ( x ) = e − x ( 1 + e − x ) 2 f(x)=\frac{e^{-x}}{(1+e^{-x})^2} f(x)=(1+e−x)2e−x,对应的积累分布函数为:
σ ( t ) = 1 1 + e − t σ(t)=\frac{1}{1+e^{-t}} σ(t)=1+e−t1
在学术界被称为sigmoid函数,是在数据科学领域,特别是神经网络和深度学习领域中非常重要的函数!。其图像如下图所示,呈S状,因此也被称为“S函数”。当t趋近于正无穷时,e^-t趋近于0,则σ(t)趋近于1;当t趋近于负无穷时,趋近于正无穷,则σ(t)趋近于0。因此该函数的值域为(0,1)。
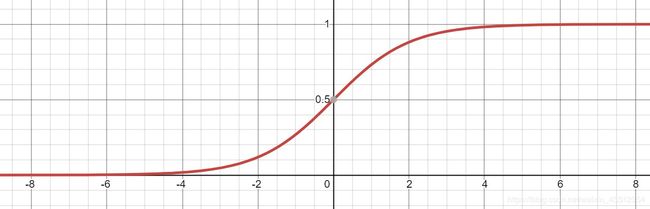
两种不同的效用函数(假定他们都满足线性回归模型的假设)相互竞争时,其中某一方最终胜出的概率分布在数学上可近似为sigmoid函数。通俗讲:sigmoid函数表述了某一方竞争胜出的概率。
将效用函数之差(同样是线性回归模型)带入sigmoid函数中,当t>0时,得到的结果是概率值p>0.5;当t<0时,得到的结果是p<0.5。因此,实际上我们得到是这样的公式:
p ^ = σ ( θ T ⋅ X b ) = 1 1 + e − θ T ⋅ X b \hat p=σ(θ^T\cdot X_b)=\frac{1}{1+e^{-θ^T\cdot X_b}} p^=σ(θT⋅Xb)=1+e−θT⋅Xb1 y ^ = { 1 p ^ > 0.5 0 p ^ ⩽ 0.5 \hat y=\begin{cases} 1& \hat p>0.5\\ 0& \hat p\leqslant 0.5 \end{cases} y^={10p^>0.5p^⩽0.5
至此,大名鼎鼎的逻辑回归模型(logit regression)如下,其中X表示客户特征,θ表示模型参数:
P ( Y = 1 ) = 1 1 + e − θ T ⋅ X b P(Y=1)=\frac{1}{1+e^{-θ^T\cdot X_b}} P(Y=1)=1+e−θT⋅Xb1
二、逻辑回归损失函数的推导、求解
(一)从对数几率看逻辑回归
1.推导过程
一句话总结逻辑回归:
逻辑回归假设数据服从伯努利分布,通过极大似然函数的方法,运用梯度下降来求解参数,来达到将数据二分类的目的。
逻辑回归是一个非线性模型,但是是其背后是以线性回归为理论支撑的。
提出一个与线性模型 y = θ T ⋅ X b y=θ^T\cdot X_b y=θT⋅Xb长相类似但不同的新公式:假设特征X所对应的y值是在指数上变化,那么就可以将结果y值取对数,作为其线性模型逼近的目标。也就是所谓的“对数线性回归”: l n ( y ) = θ T ⋅ X b ln(y)=θ^T\cdot X_b ln(y)=θT⋅Xb
在“对数线性回归”的公式中,可以改写为 y = e θ T ⋅ X b 。 y=e^{θ^T\cdot X_b}。 y=eθT⋅Xb。实际上是在求输入空间X到输出空间y的非线性函数映射。对数函数的作用是将线性回归模型的预测值与真实标记联系起来。
因此可以得到一个一般意义上的单调可微的“联系函数”:g(a)=ln(a)。其本质就是给原来线性变换加上一个非线性变换(或者说映射),使得模拟的函数有非线性的属性,但本质上调参还是线性的,主体是内部线性的调参。
那么对于解决分类问题的逻辑回归来说,我们需要找到一个“联系函数”,将线性回归模型的预测值与真实标记联系起来。
将“概率”转换为“分类”的工具是“阶梯函数”:
p ^ = f ( x ) \hat p = f(x) p^=f(x) y ^ = { 1 p ^ > 0.5 0 p ^ ⩽ 0.5 \hat y=\begin{cases} 1& \hat p>0.5\\ 0& \hat p\leqslant 0.5 \end{cases} y^={10p^>0.5p^⩽0.5
但是这个阶梯函数不连续,不能作为“联系函数”g,因此使用对数几率函数来在一定程度上近似阶梯函数,将线性回归模型的预测值转化为分类所对应的概率。
σ ( t ) = 1 1 + e − t σ(t)=\frac{1}{1+e^{-t}} σ(t)=1+e−t1
如果另y为正例,1-y为负例,所谓的“几率”就是二者的比值y/(1-y)。几率反映了样本x为正例的相对可能性。
“对数几率”就是对几率取对数ln(y/(1-y)*),对数几率实际上就是之前提到的sigmoid函数,将线性模型转化为分类。
如果令 y = 1 1 + e − θ T ⋅ X b , 1 − y = e − θ T ⋅ X b 1 + e − θ T ⋅ X b 。 y=\frac{1}{1+e^{-θ^T\cdot X_b}},1-y=\frac{e^{-θ^T\cdot X_b}}{1+e^{-θ^T\cdot X_b}}。 y=1+e−θT⋅Xb1,1−y=1+e−θT⋅Xbe−θT⋅Xb。 带入到对数几率中 l n y 1 − y = θ T ⋅ X b 。 ln\frac{y}{1-y}={θ^T\cdot X_b}。 ln1−yy=θT⋅Xb。
可以看出,sigmoid实际上就是用线性回归模型的预测结果取逼近真实值的对数几率,因此逻辑回归也被称为“对数几率回归”。
2.面试问题
为什么要使用sigmoid函数作为假设?
现在就可以回答了:
因为线性回归模型的预测值为实数,而样本的类标记为(0,1),我们需要将分类任务的真实标记y与线性回归模型的预测值联系起来,也就是找到广义线性模型中的联系函数。
- 如果选择单位阶跃函数的话,它是不连续的不可微。
- 而如果选择sigmoid函数,它是连续的,而且能够将z转化为一个接近0或1的值。
(二)逻辑回归的损失函数
1.损失函数推导过程
已经知道逻辑回归的模型:
p ^ = σ ( θ T ⋅ X b ) = 1 1 + e − θ T ⋅ X b \hat p =σ(θ^T\cdot X_b)=\frac{1}{1+e^{-θ^T\cdot X_b}} p^=σ(θT⋅Xb)=1+e−θT⋅Xb1 y ^ = { 1 p ^ > 0.5 0 p ^ ⩽ 0.5 \hat y=\begin{cases} 1& \hat p>0.5\\ 0& \hat p\leqslant 0.5 \end{cases} y^={10p^>0.5p^⩽0.5
那么,如何求出未知参数θ呢?
