阿里-应届生面试求职基础题以及答案(2)
第一篇博客https://blog.csdn.net/weixin_43410352/article/details/103315040
8.JVM GC:介绍垃圾回收机制,垃圾回收算法。
9.JAVA的反射机制
10.Java集合类有哪些,分别在哪些场景使用
11.简述一次HTTP请求的基本流程
12.什么是JDBC,为什么需要什么是JDBC?实现原理是什么?
13.Get和Post的区别
14.Cookie和Session的区别,分别用于什么场景
15.为什么需要编码?UTF-8和GBK是如何进行编码的
16.分别介绍下JDK,JRE和JVM
17.Linux下如何快速查找文件
1.运行时内存区
要想了解GC垃圾回收机制,首先要了解虚拟机中内存分布以及管理。如下图所示,运行时数据区分为方法区、堆、虚拟机栈、本地方法栈和程序计数器等。
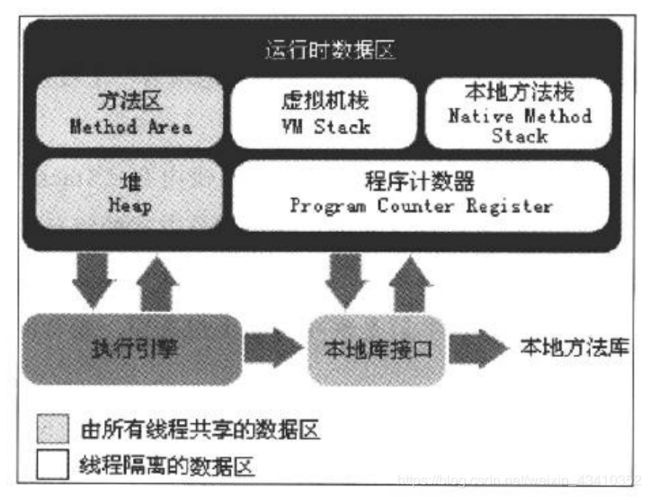
每一块区域解释如下:
方法区:是线程共享的内存区域,用来存储类加载的信息、常量、静态变量、即时编译器编译后的代码等。其中方法区中还有个经常会用到的区域叫做运行时常量池,主要用于存储一些常量,当创建一个常量时,首先会在运行时常量池查看是否有,有则直接使用,否则重新创建。
堆:堆是最大的一块内存区域,也是垃圾回收管理的主要区域,主要用于存放对象实例。
程序计时器:线程私有的,每个线程都会分配一个线程计时器,用来表示当前线程执行的字节码的行号指示器。在多线程中,一个线程执行的时候释放锁,另一个线程执行完,再回来执行前面线程的时候,就是通过程序计时器来获取继续执行的位置。
虚拟机栈:虚拟机栈主要存储基本数据类型变量和引用类型变量。其中与堆的区别就是如:Obj obj=new Object();等号左边则是在虚拟机栈上分配栈区存储引用类型变量的句柄Obj obj,等号右边则是存储对象实例,栈区的句柄是指向堆区的对象实例的,一般通过句柄访问堆区的对象实例。
本地方法栈:与虚拟机栈意义相似,区别在于虚拟机栈用于使Java方法,而本地方法栈则是针对于Native方法服务。
推荐一篇非常详细的介绍JVM GC的博客:
https://www.cnblogs.com/aspirant/p/8662690.html
反射的含义及作用
1.JAVA反射机制是在运行状态中,对于任意一个类,都能够知道这个类的所有属性和方法;
2.对于任意一个对象,都能够调用它的任意方法和属性;
3.这种动态获取信息以及动态调用对象方法的功能称为java语言的反射机制通过使用java.lang.reflect包下的API以达到各种动态需求
反射长考面试题:
Class类的含义和作用是什么:
每一个Class类的对象就代表了一种被加载进入JVM的类,它代表了该类的一种信息映射。开发者可以通过以下3种途径获取到Class对象。
1.Class c = Class.forName("");
2.Class c = obj.getClass();
3.Class c = 类名.class
如何操作类的成员变量
Field提供有关类或接口的单个静态或实例字段的信息,它通过Class类的getDeclaredField()或getDeclaredFields()方法获取到,再置于java.lang.reflect包下。Field的方法主要分为两大类,即getXXX和setXXX,她们都需要提供相应的实例对象,setXXX还需要提供需要设置的值。
如何操作类的方法(Method)
Method提供关于类或接口中的某个方法(以及如何访问该方法)的信息,包括了静态方法额成员方法(包括抽象方法在内)。它通过Class类的getMethod()或getMethods()方法获取到,该类定义在java.lang.reflect包下。Method类的最常用的方法是invoke(),正是通过它来完成方法被动态调用的目的。
如何利用反射实例化一个类
