深度置信(信念)网络DBN(Deep Belief Network)
深度置信(信念)网络DBN(Deep Belief Network)
本文对463个数据进行预测,通过遗传算法进行优化深度置信网络,并取得较高的准确率
本文优化深度置信网络主要应用到的知识有,受限玻尔兹曼机、Gibbs采样、遗传算法优化(当然可采用其他优化算法)、DBM运作机理。由于未学过tensorflow,因才在代码的编写上,采用最基础的编译方式。
1.简介
DBNs是一个概率生成模型,与传统的判别模型的神经网络相对,生成模型是建立一个观察数据和标签之间的联合分布,对 P ( O b s e r v a t i o n ∣ L a b e l ) P(Observation|Label) P(Observation∣Label)和 P ( L a b e l ∣ O b s e r v a t i o n ) P(Label|Observation) P(Label∣Observation)都做了评估,而判别模型仅仅而已评估了后者,也就是 P ( L a b e l ∣ O b s e r v a t i o n ) P(Label|Observation) P(Label∣Observation)。
DBNs由多个限制玻尔兹曼机RBM(Restricted Boltzmann Machines)层组成,一个典型的神经网络类型如图所示。这些网络被*“限制”*为一个可视层和一个隐层,层间存在连接,但层内的单元间不存在连接。隐层单元被训练去捕捉在可视层表现出来的高阶数据的相关性。
2.限制玻尔兹曼机(RBM)
2.1基本构造
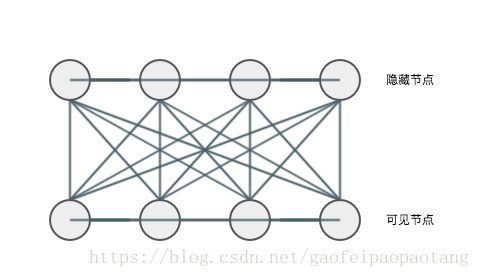
RBM是一种神经感知器,由一个显层和一个隐层构成,显层与隐层的神经元之间为双向全连接。如下图所示:
[外链图片转存失败(img-9xMm1zlO-1562146631132)(C:\Users\hp\Desktop\限制玻尔兹曼机.jpg)]
在RBM中,任意两个相连的神经元之间有一个权值 w w w表示其连接强度,每个神经元自身有一个偏置系数 b b b(对显层神经元)和 c c c(对隐层神经元)来表示其自身权重。
这样,就可以用下面函数表示一个RBM的能量:
E ( v , h ) = − Σ i = 1 N v b i v i − Σ j = 1 N h c j h j − Σ i , j = 1 N v , N W i j v i h j E(v, h)=-\Sigma_{i=1}^{N_{v}} b_{i} v_{i}-\Sigma_{j=1}^{N_{h}} c_{j} h_{j}-\Sigma_{i, j=1}^{N_{v, N}} W_{i j} v_{i} h_{j} E(v,h)=−Σi=1Nvbivi−Σj=1Nhcjhj−Σi,j=1Nv,NWijvihj
在RBM中 h j h_{j} hj有两种状态0或者1,隐藏层被激活的概率为:
P ( h j ∣ v ) = σ ( b j + Σ i W i , j v i ) P\left(h_{j} | v\right)=\sigma\left(b_{j}+\Sigma_{i} W_{i, j} v_{i}\right) P(hj∣v)=σ(bj+ΣiWi,jvi)
由于显层与隐层相连接,显层神经元同样能被隐层神经元激活:
P ( v i ∣ h ) = σ ( c i + Σ j W i , j h j ) P\left(v_{i} | h\right)=\sigma\left(c_{i}+\Sigma_{j} W_{i, j} h_{j}\right) P(vi∣h)=σ(ci+ΣjWi,jhj)
其中 σ \sigma σ为sigmoid函数,也可以是其他的函数
限制玻尔兹曼机的同一层神经元之间是独立的,所以概率密度满足独立性,故得下式:
P ( h ∣ v ) = Π j − 1 N h P ( h j ∣ v ) P ( v ∣ h ) = Π i − 1 N v P ( v i ∣ h ) \begin{array}{l}{P(h | v)=\Pi_{j-1}^{N_{h}} P\left(h_{j} | v\right)} \\ {P(v | h)=\Pi_{i-1}^{N_{v}} P\left(v_{i} | h\right)}\end{array} P(h∣v)=Πj−1NhP(hj∣v)P(v∣h)=Πi−1NvP(vi∣h)
2.2 工作原理
当我们输入到模型中样本时,数据首先被赋给显层,模型经过计算显层神经元被激活的概率,同样可以计算出隐层神经元被开启的概率 P ( h j ∣ x ) , j = 1 , 2 , … , N h P\left(h_{j} | x\right), j=1,2, \dots, N_{h} P(hj∣x),j=1,2,…,Nh,取一个数值 μ \mu μ作为阈值,大于该阈值的神经元则被激活,否则不被激活,即:大于该阈值的神经元则被激活,否则不被激活,即:
KaTeX parse error: No such environment: equation at position 8: \begin{̲e̲q̲u̲a̲t̲i̲o̲n̲}̲ h_{j}=\left\{ …
由此得到隐层的每个神经元是否被激活。
给定隐层时,显层的计算方法是一样的。
2.3 训练过程
伪代码
step1 将全部 X X X赋给显层 v 1 v_{1} v1,利用(2)计算出隐层神经元被激活的概率 P ( h 1 ∣ v 1 ) P\left(h_{1} | v_{1}\right) P(h1∣v1)
step2从计算的概率分布中抽取(采用Gibbs抽样方法)一个样本: h 1 ∼ P ( h 1 ∣ v 1 ) h_{1} \sim P\left(h_{1} | v_{1}\right) h1∼P(h1∣v1)
step3用 h 1 h_{1} h1重构显层,即通过隐层反推显层,利用(3)式计算显层中每个神经元被激活的概率 P ( v 2 ∣ h 1 ) P(v_{2}|h_{1}) P(v2∣h1);
step4同样地,从计算得到的概率分布中采取Gibbs抽样抽取一个样本: v 2 ∼ P ( v 2 ∣ h 1 ) v_{2} \sim P\left(v_{2} | h_{1}\right) v2∼P(v2∣h1)
step3通过 v 2 v_{2} v2再次计算隐层中每个神经元被激活的概率,得到概率分布 P ( h 2 ∣ v 2 ) P(h_{2}|v_{2}) P(h2∣v2)
step4更新权重:
W ← W + λ ( P ( h 1 ∣ v 1 ) v 1 − P ( h 2 ∣ v 2 ) v 2 ) b ← b + λ ( v 1 − v 2 ) c ← c + λ ( h 1 − h 2 ) \begin{array}{c}{W \leftarrow W+\lambda\left(P\left(h_{1} | v_{1}\right) v_{1}-P\left(h_{2} | v_{2}\right) v_{2}\right)} \\ {b \leftarrow b+\lambda\left(v_{1}-v_{2}\right)} \\ {c \leftarrow c+\lambda\left(h_{1}-h_{2}\right)}\end{array} W←W+λ(P(h1∣v1)v1−P(h2∣v2)v2)b←b+λ(v1−v2)c←c+λ(h1−h2)
***采用多次循环可充分训练每一个RBM,多训练几次隐层即可精准的显示显层的特征且能够还原显层。在某些论文的验证中,循环一次即可确保结果的有效性。在充分训练一层的RBM后,将最终隐层的结果(如第一个隐层的结果 v 1 ( 1 ) . ∗ W ( 1 ) v1(1).*W(1) v1(1).∗W(1),以次类推)输入到第二层的RBMz中,直到DBN结束 ***
在前期网络的构建时,一共有几层RBM,且每一层的RBM的隐层跟显层的节点数也是固定住的。
3.DBN与RBM关系
在DBN中,相邻两层即为一个RBM,每个RBM层以上一RBM层的输出(h)为输入(v),并向下一层RBM提供输入(v)。像堆积木一样一层层垒上去,就成了“深”度学习模型DBNs。如下图为一个RBM层的结构:
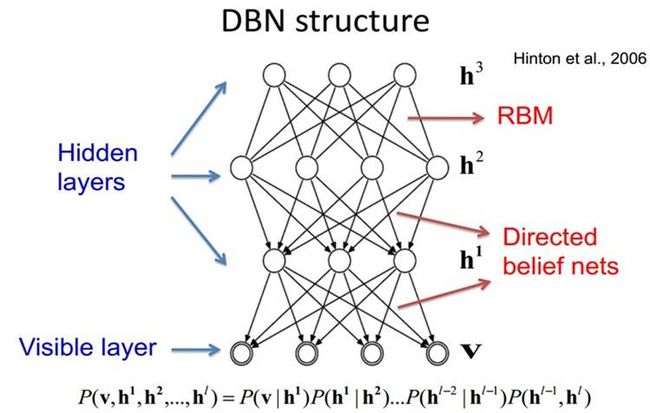
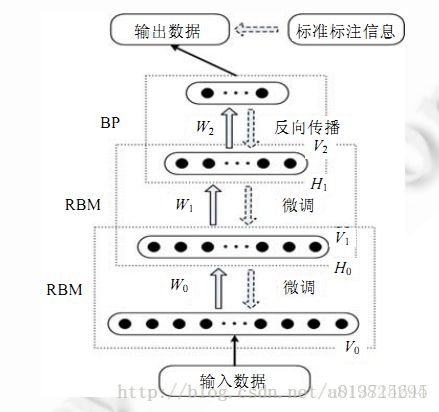
其中深度置信网络与限制玻尔兹曼机之间的关系
- DBN=RBMs=Hs+V
- RBM=H+V
训练过程中,需要充分训练上一层的RBM后才能训练当前层的RBM,直至最后一层。
4.算法实现
4.1 借助封装库
接用keras封装库。
无法优化参数
4.2用遗传算法优化DBN
import numpy as np
import numpy as np
import random
import csv
from sklearn.preprocessing import MinMaxScaler
#=================================第一部分——遗传算法=======================
# -----------------编码函数------------------------------
def ga_encoding(pop_size, chrom, num):
"""
遗传编码函数
:param pop_size:种群数量
:param chrom:染色体二进制位数
:param num:待优化权值与偏重数量
:return:编码会形成pop_size个个体,每个个体chrom*num个数量
"""
pop = [[]]
for i in range(pop_size):
temp = []
for j in range(chrom * num):
temp.append(random.randint(0, 1))
pop.append(temp)
return pop[1:]