首先回顾一下线性回归。在线性回归中,做法如下:
由于已知 θ T ⋅ X b θ^T\cdot X_b θT⋅Xb是估计值,于是用估计值与真值的差来度量模型的好坏。使用MSE(差值的平方和再平均)作为损失函数。然后就可以通过导数求极值的方法,找到令损失函数最小的θ了。
那么在逻辑回归中,解决思路也大致类似。
逻辑回归和线性回归最大的区别就是:逻辑回归解决的是分类问题,得到的y要么是1,要么是0。而我们估计出来的p是概率,通过概率决定估计出来的p到底是1还是0。因此,也可以将损失函数分成两类:
- 如果给定样本的真实类别y=1,则估计出来的概率p越小,损失函数越大(估计错误)
- 如果给定样本的真实类别y=0,则估计出来的概率p越大,损失函数越大(估计错误)
那么将用什么样的函数表示这两种情况呢,可以使用如下函数:
J = { − l o g ( p ^ ) i f y = 1 − l o g ( 1 − p ^ ) i f y = 0 J=\begin{cases} -log(\hat p)& if & y=1\\ -log(1-\hat p)& if & y=0 \end{cases} J={−log(p^)−log(1−p^)ifify=1y=0

分析上面的公式:
| y | 损失函数 | 特点 |
|---|---|---|
| y=1 | − l o g ( p ^ ) -log(\hat p) −log(p^) | p ^ 越 趋 于 0 , 损 失 ( l o s s ) 越 大 ; 越 趋 于 1 , 损 失 ( l o s s ) 越 小 。 \hat p越趋于0,损失(loss)越大;越趋于1,损失(loss)越小。 p^越趋于0,损失(loss)越大;越趋于1,损失(loss)越小。 |
| y=0 | − l o g ( 1 − p ^ ) -log(1-\hat p) −log(1−p^) | p ^ 越 趋 于 1 , 损 失 ( l o s s ) 越 大 ; 越 趋 于 0 , 损 失 ( l o s s ) 越 小 。 \hat p越趋于1,损失(loss)越大;越趋于0,损失(loss)越小。 p^越趋于1,损失(loss)越大;越趋于0,损失(loss)越小。 |
-
分析如下:
-
当y=1时, J = − l o g ( p ^ ) J=-log(\hat p) J=−log(p^)是一个单调递减函数,且概率p的值域只能是[0,1]之间,因此只有函数的上半部分。我们看到当概率p取0(即预估的分类结果y=0)时,loss值是趋近于正无穷的,表明我们分错了(实际分类结果是1)。
-
当y=0时, J = − l o g ( 1 − p ^ ) J=-log(1-\hat p) J=−log(1−p^)是一个单调递增函数,且概率p的值域只能是[0,1]之间,因此只有函数的上半部分。我们看到当概率p取1(即预估的分类结果y=1)时,loss值是趋近于正无穷的,表明我们分错了(实际分类结果是0)。
由于模型是个二分类问题,分类结果y非0即1,因此我们可以使用一个巧妙的方法,通过控制系数的方式,将上面的两个式子合并成一个:
J ( p ^ , y ) = − l o g ( p ^ ) y − l o g ( 1 − p ^ ) 1 − y J(\hat p,y)=-log(\hat p)^y-log(1-\hat p)^{1-y} J(p^,y)=−log(p^)y−log(1−p^)1−y
以上是对于单个样本的误差值,那么求整个集合内的损失可以取平均值:
J ( θ ) = − 1 m ∑ i = 1 m y ( i ) l o g ( p ^ ( i ) ) + ( 1 − y ( i ) ) l o g ( 1 − p ^ ( i ) ) J(θ)=-\frac{1}{m}\sum_{i=1}^my^{(i)}log(\hat p^{(i)})+(1-y^{(i)})log(1-\hat p^{(i)}) J(θ)=−m1i=1∑my(i)log(p^(i))+(1−y(i))log(1−p^(i))
然后,我们\hat p 替换成sigmoid函数,得到逻辑回归的损失函数如下:
J ( θ ) = − 1 m ∑ i = 1 m y ( i ) l o g ( σ ( θ T ⋅ X b ( i ) ) ) + ( 1 − y ( i ) ) l o g ( 1 − σ ( θ T ⋅ X b ( i ) ) ) J(θ)=-\frac{1}{m}\sum_{i=1}^my^{(i)}log(σ(θ^T\cdot X_b^{(i)}))+(1-y^{(i)})log(1-σ(θ^T\cdot X_b^{(i)})) J(θ)=−m1i=1∑my(i)log(σ(θT⋅Xb(i)))+(1−y(i))log(1−σ(θT⋅Xb(i)))
2.另一种推导方式
我们已经知道了逻辑损失函数的推导过程,但是就像在数学课上老师在黑板中写下的解题过程一样,我们费解的是“这个思路究竟是怎么来的”?
