docker安装solr搜索引擎
关于solr
Solr是一个独立的企业级搜索应用服务器,solr是以lucene为内核开发的企业级搜索应用 应用程序可以通过http请求方式来提交索引,查询索引,提供了比lucene更丰富的查询语言,是一个高性能,高可用环境全文搜索引擎
但是要玩转solr还先需要先了解倒排索引和分词器
什么是倒排索引?
在进行索引之前首先要进行分词,对于分词就进行一个简单的介绍
分词指的是将一个汉字序列切分成一个个单独的词。分词就是将连续的字序列按照一定的规范重新组合成词序列的过程。我们知道,在英文的行文中,单词之间是以空格作为自然分界符的,而中文只是字、句和段能通过明显的分界符来简单划界,唯独词没有一个形式上的分界符,虽然英文也同样存在短语的划分问题,不过在词这一层上,中文比之英文要复杂得多、困难得多。
常用的IK分词器,庖丁解牛分词器。。
下面介绍倒排索引:
文章表
| 文章id | 文章标题 | 文章内容 |
|---|---|---|
| 1 | 世界安全保护协会 | 我们是一个保护世界的组织 |
| 2 | 世界卫生清洁协会 | 清理,清洁,干净,卫生 |
倒排索引:
| 索引 | 文章id |
|---|---|
| 世界 | 1,2 |
| 安全 | 1 |
| 保护 | 1 |
| 协会 | 1,2 |
| 卫生 | 2 |
| 清洁 | 2 |
意思为如果查询世界的话,会查出文章id1和2的文章内容
查询安全的话,只查出文章id为1的文章内容
俩者都是比较的粗浅的介绍了一下,不过了解一点点倒排和分词对solr也会有帮助。
如要更详细的了解的话如下:
这是关于倒排索引和分词器的一些介绍转载于博客园
https://www.cnblogs.com/zlslch/p/6440373.html
Solr支持使用json格式提交数据。
json格式:
[] 代表数组
{} 代表对象(文档 document)
键值对 代表属性
{
id:1
hobby:["篮球","上厕所"]
tt:{
}
}
用数据库表结构来展示:
文章表
| 文章id | 文章标题 | 文章内容 |
|---|---|---|
| 1 | 一个团的兵力来干我 | 在xxxx年xx月xx日某男子被一个团的兵给干了 |
| 2 | p某减肥成功发出猪叫声 | p某减肥成功这你也信,发出猪叫到是真的 |
模拟json
[
{
id:1,
title:"一个团的兵力来干我",
content:"在xxxx年xx月xx日某男子被一个团的兵给干了"
},
{
id:2,
title:" p某减肥成功发出猪叫声",
content:"p某减肥成功这你也信,发出猪叫到是真的"
}
]
核(core):是用于存储json格式的数据,等价于mysql中数据库的概念
文档:一个json对象就是一个文档 相同属性的json数组集合就是一个表
安装solr