# ----------------------------解码函数----------------------------------------------
import math
def reduce(pop):
population = [[]]
for po in pop:
temp = []
for p in po:
p = -0.5 + p * (1 / 255) # 归一化处理,生成[-1,1]区间的值
temp.append(round(p, 8)) # round(p,8)取小数点后八位
population.append(temp)
return population[1:]
def ga_decoding(pop, chrom, num):
"""
种群解码函数
:param pop: 生成的初始种群
:param chrom: 染色体二进制位数
:param num: 待优化权值与偏重数量
:return:解码返回pop_size个个体,每个个体num个,将二进制转化为十进制
"""
population = [[]]
for p in pop:
temp = []
for i in range(num):
t = 0
for j in range(chrom):
t += p[j + chrom * i] * (math.pow(2, j)) # Math.pow(底数,几次方)
temp.append(t)
population.append(temp)
return reduce(population[1:])
def ga_decoding_individual(individual, chrom, num): # 个体解码函数
temp = []
for i in range(num):
t = 0
for j in range(chrom):
t += individual[j + chrom * i] * (math.pow(2, j))
temp.append(t)
result = []
for t in temp:
t = -0.5 + t * (1 / 255)
result.append(round(t, 8))
return result
# -----------------------适值计算-------------------------------
def ga_calObject(x,lamda,m,n):
obj = []
#x是整个种群,xi是每个个体
for w in x:
# print("w",len(w),w)
error = dbn(w,lamda,m,n)
obj.append(error)
return obj
def ga_calFitness(pop,x):
best_pop = pop[0]
best_fit = x[0]
for i in range(1,len(pop)):
if(x[i]>best_fit):
best_fit = x[i]
best_pop = pop[i]
#best_pop最优个体[1,0,0,1,0...],best_fit最优适应度,
return [best_pop,best_fit]
def ga_replace(result, pop, x):
i = x.index(min(x))
x[i] = result[0]
pop[i] = result[2]
# -----------------------------选择--------------------------
def sum(fit_value):
total = 0
for i in range(len(fit_value)):
total += fit_value[i]
return total
def cumsum(fit_value):
t = 0
for i in range(len(fit_value)):
t = t + fit_value[i]
fit_value[i] = t
return fit_value
def ga_selection(pop, fit_value):
newfit_value = []
# 适应度总和
total_fit = sum(fit_value)
for i in range(len(fit_value)):
#计算每个适应度占适应度总和的比例
newfit_value.append(fit_value[i] / total_fit)
# 计算累计概率
cumsum(newfit_value)
ms = []
pop_len = len(pop)
for i in range(pop_len):
ms.append(random.random())
ms.sort()
fitin = 0
newin = 0
newpop = pop
# 转轮盘选择法
while newin < pop_len:
if(ms[newin] < newfit_value[fitin]):
newpop[newin] = pop[fitin]
newin = newin + 1
else:
fitin = fitin + 1