逻辑回归的损失函数当然不是凭空出现的,而是根据逻辑回归本身式子中系数的最大似然估计推导而来的。
最大似然估计就是通过已知结果去反推最大概率导致该结果的参数。极大似然估计是概率论在统计学中的应用,它提供了一种给定观察数据来评估模型参数的方法,即 “模型已定,参数未知”,通过若干次试验,观察其结果,利用实验结果得到某个参数值能够使样本出现的概率为最大,则称为极大似然估计。
逻辑回归是一种监督式学习,是有训练标签的,就是有已知结果的,从这个已知结果入手,去推导能获得最大概率的结果参数,只要我们得出了这个参数,那我们的模型就自然可以很准确的预测未知的数据了。
令逻辑回归的模型为 h 0 ( x ; θ ) h_0(x;θ) h0(x;θ),则可以将其视为类1的后验概率,所以有:
p ( y = 1 ∣ x ; θ ) = ψ ( t ) = 1 1 + e − θ T ⋅ X b p(y=1|x;θ)=ψ(t)=\frac{1}{1+e^{-θ^T\cdot X_b}} p(y=1∣x;θ)=ψ(t)=1+e−θT⋅Xb1
p ( y = 0 ∣ x ; θ ) = 1 − ψ ( t ) = e − θ T ⋅ X b 1 + e − θ T ⋅ X b p(y=0|x;θ)=1-ψ(t)=\frac{e^{-θ^T\cdot X_b}}{1+e^{-θ^T\cdot X_b}} p(y=0∣x;θ)=1−ψ(t)=1+e−θT⋅Xbe−θT⋅Xb
以上两个式子,可以改写为一般形式:
p ( y ∣ x ; θ ) = h 0 ( x ; θ ) y ( 1 − h 0 ( x ; θ ) ) ( 1 − y ) p(y|x;θ)=h_0(x;θ)^y(1-h_0(x;θ))^{(1-y)} p(y∣x;θ)=h0(x;θ)y(1−h0(x;θ))(1−y)
因此根据最大似然估计,可以得到:
J ( θ ) = ∏ i = 1 m p ( y i ∣ x i ; θ ) = ∏ i = 1 m h 0 ( x i ; θ ) y i ( 1 − h 0 ( x i ; θ ) ) ( 1 − y ) i J(θ)=\prod_{i=1}^mp(y^i|x^i;θ)=\prod_{i=1}^mh_0(x^i;θ)^{y^i}(1-h_0(x^i;θ))^{(1-y)^i} J(θ)=i=1∏mp(yi∣xi;θ)=i=1∏mh0(xi;θ)yi(1−h0(xi;θ))(1−y)i
为了简化计算,取对数将得到:
l o g ( J ( θ ) ) = ∑ i = 1 m y ( i ) l o g ( p ^ ( i ) ) + ( 1 − y ( i ) ) l o g ( 1 − p ^ ( i ) ) log(J(θ))=\sum_{i=1}^my^{(i)}log(\hat p^{(i)})+(1-y^{(i)})log(1-\hat p^{(i)}) log(J(θ))=i=1∑my(i)log(p^(i))+(1−y(i))log(1−p^(i))
我们希望极大似然越大越好,就是说,对于给定样本数量m,希望越小越好,得到逻辑回归的损失函数如下:
J ( θ ) = − 1 m ∑ i = 1 m y ( i ) l o g ( σ ( θ T ⋅ X b ( i ) ) ) + ( 1 − y ( i ) ) l o g ( 1 − σ ( θ T ⋅ X b ( i ) ) ) J(θ)=-\frac{1}{m}\sum_{i=1}^my^{(i)}log(σ(θ^T\cdot X_b^{(i)}))+(1-y^{(i)})log(1-σ(θ^T\cdot X_b^{(i)})) J(θ)=−m1i=1∑my(i)log(σ(θT⋅Xb(i)))+(1−y(i))log(1−σ(θT⋅Xb(i)))
所以说逻辑回归的损失函数不是定义出来的,而是根据最大似然估计推导出来的。
下面的目标就是:找到一组参数θ,使得损失函数J(θ)达到最小值。
这个损失函数是没有标准方程解的,因此在实际的优化中,我们往往直接使用梯度下降法来不断逼近最优解。
(三)损失函数的梯度
对于损失函数:
J ( θ ) = − 1 m ∑ i = 1 m y ( i ) l o g ( σ ( θ T ⋅ X b ( i ) ) ) + ( 1 − y ( i ) ) l o g ( 1 − σ ( θ T ⋅ X b ( i ) ) ) J(θ)=-\frac{1}{m}\sum_{i=1}^my^{(i)}log(σ(θ^T\cdot X_b^{(i)}))+(1-y^{(i)})log(1-σ(θ^T\cdot X_b^{(i)})) J(θ)=−m1i=1∑my(i)log(σ(θT⋅Xb(i)))+(1−y(i))log(1−σ(θT⋅Xb(i)))
使用梯度下降法,就要求出梯度,对每一个向量θ中每一个参数,都求出对应的导数:
ᐁ f = ( ∂ J ( θ ) ∂ θ 0 , ∂ J ( θ ) ∂ θ 1 , ∂ J ( θ ) ∂ θ 2 , … … ∂ J ( θ ) ∂ θ n , ) T ᐁf=(\frac{\partial J(θ)}{\partial θ_0},\frac{\partial J(θ)}{\partial θ_1},\frac{\partial J(θ)}{\partial θ_2},……\frac{\partial J(θ)}{\partial θ_n},)^T ᐁf=(∂θ0∂J(θ),∂θ1∂J(θ),∂θ2∂J(θ),……∂θn∂J(θ),)T
对sigmoid函数进行求导(链式求导法则):
σ ( t ) = 1 1 + e − t = ( 1 + e − t ) − 1 σ ( t ) ′ = − ( 1 + e − t ) − 2 ⋅ e − t ⋅ ( − 1 ) = ( 1 + e − t ) − 2 ⋅ e − t σ(t)=\frac{1}{1+e^{-t}}=(1+e^{-t})^{-1}σ(t)'=-(1+e^{-t})^{-2}\cdot e^{-t}\cdot (-1)=(1+e^{-t})^{-2}\cdot e^{-t} σ(t)=1+e−t1=(1+e−t)−1σ(t)′=−(1+e−t)−2⋅e−t⋅(−1)=(1+e−t)−2⋅e−t
然后对外层的log函数进行求导:
( l o g σ ( t ) ) ′ = 1 σ ( t ) ⋅ σ ( t ) ′ = 1 σ ( t ) ⋅ ( 1 + e − t ) − 2 ⋅ e − t = 1 ( 1 + e − t ) − 1 ⋅ ( 1 + e − t ) − 2 ⋅ e − t = ( 1 + e − t ) − 1 ⋅ e − t (logσ(t))'=\frac{1}{σ(t)}\cdot σ(t)'=\frac{1}{σ(t)}\cdot (1+e^{-t})^{-2}\cdot e^{-t}=\frac{1}{(1+e^{-t})^{-1}}\cdot (1+e^{-t})^{-2}\cdot e^{-t}=(1+e^{-t})^{-1}\cdot e^{-t} (logσ(t))′=σ(t)1⋅σ(t)′=σ(t)1⋅(1+e−t)−2⋅e−t=(1+e−t)−11⋅(1+e−t)−2⋅e−t=(1+e−t)−1⋅e−t
然后进行整理:
( l o g σ ( t ) ) ′ = e − t 1 + e − t = 1 − 1 1 + e − t = 1 − σ ( t ) (logσ(t))'=\frac{e^{-t}}{1+e^{-t}}=1-\frac{1}{1+e^{-t}}=1-σ(t) (logσ(t))′=1+e−te−t=1−1+e−t1=1−σ(t)