了解之后安装solr
点击 进入docker官网查看solr版本和安装信息
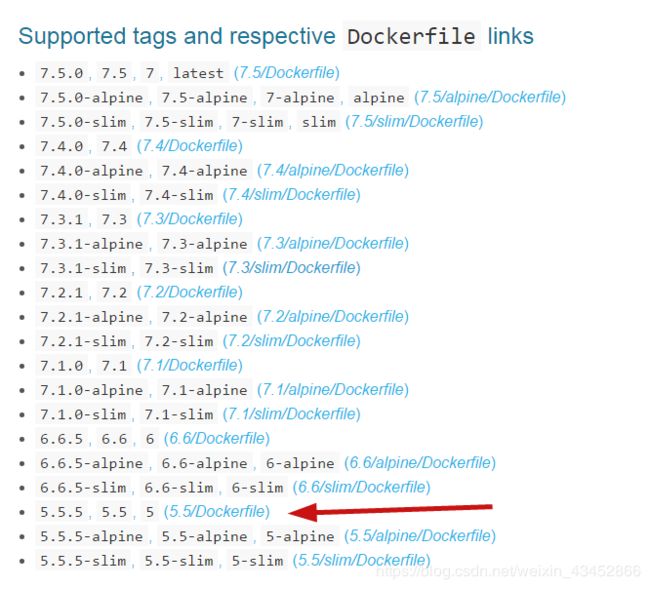
在这些版本里我选择的是5.5.5版本因为官方文档只更新到5.5.5版本
打开虚拟机输入命令(注意版本):
查看solr版本
docker search solr
下载solr(注意版本)
docker pull solr:5.5.5
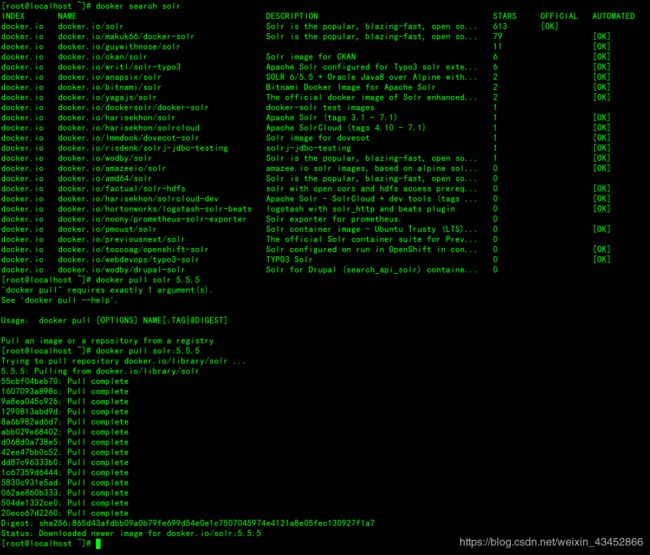
下载镜像成功然后进入下一步
安装solr

`在页面可以看到该命令,该命令使用的是端口映射但是我要使用仅主机模式所以输入命令
docker run --name my_solr -idt --net host solr:5.5.5
完成后输入查看容器命令:
docker ps -a
得到下图表示已经在后台运行

它会默认开辟一个8983的端口,再输入检测端口命令netstat -aon | grep 8983
也可以到主机的黑窗口cmd输入telnet 虚拟机ip地址 8983查询
如果没有该命令输入yum -y install net-tools
安装诊断软件
查询成功会出现该图 失败无数据表示安装失败
![]()
创建core:docker exec -it --user=solr my_solr bin/solr create_core -c mycore
命令解析:--user=solr用默认启动容器自动创建solr用户执行命令
-c mycore-c=命名,mycore=名称
创建成功后出现一段代码:
Copying configuration to new core instance directory:
/opt/solr/server/solr/mycore ==== 插入的数据所存储的路径(核(core)路径)
Creating new core 'mycore' using command:
http://localhost:8983/solr/admin/cores?action=CREATE&name=mycore&instanceDir=mycore
{core核的状态
"responseHeader":{
"status":0, === 容器里为空
"QTime":2940}, === 用多少时间创建成功毫秒单位
"core":"mycore"} === core核的名字
也可以用这种http网页创建(比较底层的东西)
http://localhost:8983/solr/admin/cores?action=CREATE&name=mycore&instanceDir=mycore
然后就可以用网页访问了 !!!注意关闭防火墙systemctl stop firewalld (当前回话下 关闭防火墙)!!!
虚拟机ip地址:8983/solr/#/