pop = newpop
#-------------------------------交叉----------------------------------
def ga_crossover(pop,pc):
pop_len = len(pop)
for i in range(pop_len - 1):
if(random.random() < pc):
cpoint = random.randint(0,len(pop[0]))
temp1 = []
temp2 = []
temp1.extend(pop[i][0:cpoint])
temp1.extend(pop[i+1][cpoint:len(pop[i])])
temp2.extend(pop[i+1][0:cpoint])
temp2.extend(pop[i][cpoint:len(pop[i])])
pop[i] = temp1
pop[i+1] = temp2
#------------------------------变异------------------------------------
def ga_mutation(pop, pm):
px = len(pop)
py = len(pop[0])
for i in range(px):
if (random.random() < pm):
mpoint = random.randint(0, py - 1)
if (pop[i][mpoint] == 1):
pop[i][mpoint] = 0
else:
pop[i][mpoint] = 1
#-------------------------获得最好种群---------------------------
def ga_getBest(result):
value = []
for r in result[1:]:
value.append(r[0])
i = value.index(max(value))
# print("什么",result[i + 1][0])
return result[i + 1][1]
#======================================================第二部分——深度之心网络==================================
#训练单个受限玻尔兹曼机
#因为需要调用多次,且每一层的神经元个数不同,因此先传入显层的神经元个数m,与隐层的神经元个数n
# step1:初始化变量
#1.w为隐层与显层的权重,a为显层的自身权重,b为隐层的自身权重
#数据集划分为训练与测试
def generate_data(dataset, testnum, n_features):
# print("dataset shape",dataset[:,390:],dataset.shape)
dataset_len = dataset.shape[1]
testnum = int(testnum)
x_train = np.zeros([dataset_len - 2 * testnum - n_features + 2, n_features])
x_test = np.zeros([testnum,n_features])
# print("x_test的shape",x_test.shape)
for i in range(dataset_len - n_features - 2 * testnum + 2):
x_train[i, :] = dataset[0, i:i + n_features]
# print("preprocessing_x_train",x_train,x_train.shape)
for i in range(testnum):
x_test[i, :] = dataset[0,(i + dataset_len - 2*testnum - n_features+1):(i + dataset_len - 2*testnum+1)]
# print("preprocessing_x_test",x_test,x_test.shape)
#y_train = dataset[0,n_features:dataset_len - testnum - n_features]
y_train = dataset[0, n_features + testnum - 2:dataset_len - testnum]
# print("y_train",y_train,len(y_train))
y_test = dataset[0, dataset_len - testnum:dataset_len]
# print("y_test",y_test)
return x_train,x_test,y_train,y_test
#sigmoid函数
def sigmoid(x):
sig_result=1/(1+np.exp(-x))
return sig_result