下面就可以对损失函数前半部分的表达式: y ( i ) l o g ( σ ( θ T ⋅ X b ( i ) ) ) y^{(i)}log(σ(θ^T\cdot X_b^{(i)})) y(i)log(σ(θT⋅Xb(i))) 对θ进行求导了。带入上面的结果,得到:
y ( i ) ( 1 − σ ( θ T ⋅ X b ( i ) ) ) ⋅ X j ( i ) y^{(i)}(1-σ(θ^T\cdot X_b^{(i)}))\cdot X_j^{(i)} y(i)(1−σ(θT⋅Xb(i)))⋅Xj(i)
同样地,可以对损失函数的后半部分做求导,跟上面类似。
最终求的损失函数J(θ)对θ的导数如下,即逻辑回归的损失函数经过梯度下降法对一个参数进行求导,得到结果如下:
J ( θ ) θ j = 1 m ∑ i = 1 m ( σ ( θ T ⋅ X b ( i ) ) − y ( i ) ) X j ( i ) \frac{J(θ)}{θ_j}=\frac{1}{m}\sum_{i=1}^m(σ(θ^T\cdot X_b^{(i)})-y^{(i)})X_j^{(i)} θjJ(θ)=m1i=1∑m(σ(θT⋅Xb(i))−y(i))Xj(i)
其中 σ ( θ T ⋅ X b ( i ) ) σ(θ^T\cdot X_b^{(i)}) σ(θT⋅Xb(i))就是逻辑回归模型的预测值。
在求得对一个参数的导数之后,则可以对所有特征维度上对损失函数进行求导,得到向量化后的结果如下:
ᐁ J ( θ ) = 1 m ⋅ [ ∑ i = 1 m ( y ^ ( i ) − y ( i ) ) ∑ i = 1 m ( y ^ ( i ) − y ( i ) ) ⋅ X 1 ( i ) ∑ i = 1 m ( y ^ ( i ) − y ( i ) ) ⋅ X 2 ( i ) … … ∑ i = 1 m ( y ^ ( i ) − y ( i ) ) ⋅ X n ( i ) ] = 1 m ⋅ X b T ⋅ ( σ ( X b θ ) − y ) ᐁJ(θ)=\frac{1}{m}\cdot \begin{bmatrix} \sum_{i=1}^m(\hat y^{(i)}-y^{(i)})\\ \sum_{i=1}^m(\hat y^{(i)}-y^{(i)})\cdot X_1^{(i)}\\ \sum_{i=1}^m(\hat y^{(i)}-y^{(i)})\cdot X_2^{(i)}\\……\\ \sum_{i=1}^m(\hat y^{(i)}-y^{(i)})\cdot X_n^{(i)}\end{bmatrix}=\frac{1}{m}\cdot X_b^T \cdot (σ(X_bθ)-y) ᐁJ(θ)=m1⋅⎣⎢⎢⎢⎢⎢⎡∑i=1m(y^(i)−y(i))∑i=1m(y^(i)−y(i))⋅X1(i)∑i=1m(y^(i)−y(i))⋅X2(i)……∑i=1m(y^(i)−y(i))⋅Xn(i)⎦⎥⎥⎥⎥⎥⎤=m1⋅XbT⋅(σ(Xbθ)−y)
(四)小结
逻辑回归的原理以及损失函数的推导过程都是非常重要的知识点。大家可以从不同角度去学习其中的本质。
三、逻辑回归代码实现与调用
(一)逻辑回归代码实现
我们在线性回归的基础上,修改得到逻辑回归。主要内容为:
- 定义sigmoid方法,使用sigmoid方法生成逻辑回归模型
- 定义损失函数,并使用梯度下降法得到参数
- 将参数代入到逻辑回归模型中,得到概率
- 将概率转化为分类
import numpy as np
# 因为逻辑回归是分类问题,因此需要对评价指标进行更改
from .metrics import accuracy_score
class LogisticRegression:
def __init__(self):
"""初始化Logistic Regression模型"""
self.coef_ = None
self.intercept_ = None
self._theta = None
"""
定义sigmoid方法
参数:线性模型t
输出:sigmoid表达式
"""
def _sigmoid(self, t):
return 1. / (1. + np.exp(-t))
"""
fit方法,内部使用梯度下降法训练Logistic Regression模型
参数:训练数据集X_train, y_train, 学习率, 迭代次数
输出:训练好的模型
"""
def fit(self, X_train, y_train, eta=0.01, n_iters=1e4):
assert X_train.shape[0] == y_train.shape[0], \
"the size of X_train must be equal to the size of y_train"
"""
定义逻辑回归的损失函数
参数:参数theta、构造好的矩阵X_b、标签y
输出:损失函数表达式
"""
def J(theta, X_b, y):
# 定义逻辑回归的模型:y_hat
y_hat = self._sigmoid(X_b.dot(theta))
try:
# 返回损失函数的表达式
return - np.sum(y*np.log(y_hat) + (1-y)*np.log(1-y_hat)) / len(y)
except:
return float('inf')
"""
损失函数的导数计算
参数:参数theta、构造好的矩阵X_b、标签y
输出:计算的表达式
"""
def dJ(theta, X_b, y):
return X_b.T.dot(self._sigmoid(X_b.dot(theta)) - y) / len(y)
"""
梯度下降的过程
"""
def gradient_descent(X_b, y, initial_theta, eta, n_iters=1e4, epsilon=1e-8):
theta = initial_theta
cur_iter = 0
while cur_iter < n_iters:
gradient = dJ(theta, X_b, y)
last_theta = theta
theta = theta - eta * gradient
if (abs(J(theta, X_b, y) - J(last_theta, X_b, y)) < epsilon):
break
cur_iter += 1
return theta
X_b = np.hstack([np.ones((len(X_train), 1)), X_train])
initial_theta = np.zeros(X_b.shape[1])
# 梯度下降的结果求出参数heta
self._theta = gradient_descent(X_b, y_train, initial_theta, eta, n_iters)
# 第一个参数为截距
self.intercept_ = self._theta[0]
# 其他参数为各特征的系数
self.coef_ = self._theta[1:]
return self
"""
逻辑回归是根据概率进行分类的,因此先预测概率
参数:输入空间X_predict
输出:结果概率向量
"""
def predict_proba(self, X_predict):
"""给定待预测数据集X_predict,返回表示X_predict的结果概率向量"""
assert self.intercept_ is not None and self.coef_ is not None, \
"must fit before predict!"