根据调用构造方法的不同,用反射机制来实例化一个类,可以有两种途径。如果使用无参数的构造方法,则直接使用Class类的newInstance()方法即可。若需要使用特定的构造方法创建对象,则需要先获取Contructor实例,再用newIntance()方法创建对象。
如何利用反射机制来访问一个类的私有成员
在使用反射机制访问私有成员的时候,他们的可访问性是为false的。需要调用setAccessible(true)方法,把原本不可访问的私有成员变为可以访问以后,才能进行成功的访问或调用。
比如:
Class class1 = Class.forName("com.lb.test.Student");
Field[] fields = class1.getDeclaredFields();
for (int i = 0; i < fields.length; i++) {
fields[i].setAccessible(true);
System.out.println(fields[i].get(student));
}
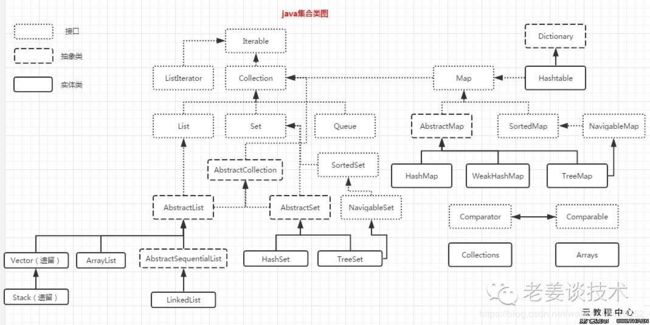
1、 Collection
包含了集的基本操作和属性的高度抽象的接口。
Collection包含了List和Set两大分支。
(1) List是一个有序的队列,实现类有4个:LinkedList, ArrayList, Vector, Stack。
(2) Set是一个不允许有重复元素的集合。实现类有3个:TreeSet、HastSet、LinkHastSet。
2、 Map
一个映射接口,即key-value键值对。
(1)AbstractMap是个抽象类,它实现了Map接口中的大部分API。实现类有6个:TreeMap、HashMap、LinkHashMap、IdentityHashMap、WeakHashMap、HashTable
(2)SortedMap 是继承于Map的接口。内容是排序的键值对,通过比较器(Comparator)
3、Iterator。
它是遍历集合的工具,即我们通常通过Iterator迭代器来遍历集合。
-
建立TCP连接
Web浏览器首先要通过网络与Web服务器建立连接,该连接是通过TCP来完成的。
TCP的三次握手
第一次:
客户端 - - > 服务器 此时服务器知道了客户端要建立连接了
第二次:
客户端 < - - 服务器 此时客户端知道服务器收到连接请求了
第三次:
客户端 - - > 服务器 此时服务器知道客户端收到了自己的回应
到这里, 就可以认为客户端与服务器已经建立了连接. -
Web浏览器向Web服务器发送请求命令
-
Web服务器应答
-
Web服务器关闭TCP连接
一般情况下,一旦 Web 服务器向浏览器发送了请求的数据,它就要关闭 TCP 连接,但是如果浏览器或者服务器在其头信息加入了这行代码:Connection:keep-alive
TCP连接在发送后将仍然保持打开状态,于是,浏览器可以继续通过相同的连接发送请求。保持连接节省了为每个请求建立新连接所需的时间,还节约了网络带宽。 -
浏览器接受到服务器响应的数据
1 什么是JDBC
JDBC(Java DataBase Connectivity)就是Java数据库连接,说白了就是用Java语言来操作数据库。原来我们操作数据库是在控制台使用SQL语句来操作数据库,JDBC是用Java语言向数据库发送SQL语句。
2 JDBC原理
早期SUN公司的天才们想编写一套可以连接天下所有数据库的API,但是当他们刚刚开始时就发现这是不可完成的任务,因为各个厂商的数据库服务器差异太大了。后来SUN开始与数据库厂商们讨论,最终得出的结论是,由SUN提供一套访问数据库的规范(就是一组接口),并提供连接数据库的协议标准,然后各个数据库厂商会遵循SUN的规范提供一套访问自己公司的数据库服务器的API出现。SUN提供的规范命名为JDBC,而各个厂商提供的,遵循了JDBC规范的,可以访问自己数据库的API被称之为驱动!
JDBC中的核心类有:DriverManager、Connection、Statement,和ResultSet!