# 做gibbs抽样
def gibbs(m,ph):
h_set=np.zeros(m)
h=1000
for j in range(m):
random1=random.random()
# print("ph[j]",ph[j])
if ph[j] > random1:
h=1
h_set[j]=h
else:
h=0
h_set[j]=h
return h_set
def rbm(w,a,b,x_train,lamda):
# print("输入的显层的x",len(x_train),x_train)
error=0.0
m=a.shape[1]
n=b.shape[1]
w=np.mat(w).reshape(m,n)
# print("w",w.reshape(m,n).shape)
error = 0.0
k=5
h_x_train = np.zeros((len(x_train),n))
zeta_w = np.zeros((len(x_train),m*n))
zeta_a = np.zeros((len(x_train),m))
zeta_b = np.zeros((len(x_train),n))
for l in range(0,k):
w1 = np.zeros((1, m * n))
a1 = np.zeros((1, m))
b1 = np.zeros((1, n))
h = np.zeros((len(x_train),n))
# print("循环%d次"%l)
q=0
for v in x_train:
# print("第%d条数据"%q)
Ph1 = np.zeros((1,n))
Ph2 = np.zeros((1,n))
Pv = np.zeros((1,m))
#通过显层计算隐层被激活的概率
for i in range(0,n):
# print("======i=========",i)
all_sum=0.0
for j in range(0,m):
sum1=w[j,i]*v[j]
all_sum = all_sum + sum1
Ph1[0,i]=sigmoid(all_sum+b[0,i])
# print("Ph1的值",len(Ph1),type(Ph1),Ph1.shape,Ph1)
#gibbs抽样
h_jihuo1=gibbs(n,Ph1[0])
#通过隐层反推显层
for j in range(0,m):
all_sum1=0.0
for i in range(0,n):
sum2=w[j,i]*h_jihuo1[i]
all_sum1 += sum2
Pv[0,j]=sigmoid(all_sum1+a[0,j])
# print("Pv",len(Pv),Pv.shape,type(Pv),Pv,Pv[0])
v_jihuo=gibbs(m,Pv[0])
#通过计算得到的显层再次计算隐层
for i in range(0,n):
all_sum2 = 0.0
for j in range(0, m):
sum3 = w[j, i] * v_jihuo[j]
all_sum2 = all_sum2 + sum3
Ph2[0, i] = sigmoid(all_sum2 + b[0, i])
# print("Ph2",len(Ph2),Ph2.shape,type(Ph2),Ph2)
h_jihuo2=gibbs(n,Ph2[0])
all_sum = 0.0
zeta_w[q]=(np.dot(np.mat(v).T,np.mat(Ph1))-np.dot(np.mat(v_jihuo).T,np.mat(Ph2))).reshape(1,m*n)
zeta_a[q]=(np.mat(v) - np.mat(v_jihuo))
zeta_b[q]= (np.mat(h_jihuo1)-np.mat(h_jihuo2))
q += 1
for q in range(0,len(x_train)):
w1 += zeta_w[q]
a1 += zeta_a[q]
b1 += zeta_b[q]
# print("w1",w1.shape,len(w1),(lamda*(1/len(x_train))*w1).reshape(m,n))
# w1 = w1.reshape(m,n)
# print("w",w)
w = w + (lamda*(1/len(x_train))*w1).reshape(m,n)
a = a + lamda*(1/len(x_train))*a1
b = b + lamda*(1/len(x_train))*b1
z=0
Ph3 = np.zeros((1,n))
for v in x_train:
for i in range(0, n):
all_sum3 = 0.0
# print("w",w[:,i],len(w[:,i]))
# print("v",v)
for j in range(0, m):
# print("w",w[j,i])
# print("v",v[j])
sum4 = w[j, i] * v[j]