assert X_predict.shape[1] == len(self.coef_), \
"the feature number of X_predict must be equal to X_train"
X_b = np.hstack([np.ones((len(X_predict), 1)), X_predict])
# 将梯度下降得到的参数theta带入逻辑回归的表达式中
return self._sigmoid(X_b.dot(self._theta))
"""
使用X_predict的结果概率向量,将其转换为分类
参数:输入空间X_predict
输出:分类结果
"""
def predict(self, X_predict):
"""给定待预测数据集X_predict,返回表示X_predict的结果向量"""
assert self.intercept_ is not None and self.coef_ is not None, \
"must fit before predict!"
assert X_predict.shape[1] == len(self.coef_), \
"the feature number of X_predict must be equal to X_train"
# 得到概率
proba = self.predict_proba(X_predict)
# 判断概率是否大于0.5,然后将布尔表达式得到的向量,强转为int类型,即为0-1向量
return np.array(proba >= 0.5, dtype='int')
def score(self, X_test, y_test):
"""根据测试数据集 X_test 和 y_test 确定当前模型的准确度"""
y_predict = self.predict(X_test)
return accuracy_score(y_test, y_predict)
def __repr__(self):
return "LogisticRegression()"
(二)逻辑回归的调用
下面我们使用Iris数据集,来调用上面实现的逻辑回归。
数据展示
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
iris = datasets.load_iris()
X = iris.data
y = iris.target
X = X[y<2,:2]
y = y[y<2]
plt.scatter(X[y==0,0], X[y==0,1], color="red")
plt.scatter(X[y==1,0], X[y==1,1], color="blue")
plt.show()
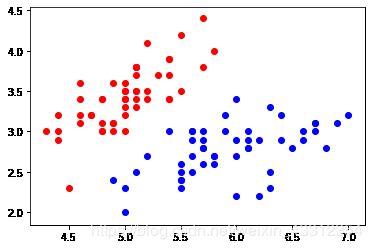
调用逻辑回归算法
from myAlgorithm.model_selection import train_test_split
from myAlgorithm.LogisticRegression import LogisticRegression
X_train, X_test, y_train, y_test = train_test_split(X, y, seed=666)
log_reg = LogisticRegression()
log_reg.fit(X_train, y_train)
# 查看训练数据集分类准确度
log_reg.score(X_test, y_test)
"""
输出:1.0
"""
# 查看逻辑回归得到的概率
log_reg.predict_proba(X_test)
"""
输出:
array([ 0.92972035, 0.98664939, 0.14852024, 0.17601199, 0.0369836 ,
0.0186637 , 0.04936918, 0.99669244, 0.97993941, 0.74524655,
0.04473194, 0.00339285, 0.26131273, 0.0369836 , 0.84192923,
0.79892262, 0.82890209, 0.32358166, 0.06535323, 0.20735334])
"""
# 得到逻辑回归分类结果
log_reg.predict(X_test)
"""
输出:
array([1, 1, 0, 0, 0, 0, 0, 1, 1, 1, 0, 0, 0, 0, 1, 1, 1, 0, 0, 0])
"""
(三)小结
我们已经实现了逻辑回归的代码,并且进行了调用。在分类中还有一个很重要的概念“决策边界”,分为线性决策边界和非线性决策边界。我们可以将逻辑回归的分类结果可视化,并且增加多项式项,让模型拟合效果更好。
四、逻辑回归的决策边界及多项式
(一)决策边界
1.什么是决策边界
回顾逻辑回归分类的原理:通过训练的方式求出一个n+1维向量θ,每当新来一个样本 x b x_b xb时,与参数 θ i θ_i θi进行点乘,结果带入sigmoid函数,得到的值为该样本发生我们定义的 y ^ \hat y y^事件发生的概率值。如果概率大于0.5,分类为1;否则分类为0。
对于公式:
p ^ = σ ( t ) = 1 1 + e ( − t ) \hat p=σ(t)=\frac{1}{1+e^{(-t)}} p^=σ(t)=1+e(−t)1
t = θ T ⋅ x b t=θ^T\cdot x_b t=θT⋅xb
- 当t>0时, 1 < 1 + e ( − t ) < 2 1<1+e^{(-t)}<2 1<1+e(−t)<2,因此 p ^ > 0.5 \hat p>0.5 p^>0.5 ;
- 当t<0时, 2 < 1 + e ( − t ) 2<1+e^{(-t)} 2<1+e(−t),因此 p ^ < 0.5 \hat p<0.5 p^<0.5
- 也就是,其中有一个边界点 θ T ⋅ x b = 0 θ^T\cdot x_b=0 θT⋅xb=0,大于这个边界点,分类为1,小于这个边界点。我们称之为决策边界(decision boundary)。
决策边界: θ T ⋅ x b = 0 θ^T\cdot x_b=0 θT⋅xb=0 同时也代表一个直线:假设X有两个特征 x 1 , x 2 x_1,x_2 x1,x2,那么有
θ T ⋅ x b = θ 0 + θ 1 x 1 + θ 2 x 2 = 0 θ^T\cdot x_b=θ_0+θ_1x_1+θ_2x_2=0 θT⋅xb=θ0+θ1x1+θ2x2=0
这是一个直线,可以将数据集分成两类。可以改写成我们熟悉的形式:
x 2 = − θ 0 − θ 1 x 1 θ 2 x_2=\frac{-θ_0-θ_1x_1}{θ_2} x2=θ2−θ0−θ1x1
2.决策边界的可视化
在鸢尾花数据集中,画出决策边界。首先可视化数据集
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
iris = datasets.load_iris()
X = iris.data
y = iris.target
X = X[y<2,:2]
y = y[y<2]
plt.scatter(X[y==0,0], X[y==0,1], color="red")
plt.scatter(X[y==1,0], X[y==1,1], color="blue")
plt.show()

然后使用逻辑回归进行训练:
from playML.model_selection import train_test_split
from playML.LogisticRegression import LogisticRegression