DriverManger(驱动管理器)的作用有两个:
l 注册驱动:这可以让JDBC知道要使用的是哪个驱动;
l 获取Connection:如果可以获取到Connection,那么说明已经与数据库连接上了。
Connection对象表示连接,与数据库的通讯都是通过这个对象展开的:
l Connection最为重要的一个方法就是用来获取Statement对象;
l Statement是用来向数据库发送SQL语句的,这样数据库就会执行发送过来的SQL语句
l void executeUpdate(String sql):执行更新操作(insert、update、delete等);
l ResultSet executeQuery(String sql):执行查询操作,数据库在执行查询后会把查询结果,查询结果就是ResultSet;
ResultSet对象表示查询结果集,只有在执行查询操作后才会有结果集的产生。结果集是一个二维的表格,有行有列。操作结果集要学习移动ResultSet内部的“行光标”,以及获取当前行上的每一列上的数据:
l boolean next():使“行光标”移动到下一行,并返回移动后的行是否存在;
l XXX getXXX(int col):获取当前行指定列上的值,参数就是列数,列数从1开始,而不是0。
网上答案大都是
-
GET使用URL或Cookie传参。而POST将数据放在BODY中。
-
GET的URL会有长度上的限制,则POST的数据则可以非常大。
-
POST比GET安全,因为数据在地址栏上不可见。
4.GET的URL有长度限定
但是很不幸,这些区别全是错误的。
HTTP没有要求,如果Method是POST数据就要放在BODY中。也没有要求,如果Method是GET,数据(参数)就一定要放在URL中而不能放在BODY中。
这种说法只能是HTML标准对HTTP协议的用法的约定。怎么能当成GET和POST的区别呢?
第二个问题HTTP协议对GET和POST有没有对长度的限制呢?
HTTP协议明确地指出了,HTTP头和Body都没有长度的要求。而对于URL长度上的限制,有两方面的原因造成:
1. 浏览器。据说早期的浏览器会对URL长度做限制。据说IE对URL长度会限制在2048个字符内(流传很广,而且无数同事都表示认同)。但我自己试了一下,我构造了90K的URL通过IE9访问live.com,是正常的。网上的东西,哪怕是Wikipedia上的,也不能信。
2. 服务器。URL长了,对服务器处理也是一种负担。原本一个会话就没有多少数据,现在如果有人恶意地构造几个几M大小的URL,并不停地访问你的服务器。服务器的最大并发数显然会下降。另一种攻击方式是,把告诉服务器Content-Length是一个很大的数,然后只给服务器发一点儿数据,嘿嘿,服务器你就傻等着去吧。哪怕你有超时设置,这种故意的次次访问超时也能让服务器吃不了兜着走。有鉴于此,多数服务器出于安全啦、稳定啦方面的考虑,会给URL长度加限制。但是这个限制是针对所有HTTP请求的,与GET、POST没有关系。
安全不安全和GET、POST没有关系
有一些博客的说法是 GET 请求的请求信息是放置在 URL 的而 POST 是放置在请求数据中的所以 POST 比 GET 更安全。其实这种说法很有问题,随便抓下包 POST 中的请求报文就暴露无疑了,这又何来安全之说?
总结:对于 GET 和 POST 的区别,总结来说就是:它们的本质都是 TCP 链接,并无区别。但是由于 HTTP 的规定以及浏览器/服务器的限制,导致它们在应用过程中可能会有所不同。而上文提到那几点区别,那只不过是一种约定俗成的规矩罢了
14.
cookie和session的区别如下:
1、session保存在服务器,客户端不知道其中的信息;cookie保存在客户端,服务器能够知道其中的信息。
2、session中保存的是对象,cookie中保存的是字符串。
3、session不能区分路径,同一个用户在访问一个网站期间,所有的session在任何一个地方都可以访问到。而cookie中如果设置了路径参数,那么同一个网站中不同路径下的cookie互相是访问不到的。
4、session需要借助cookie才能正常工作。如果客户端完全禁止cookie,session将失效
编码是为了在数据传输的过程中节省数据存储空间,可以节省带宽,加快传输速度。
UTF-8:英文一个字节,中文3个字节。它可以使用1~4个字节表示一个符号
GBK:英文两个字节,中文2个字节。
注意:
UTF-8版本虽然具有良好的国际兼容性,但中文需要比GBK/BIG5版本多占用50%的数据库存储空间,因此并非推荐使用,仅供对国际兼容性有特殊要求的用户使用。
总结:
GBK就是在保存你的帖子的时候,一个汉字占用两个字节。外国人看会出现乱码,此为我中华为自己汉字编码而形成之解决方案。
UTF8就是在保存你的帖子的时候,一个汉字占用3个字节。但是外国人看的话不会乱码,此为西人为了解决多字节字符而形成之解决方案。
1.jvm,jre,jdk三者的区别
jvm:英文名称(Java Virtual Machine)它就是java的虚拟机,也是最核心的部分,所有的java程序都会首先编译成class文件,交给jvm处理,然后经过jvm解释后交给操作系统,不过jvm也不能单独处理,需要调用lib类库,而jre包含lib类库,总之jvm屏蔽了java程序与操作系统间的联系,使得Java程序只需生成在Java虚拟机上运行的目标代码(字节码)就可以实现在不同平台上的运行这也是java跨平台性的体现,只要在需要运行java应用程序的操作系统上,先安装一个Java虚拟机(JVM Java Virtual Machine)即可。