all_sum3 = all_sum3 + sum4
# print("all_sum3",all_sum3)
Ph3[0][i] = all_sum3 + b[0, i]
# print("Ph3",Ph3)
h[z] = Ph3[0]
z += 1
# print("h",h.shape,len(h),h)
w = w.reshape(1, m * n)
return h,w
# 实现以下函数并输出MSE
def calculateMSE(X, Y):
in_bracket = []
for i in range(len(X)):
num = Y[i] - X[i]
num = pow(num, 2)
in_bracket.append(num)
all_sum = sum(in_bracket)
MSE = all_sum / len(X)
return MSE
def dbn(w):
lamda = 0.005 # 学习速率
testnum = 43 # 测试集数目
featurenum = 5 # input_length of the network
m = [5, 20, 10] # 显层神经元个数
n = [20, 10, 1] # 隐曾神经元个数
total_w = 0 #这一块是为了计算条w的长度
for i in range(0,len(m)):
total_w += m[i]*n[i]
birth_data = []
with open('data.csv') as csvfile:
csv_reader = csv.reader(csvfile) # 使用csv.reader读取csvfile中的文件
for row in csv_reader: # 将csv 文件中的数据保存到birth_data中
birth_data.append(float(row[0]))
dataset = np.array(birth_data)
dataset = dataset[np.newaxis, :]
x_train, x_test, y_train, y_test = generate_data(dataset, testnum, featurenum) #这个函数在前边定义了,对data数据集进行数据分化
# print("x_train",len(x_train))
max_x_train = np.max(y_train.tolist())
min_x_train = np.min(y_train.tolist())
# # print("max,min",max_x_train,min_x_train)
min_max_scaler = MinMaxScaler() # 做标准化处理
x_train = min_max_scaler.fit_transform(x_train)
w2 = np.zeros((1,total_w))
for i in range(0,3): #设置了三层受限玻尔兹曼机
# print("first %d 层"%i)
a = np.zeros((1, m[i])) #显层偏差变量初始化
b = np.zeros((1, n[i])) #隐层偏差变量初始化
if i ==0: #w的初始化
w1= w[0:m[0]*n[0]]
else:
w1 = w[m[i-1]*n[i-1]:m[i-1]*n[i-1]+m[i]*n[i]]
x,result_w=rbm(w1,a,b,x_train,lamda) #每一个RBM
# print("result_w",len(result_w),type(result_w),result_w[0,:])
#下边是为了保存求得的w
if i ==0:
for q in range(0,m[0]*n[0]):
w2[0][q]=result_w[0,q]
if i ==1:
j = 0
for q in range(m[i-1]*n[i-1], m[i-1]*n[i-1]+m[i]*n[i]):
w2[0][q]=result_w[0, j]
j += 1
if i == 2:
j = 0
for q in range(m[0]*n[0]+m[1]*n[1], total_w):
w2[0][q] = result_w[0, j]
j += 1
#下边的x是上一个受限玻尔兹曼机返回的结果,在训练下一层时,要传进去
x_train=x
w2 = w2
#这个时候pre_y其实是概率,化成真实值
pre_y= x_train*(max_x_train-min_x_train) +min_x_train
error=calculateMSE(pre_y,y_train)
# print("均方误差",type(error),len(error),error)
return 1/error,w2
#====================主函数============================
# 导入数据集
lamda= 0.005 #学习速率