X_train, X_test, y_train, y_test = train_test_split(X, y, seed=666)
log_reg = LogisticRegression()
log_reg.fit(X_train, y_train)
log_reg.coef_
"""
输出:
array([ 3.01796521, -5.04447145])
"""
log_reg.intercept_
"""
输出:
-0.6937719272911228
"""
现在按照公式,创建一个函数x2,一旦传来一个x1,就根据公式得到决策边界的直线:
x 2 = − θ 0 − θ 1 x 1 θ 2 x_2=\frac{-θ_0-θ_1x_1}{θ_2} x2=θ2−θ0−θ1x1
def x2(x1):
return (-log_reg.coef_[0] * x1 - log_reg.intercept_) / log_reg.coef_[1]
# 生成一条直线,x为4~8范围内的1000点 y为x2函数的调用,
x1_plot = np.linspace(4, 8, 1000)
x2_plot = x2(x1_plot)
plt.scatter(X[y==0,0], X[y==0,1], color="red")
plt.scatter(X[y==1,0], X[y==1,1], color="blue")
plt.plot(x1_plot, x2_plot)
plt.show()
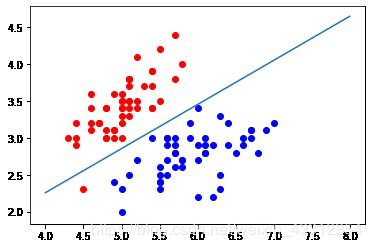
这条直线就是决策边界,新来的点在直线上方分类为0,直线下方分类为1。
但是可以看出,线性决策边界只是一根直线,很简单,因此加入多项式项,使得分类算法的决策边界不再规律。
3 线性&非线性决策边界
所谓决策边界就是能够把样本正确分类的一条边界,主要有线性决策边界(linear decision boundaries)和非线性决策边界(non-linear decision boundaries)。
注意:决策边界是假设函数的属性,由参数决定,而不是由数据集的特征决定。
下面主要举一些例子,形象化的来说明线性决策边界和非线性决策边界。先看一个线性决策边界的例子:
对于线性这条直线可以比较完美地将数据分成两类。但是直线的分类方式,太简单了。
如果遇到下图的情况,就不能用一个直线将其进行分类了,而是可以用一个圆将数据进行分类。下面来看一下非线性的决策边界的例子:

(二)逻辑回归的非线性决策边界
对于线性这条蓝色的直线可以比较完美地将数据分成两类。但是直线的分类方式,太简单了。
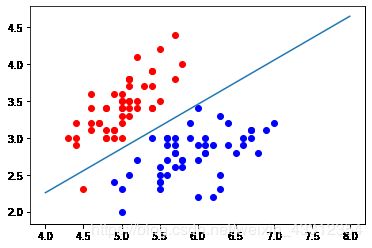
如果我们遇到下图的情况,我们就不能用一个直线将其进行分类了,而是可以用一个圆将数据进行分类。
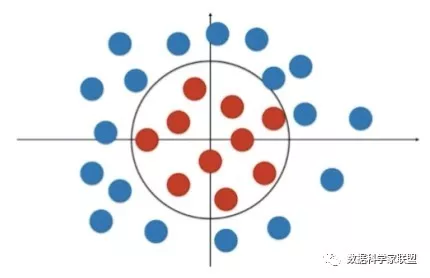
那么如何使用逻辑回归算法得到非直线的决策边界呢?
我们回忆一下中学的数据知识——圆的表达式:
x 1 2 + x 2 2 − r 2 = 0 x_1^2+x_2^2-r^2=0 x12+x22−r2=0
为了让逻辑回归学习到这样的决策边界,我们需要引入多项式项。如果将上式中的 x 1 2 x_1^2 x12整体看作第一个特征 m 1 m_1 m1,将 x 2 2 x_2^2 x22整体看作第二个特征 m 2 m_2 m2,那么则可以转换成线性回归的问题:其中 m 1 m_1 m1前的系数为1, m 2 m_2 m2前系数也为1,且 r 2 r^2 r2是系数 θ 0 \theta_0 θ0。
这样就从 m 1 , m 2 m_1,m_2 m1,m2来说还是线性边界,针对于 x 1 , x 2 x_1,x_2 x1,x2来说变成了非线性的圆形决策边界。这就从线性回归转换成多项式回归,同理为逻辑回归添加多项式项,就可以对非线性的方式进行比较好的分类,决策边界就是曲线的形状。
2.代码
使用多项式的思路,如何对非线性决策边界的数据进行很好的分类。
import numpy as np
import matplotlib.pyplot as plt
np.random.seed(666)
X = np.random.normal(0, 1, size=(200, 2))
y = np.array((X[:,0]**2+X[:,1]**2)<1.5, dtype='int')
plt.scatter(X[y==0,0], X[y==0,1])
plt.scatter(X[y==1,0], X[y==1,1])
plt.show()
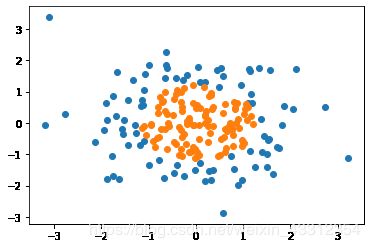
首先我们使用没添加多项式项的逻辑回归函数,对上面的样本进行划分。得到的分类结果应该是很差的。
from myAlgorithm.LogisticRegression import LogisticRegression
log_reg = LogisticRegression()
log_reg.fit(X, y)
log_reg.score(X, y)
# 绘制决策边界的方法
def plot_decision_boundary(model, axis):
x0, x1 = np.meshgrid(
np.linspace(axis[0], axis[1], int((axis[1]-axis[0])*100)).reshape(-1, 1),
np.linspace(axis[2], axis[3], int((axis[3]-axis[2])*100)).reshape(-1, 1),
)
X_new = np.c_[x0.ravel(), x1.ravel()]
y_predict = model.predict(X_new)
zz = y_predict.reshape(x0.shape)
from matplotlib.colors import ListedColormap
custom_cmap = ListedColormap(['#EF9A9A','#FFF59D','#90CAF9'])
plt.contourf(x0, x1, zz, linewidth=5, cmap=custom_cmap)
plot_decision_boundary(log_reg, axis=[-4, 4, -4, 4])
plt.scatter(X[y==0,0], X[y==0,1])
plt.scatter(X[y==1,0], X[y==1,1])
plt.show()
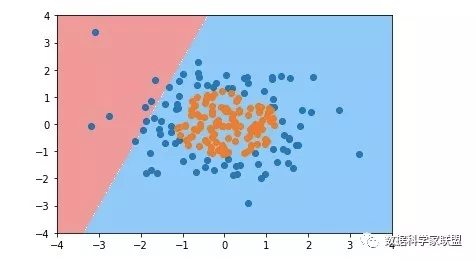
然后使用逻辑回归的方式添加多项式特征,对上面的样本进行划分:
为逻辑回归算法添加多项式项。设置pipeline。列表中每个元素是管道中的一步,每一步是一个元组,元组第一个元素是字符串表示做什么,第二个元素是类的对象。管道的第一步是添加多项式项,第二部是归一化,第三部进行逻辑回归过程,返回实例对象。关于管道的具体用法,可以看看相关的文章。
from sklearn.preprocessing import PolynomialFeatures
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
# 为逻辑回归添加多项式项的管道
def PolynomialLogisticRegression(degree):
return Pipeline([
('poly', PolynomialFeatures(degree=degree)),
('std_scaler', StandardScaler()),
('log_reg', LogisticRegression())
])