由JVM来负责Java程序在该系统中的运行。-“一次运行,到处编译”
jre:(Java Runtime Environment,Java运行环境)运行基于Java语言编写的程序所不可缺少的运行环境,jre就像咱们的pc机你编写了一个win64的程序,也需要对应的系统帮我们运行,同样,我们编写java程序也需要jre,如果你只需要运行java程序只需装jre,你装了jre也自动装了jvm jre=jvm+lib(类库)
jdk:英文名称(Java Development Kit) 包括了Java运行环境(Java Runtime Envirnment),集成了jre和一些好用的Java工具(javac/java/jdb等)和Java基础的类库(即Java API 包括rt.jar)jdk中包含jre,在jdk的安装目录下有一个名为jre的目录,里面有两个文件夹bin和lib,在这里可以认为bin里的就是jvm,lib中则是jvm工作所需要的类库,而jvm和 lib和起来就称为jre。
在使用linux时,经常需要进行文件查找。其中查找的命令主要有find和grep。两个命令是有区的。
区别:(1)find命令是根据文件的属性进行查找,如文件名,文件大小,所有者,所属组,是否为空,访问时间,修改时间等。
(2)grep是根据文件的内容进行查找,会对文件的每一行按照给定的模式(patter)进行匹配查找。
一.find命令
基本格式:find path expression
1.按照文件名查找
(1)find / -name httpd.conf #在根目录下查找文件httpd.conf,表示在整个硬盘查找
(2)find /etc -name httpd.conf #在/etc目录下文件httpd.conf
(3)find /etc -name ‘srm’ #使用通配符*(0或者任意多个)。表示在/etc目录下查找文件名中含有字符串‘srm’的文件
(4)find . -name ‘srm*’ #表示当前目录下查找文件名开头是字符串‘srm’的文件
2.按照文件特征查找
(1)find / -amin -10 # 查找在系统中最后10分钟访问的文件(access time)
(2)find / -atime -2 # 查找在系统中最后48小时访问的文件
(3)find / -empty # 查找在系统中为空的文件或者文件夹
(4)find / -group cat # 查找在系统中属于 group为cat的文件
(5)find / -mmin -5 # 查找在系统中最后5分钟里修改过的文件(modify time)
(6)find / -mtime -1 #查找在系统中最后24小时里修改过的文件
(7)find / -user fred #查找在系统中属于fred这个用户的文件
(8)find / -size +10000c #查找出大于10000000字节的文件(c:字节,w:双字,k:KB,M:MB,G:GB)
(9)find / -size -1000k #查找出小于1000KB的文件
3.使用混合查找方式查找文件
参数有: !,-and(-a),-or(-o)。
(1)find /tmp -size +10000c -and -mtime +2 #在/tmp目录下查找大于10000字节并在最后2分钟内修改的文件
(2)find / -user fred -or -user george #在/目录下查找用户是fred或者george的文件文件
(3)find /tmp ! -user panda #在/tmp目录中查找所有不属于panda用户的文件
二、grep命令
基本格式:find expression
1.主要参数
[options]主要参数:
-c:只输出匹配行的计数。
-i:不区分大小写
-h:查询多文件时不显示文件名。
-l:查询多文件时只输出包含匹配字符的文件名。
-n:显示匹配行及行号。
-s:不显示不存在或无匹配文本的错误信息。
-v:显示不包含匹配文本的所有行。
pattern正则表达式主要参数:
\: 忽略正则表达式中特殊字符的原有含义。
^:匹配正则表达式的开始行。
$: 匹配正则表达式的结束行。
<:从匹配正则表达 式的行开始。
>:到匹配正则表达式的行结束。
[ ]:单个字符,如[A]即A符合要求 。
[ - ]:范围,如[A-Z],即A、B、C一直到Z都符合要求 。
.:所有的单个字符。
* :有字符,长度可以为0。
2.实例
grep -r "字符串" 很方便
(1)grep ‘test’ d* #显示所有以d开头的文件中包含 test的行
(2)grep ‘test’ aa bb cc #显示在aa,bb,cc文件中包含test的行
(3)grep ‘[a-z]{5}’ aa #显示所有包含每行字符串至少有5个连续小写字符的字符串的行
(4)grep magic /usr/src #显示/usr/src目录下的文件(不含子目录)包含magic的行
(5)grep -r magic /usr/src #显示/usr/src目录下的文件(包含子目录)包含magic的行
(6)grep -w pattern files :只匹配整个单词,而不是字符串的一部分(如匹配’magic’,而不是’magical’),