m = [5, 20, 10] #显层神经元个数
n = [20, 10, 1] #因曾神经元个数
birth_data = []
with open('data.csv') as csvfile:
csv_reader = csv.reader(csvfile) # 使用csv.reader读取csvfile中的文件
# birth_header = next(csv_reader) # 读取第一行每一列的标题
for row in csv_reader: # 将csv 文件中的数据保存到birth_data中
birth_data.append(float(row[0]))
dataset = np.array(birth_data)
dataset = dataset[np.newaxis, :]
testnum = 43 # 测试集数目
featurenum = 5 # input_length of the network
dataset_test = dataset[len(dataset) - testnum:len(dataset)]
x_train, x_test, y_train, y_test = generate_data(dataset, testnum, featurenum)
min_max_scaler = MinMaxScaler() # 做标准化处理
x_train = min_max_scaler.fit_transform(x_train)
x_test = min_max_scaler.transform(x_test)
POP_SIZE = 20#种群个体数量
GEN = 20#遗传迭代代数
CHROM = 8#染色体二进制位数
NUM = 310 #11*10+10+10*1+1待优化权值与偏重数量
PC = 0.7#交叉概率
PM = 0.05#变异概率
result = [[]]#存储最优解及其对应权值偏重
pop =ga_encoding(POP_SIZE,CHROM,NUM) # 编码会形成pop_size个个体,每个个体chrom*num
for i in range(GEN): # 迭代次数
x =ga_decoding(pop, CHROM, NUM) # 解码返回pop_size个个体,每个个体num个,将二进制转化为十进制
obj = ga_calObject(x,lamda,m,n)
best_pop, best_fit = ga_calFitness(pop, obj)
# 如果这一代最优值高于上一代,就用上一代最优值代替这一代最差的
if len(result) != 1 and best_fit > result[-1][0]:
ga_replace(result[-1], pop, obj)
result.append([best_fit, ga_decoding_individual(best_pop, CHROM, NUM), best_pop])
# python中list,dict是可变对象,参数传递相当于引用传递,所以会改变变量本身,string,tuple,number是不可变对象
ga_selection(pop, obj)
ga_crossover(pop, PC)
ga_mutation(pop, PM)
# v_1=rbm(w,a,b,x_train[0],y_train[0],lamda)
# energy=dbn(x_train,y_train)
此部分代码由于个人需要,未经完全展示
需补充def rbm(w,a,b,x_train,lamda):
def dbn(w,lamda,m,n):
两部分
5.知识点介绍
5.1 Boltzmann分布
5.1.1.玻尔兹曼机
1定义.
玻尔兹曼机是一个对称连接的神经网络。它用于决定系统的状态是开(1)还是关(0)。玻尔兹曼机可以看成一个通过无向有权边全连接的网络。
这个网络的能量函数定义为
E = − ( ∑ i < j w i j s i s j + ∑ i θ i s i ) E=-\left(\sum_{i
- w i j w_{i j} wij是连接节点和j的权重。
- s i \boldsymbol{s}_{i} si是节点的状态,且 s i ∈ { 0 , 1 } s_{i} \in\{0,1\} si∈{0,1}。
- θ i \theta_{i} θi是节点的在全局能量函数中的偏倚。也就是说一 θ i \theta_{i} θi是节点的激活阈值。
单个节点的能量定义为单个节点的能量定义为:
E i = θ i + ∑ j w i j s j E_{i}=\theta_{i}+\sum_{j} w_{i j} s_{j} Ei=θi+j∑wijsj
2.节点状态概率
节点只有两个选择0跟1,每一次变化都会对整个网络产生影响。单个节点 i i i的状态从0变成1对整个网络能量影响的变化为
Δ E i = ∑ j > i w i j s j + ∑ j < i w j i s j + θ i \Delta E_{i}=\sum_{j>i} w_{i j} s_{j}+\sum_{j