# 使用管道得到对象
poly_log_reg = PolynomialLogisticRegression(degree=2)
poly_log_reg.fit(X, y)
"""
输出:
Pipeline(steps=[('poly', PolynomialFeatures(degree=2, include_bias=True, interaction_only=False)), ('std_scaler', StandardScaler(copy=True, with_mean=True, with_std=True)), ('log_reg', LogisticRegression())])
"""
poly_log_reg.score(X, y)
"""
输出:
0.94999999999999996
"""
plot_decision_boundary(poly_log_reg, axis=[-4, 4, -4, 4])
plt.scatter(X[y==0,0], X[y==0,1])
plt.scatter(X[y==1,0], X[y==1,1])
plt.show()
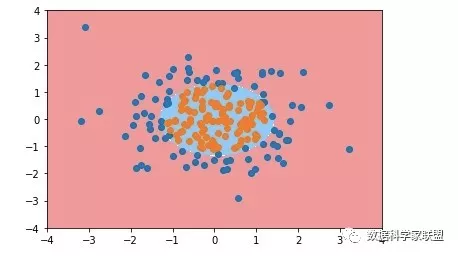
下面我们更改degree参数(多项式拓展的阶数),将其变大(那肯定会过拟合)
poly_log_reg2 = PolynomialLogisticRegression(degree=20)
poly_log_reg2.fit(X, y)
plot_decision_boundary(poly_log_reg2, axis=[-4, 4, -4, 4])
plt.scatter(X[y==0,0], X[y==0,1])
plt.scatter(X[y==1,0], X[y==1,1])
plt.show()
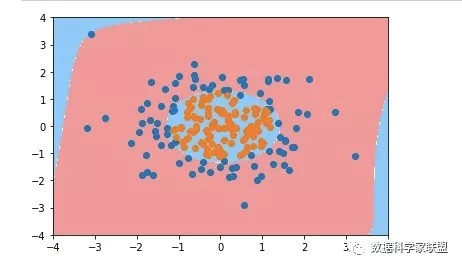
最终的结果,决策边界的外侧比较奇怪,这就是典型的过拟合。
(三)小结
决策边界是分类中非常重要的一个概念。线性决策边界就是一条直线,而在真实数据,很少是一根直线就能分类的,通常都要加上多项式项,也就是非线性的决策边界。这样才能解决更复杂的问题。
但是多项式项的阶数越大,越容易过拟合。那么就要进行模型的正则化。
五、sklearn中的逻辑回归中及正则化
(一) 逻辑回归中使用正则化
对损失函数增加L1正则或L2正则。可以引入一个新的参数α来调节损失函数和正则项的权重,如: J ( θ ) + α L 1 J(\theta)+αL_1 J(θ)+αL1。(对于L1、L2正则项的内容,不是本篇介绍的重点)
如果在损失函数前引入一个超参数C,即: C ⋅ J ( θ ) + L 1 C\cdot J(\theta)+L_1 C⋅J(θ)+L1,如果C越大,优化损失函数时越应该集中火力,将损失函数减小到最小;C非常小时,此时L1和L2的正则项就显得更加重要。其实损失函数前的参数C,作用相当于参数α前的一个倒数。在逻辑回归中,对模型正则化更喜欢使用 C ⋅ J ( θ ) + L 1 C\cdot J(\theta)+L_1 C⋅J(θ)+L1这种方式。
(二)sklearn中的逻辑回归
import numpy as np
import matplotlib.pyplot as plt
np.random.seed(666)
# 构建服从标准差为0,方差为1的分布,200个样本,有两个特征
X = np.random.normal(0, 1, size=(200, 2))
# 构建输入空间X与标签y的关系:是一个抛物线,通过布尔向量转为int类型
y = np.array((X[:,0]**2+X[:,1])<1.5, dtype='int')
# 随机在样本中挑20个点,强制分类为1(相当于噪音)
for _ in range(20):
y[np.random.randint(200)] = 1
plt.scatter(X[y==0,0], X[y==0,1])
plt.scatter(X[y==1,0], X[y==1,1])
plt.show()

使用sklearn中的逻辑回归
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=666)
log_reg = LogisticRegression()
log_reg.fit(X_train, y_train)
#######
LogisticRegression(C=1.0, class_weight=None, dual=False, fit_intercept=True,
intercept_scaling=1, l1_ratio=None, max_iter=100,
multi_class='warn', n_jobs=None, penalty='l2',
random_state=None, solver='warn', tol=0.0001, verbose=0,
warm_start=False)
注意观察,有一个参数penalty的默认参数是l2,这说明sklearn中默认是使用L2正则项的,且超参数C默认1。
log_reg.score(X_train, y_train)
----
0.7933333333333333
log_reg.score(X_test, y_test)
------
0.86
我们发现准确不高,这很正常!因为设置的就是非线性的数据,而现在用的还是没加多项式的逻辑回归。
下面可以可视化一下决策边界:
def plot_decision_boundary(model, axis):
x0, x1 = np.meshgrid(
np.linspace(axis[0], axis[1], int((axis[1]-axis[0])*100)).reshape(-1, 1),
np.linspace(axis[2], axis[3], int((axis[3]-axis[2])*100)).reshape(-1, 1),
)
X_new = np.c_[x0.ravel(), x1.ravel()]
y_predict = model.predict(X_new)
zz = y_predict.reshape(x0.shape)
from matplotlib.colors import ListedColormap
custom_cmap = ListedColormap(['#EF9A9A','#FFF59D','#90CAF9'])
plt.contourf(x0, x1, zz, linewidth=5, cmap=custom_cmap)
plot_decision_boundary(log_reg, axis=[-4, 4, -4, 4])
plt.scatter(X[y==0,0], X[y==0,1])
plt.scatter(X[y==1,0], X[y==1,1])
plt.show()
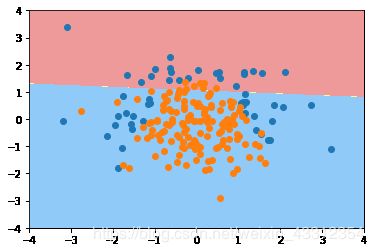
(三)多项式项逻辑回归
1. 实现多项式项逻辑回归
尝试使用多项式项进行逻辑回归。使用pipeline方式组合三个步骤,得到一个使用多项式项的逻辑回归的方法。
from sklearn.preprocessing import PolynomialFeatures
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
def PolynomialLogisticRegression(degree):
return Pipeline([
('poly', PolynomialFeatures(degree=degree)),
('std_scaler', StandardScaler()),