假设有一个二部图,每一层的节点之间没有链接,一层是可视层,即输入数据层(v),一层是隐藏层(h),如果假设所有的节点都是随机二值变量节点(只能取0或者1值),同时假设全概率分布p(v,h)满足Boltzmann 分布,我们称这个模型是Restricted BoltzmannMachine (RBM)。
5.1.3Gibbs
一种采样方法
待补充
5.1.4RBM中能量的通俗解释
这里说一下 RBM 的能量模型,这里关系到 RBM 的理解 能量模型是个什么样的东西呢?直观上的理解就是,把一个表面粗糙又不太圆的小球, 放到一个表面也比较粗糙的碗里,就随便往里面一扔,看看小球停在碗的哪个地方。一般来 说停在碗底的可能性比较大,停在靠近碗底的其他地方也可能,甚至运气好还会停在碗口附 近(这个碗是比较浅的一个碗);能量模型把小球停在哪个地方定义为一种状态,每种状态都对应着一个能量E,这个能量由能量函数来定义,小球处在某种状态的概率(如停在碗底的概率跟停在碗口的概率当然不一样)可以通过这种状态下小球具有的能量来定义(换个说 法,如小球停在了碗口附近,这是一种状态,这个状态对应着一个能量E ,而发生“小球停 在碗口附近”这种状态的概率 p ,可以用E 来表示,表示成p=f(E),其中 f 是能量函数, 其实还有一个简单的理解,球在碗底的能量一般小于在碗边缘的,比如重力势能这,显然碗 底的状态稳定些,并且概率大些。 也就是说,RBM采用能量模型来表示系统稳态的一种测度。这里可以注意到 RBM 是一种随机网络,描述一个随机网络,主要有以下 2 点 :
- 概率分布函数。各个节点的取值状态是概率的、随机的,这里用了 3 种概率分布来描述 整个 RBM 网络,有联合概率密度,条件概率密度和边缘概率密度。
- 能量函数。随机神经网络的基础是统计力学,差不多思想是热力学来的,能量函数是描 述整个系统状态的一种测度。系统越有序或者概率分布越集中(比如小球在碗底的情况), 系统的能量越小,反之,系统越无序并且概率分布发散(比如平均分布) ,则系统的能量 越大,能量函数的最小值,对应着整个系统最稳定的状态。 这里跟之前提到的最大熵模型思路是一样的。
RBM 能量模型的作用是什么呢?为什么要弄清楚能量模型的作用呢? 第一、 RBM 网络是一种无监督学习的方法,无监督学习的目的自然就是最大限度的拟 合输入数据和输出数据。 第二、 对于一组输入数据来说,如果不知道它的分布,那是非常难对这个数据进行学 习的。例如:如果我们实现写出了高斯函数,就可以写出似然函数,那么就可 以进行求解,就知道大致的参数,所以实现如果不知道分布是非常痛苦的一件 事情,但是,没关系啊,统计力学的一项研究成果表明,任何概率分布都可以 转变成基于能量的模型,即使这个概率分布是未知的,我们仍然可以将这个分布改写成能量函数。 第三、 能量函数能够为无监督学习方法提供 2 个特殊的东西 a)目标函数。 b)目标解, 换句话说,使用能量模型使得学习一个数据的变得容易可行了。 能否把最优解的求解嵌入能量模型中至关重要,决定着我们具体问题求解的好坏。能量模型要捕获变量之间的相关性,变量之间的相关程度决定了能量的高低。把变量的相关关系用图表示 出来,并引入概率测度方式就构成了概率图(为什么是概率图?前面一句说了, RBM 是一个图,以概率为测度,所以是概率图)模型的能量模型。总而言之,一句话,通过定义求解网络的能量函数,我们可以得到输入样本的分布,这样我们就相当于有了目标函数,就可以训练了。(copy自参考资料(1))
5.1.5keras封装库
本文借鉴一下博客:
数学原理:
https://blog.csdn.net/Rainbow0210/article/details/53010694?locationNum=1
训练实现:
知道大致的参数,所以实现如果不知道分布是非常痛苦的一件 事情,但是,没关系啊,统计力学的一项研究成果表明,任何概率分布都可以 转变成基于能量的模型,即使这个概率分布是未知的,我们仍然可以将这个分布改写成能量函数。 第三、 能量函数能够为无监督学习方法提供 2 个特殊的东西 a)目标函数。 b)目标解, 换句话说,使用能量模型使得学习一个数据的变得容易可行了。 能否把最优解的求解嵌入能量模型中至关重要,决定着我们具体问题求解的好坏。能量模型要捕获变量之间的相关性,变量之间的相关程度决定了能量的高低。把变量的相关关系用图表示 出来,并引入概率测度方式就构成了概率图(为什么是概率图?前面一句说了, RBM 是一个图,以概率为测度,所以是概率图)模型的能量模型。总而言之,一句话,通过定义求解网络的能量函数,我们可以得到输入样本的分布,这样我们就相当于有了目标函数,就可以训练了。(copy自参考资料(1))
5.1.5keras封装库
本文借鉴一下博客:
数学原理:
https://blog.csdn.net/Rainbow0210/article/details/53010694?locationNum=1
训练实现:
https://www.jianshu.com/p/7eca07e3a2f4