('log_reg', LogisticRegression())
])
poly_log_reg = PolynomialLogisticRegression(degree=2)
poly_log_reg.fit(X_train, y_train)
----------
Pipeline(memory=None, steps=[('poly',PolynomialFeatures(degree=2, include_bias=True,interaction_only=False, order='C')), ('std_scaler', StandardScaler(copy=True, with_mean=True, with_std=True)),('log_reg', LogisticRegression(C=1.0,class_weight=None, dual=False,fit_intercept=True, intercept_scaling=1,l1_ratio=None, max_iter=100,multi_class='warn', n_jobs=None,penalty='l2', random_state=None,solver='warn', tol=0.0001, verbose=0,warm_start=False))],
verbose=False)
看一下训练得到的结果:
poly_log_reg.score(X_train, y_train)
"""
输出:0.91333333333333333
"""
poly_log_reg.score(X_test, y_test)
"""
输出:
0.94
"""
plot_decision_boundary(poly_log_reg, axis=[-4, 4, -4, 4])
plt.scatter(X[y==0,0], X[y==0,1])
plt.scatter(X[y==1,0], X[y==1,1])
plt.show()
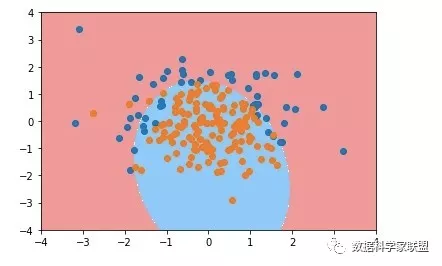
下面设置一个比较大的阶数(目的就是看看过拟合的亚子)
poly_log_reg2 = PolynomialLogisticRegression(degree=20)
poly_log_reg2.fit(X_train, y_train)
poly_log_reg2.score(X_train, y_train)
"""
输出:0.93999999999999995
"""
poly_log_reg2.score(X_test, y_test)
"""
输出:0.93999999999999995
"""
plot_decision_boundary(poly_log_reg2, axis=[-4, 4, -4, 4])
plt.scatter(X[y==0,0], X[y==0,1])
plt.scatter(X[y==1,0], X[y==1,1])
plt.show()
其实单看结果,还看不出来太多,因为我们的模型设置的很简单。但是看决策边界的话,就知道,这个奇奇怪怪的曲线,一瞅就是过拟合了。

下面就在这个过拟合的基础上,加入模型的正则化。
2.模型的正则化
(1)L2正则
使用参数C进行模型正则化,在构建管道时,用参数C去覆盖。同时在生成多项式逻辑回归实例参数时,同样设置阶数为20,然后设置一个比较小的损失函数的权重参数C=0.1,相当于让模型正则化的项起到更大的作用,让分类准确度损失函数起到小一点的作用。
def PolynomialLogisticRegression(degree, C):
return Pipeline([
('poly', PolynomialFeatures(degree=degree)),
('std_scaler', StandardScaler()),
('log_reg', LogisticRegression(C=C))
])
poly_log_reg3 = PolynomialLogisticRegression(degree=20, C=0.1)
poly_log_reg3.fit(X_train, y_train)
------
Pipeline(memory=None, steps=[('poly',PolynomialFeatures(degree=20, include_bias=True, interaction_only=False, order='C')),
('std_scaler',StandardScaler(copy=True, with_mean=True, with_std=True)),
('log_reg',LogisticRegression(C=0.1, class_weight=None, dual=False, fit_intercept=True, intercept_scaling=1, l1_ratio=None, max_iter=100,multi_class='warn', n_jobs=None, penalty='l2', random_state=None,solver='warn', tol=0.0001, verbose=0,warm_start=False))],
verbose=False)
在训练数据集及测试数据集上的表现如下:
poly_log_reg3.score(X_train, y_train)
"""
输出:0.85333333333333339
"""
poly_log_reg3.score(X_test, y_test)
"""
输出:0.92000000000000004
"""
plot_decision_boundary(poly_log_reg3, axis=[-4, 4, -4, 4])
plt.scatter(X[y==0,0], X[y==0,1])
plt.scatter(X[y==1,0], X[y==1,1])
plt.show()
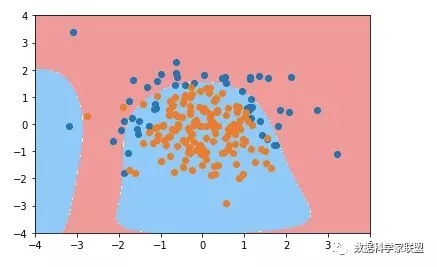
与没正则的情况下相比较,貌似是好了一点。
(2)L1正则
def PolynomialLogisticRegression(degree, C, penalty):
return Pipeline([
('poly', PolynomialFeatures(degree=degree)),
('std_scaler', StandardScaler()),
('log_reg', LogisticRegression(C=C, penalty=penalty))
])
poly_log_reg4 = PolynomialLogisticRegression(degree=20, C=0.1, penalty='l1')
poly_log_reg4.fit(X_train, y_train)
poly_log_reg4.score(X_train, y_train)
"""
输出:0.8266666666666667
"""
poly_log_reg4.score(X_test, y_test)
"""
输出:0.9
"""
plot_decision_boundary(poly_log_reg4, axis=[-4, 4, -4, 4])
plt.scatter(X[y==0,0], X[y==0,1])
plt.scatter(X[y==1,0], X[y==1,1])
plt.show()

虽然分类准确率比较低,但是没有过拟合,分类决策边界非常接近原本的真实数据了。
(四)小结
这部分介绍了sklearn中如何使用逻辑回归,并对不同的正则化项得到的效果进行了展示。在实际使用中,阶数degree,参数C以及正则化项,都是超参数,使用网格搜索的方式得到最佳的组合。