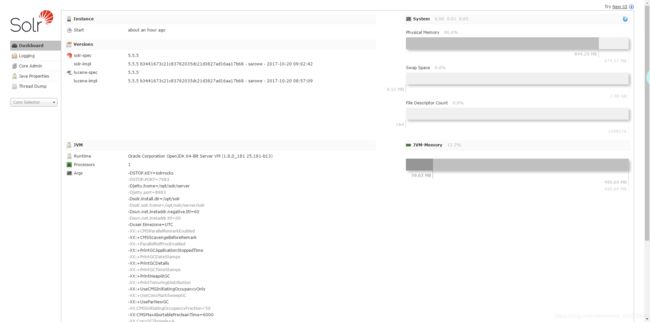
如果访问成功会跳转到这个页面 失败查看防火墙是否关闭
网页状态图
在这里插入图片描述
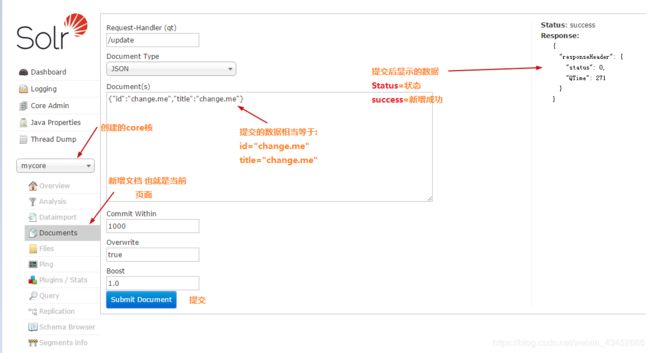
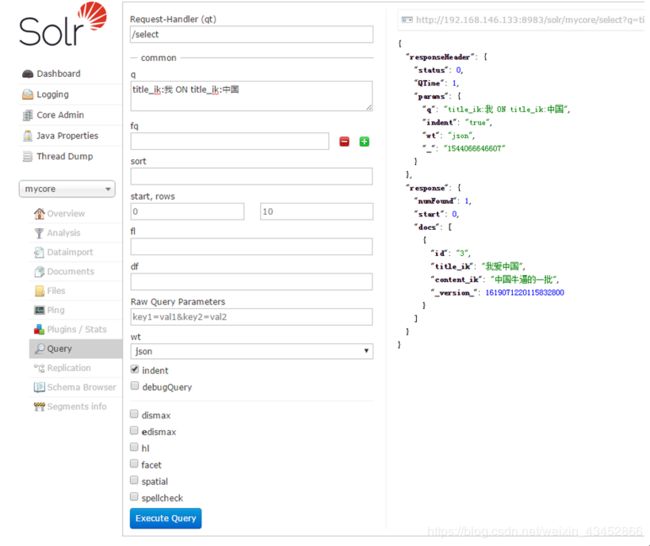
查询的页面

fq表示filter query 过滤条件 和q是and的关系支持各种逻辑运算符 (参考https://cwiki.apache.org/confluence/display/solr/The+Standard+Query+Parser)
sort表示排序 的字段 字段名 asc|desc
start 表示从第几行开始 rows表示查询的总行数
fl表示查询显示的列 比如只需要查询 name_s,sex_i 这两列 使用,隔开
df表示默认的查询字段 一般不设置
Raw Query Parameters表示原始查询字段 可以使用 start=0&rows=10这种url的方式传入参数
wt(write type)表示写入的格式 可以使用json和xml
shards 多核同时搜索 solrhome拷贝mycore为mycore1 管理平台添加core 设置参数为 路径,路径来设置需要搜索的核
现在暂时是全文匹配查询所以要做分词
常用的IK分词器,庖丁解牛分词器。
Ik分词器不支持solr5.5.5版本之后的版本包括5.5.5版本 所以要编译Ik分词器
在任意项目中 使用maven 引用lucene5 和ik
com.janeluo
ikanalyzer
2012_u6
然后搜索IKAnalyzer打开 自己创建一个同样的包和同样的文件
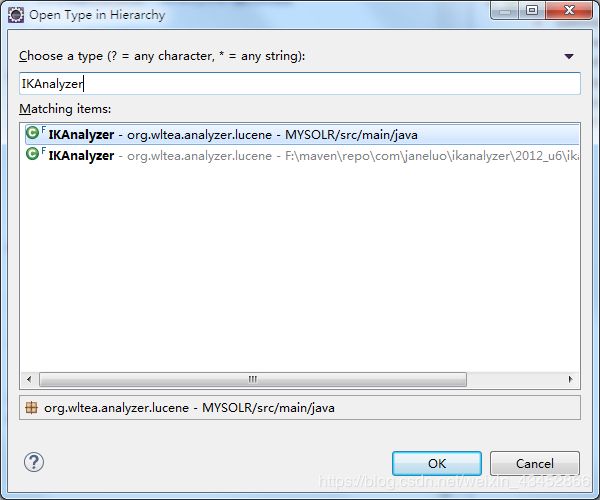
![]()
进入IKAnalyzer 包里重写createComponents方法 把in删除
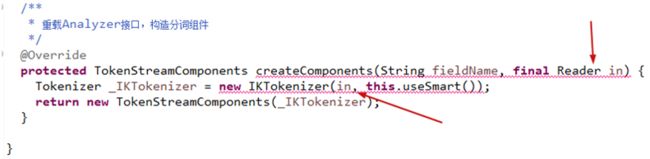
然后进入IKTokenizer 方法照IKAnalyzer 自己写一个一样的包和类,删除俩个in相关的

依赖重写编译一下
com.janeluo
ikanalyzer
2012_u6
org.apache.lucene
lucene-core
org.apache.lucene
lucene-queryparser
org.apache.lucene
lucene-analyzers-common
org.apache.lucene
lucene-core
5.5.5
org.apache.lucene
lucene-queryparser
5.5.5
org.apache.lucene
lucene-analyzers-common
5.5.5
大概意思是剔除4.7版本的,移植5.5.5版本的配置
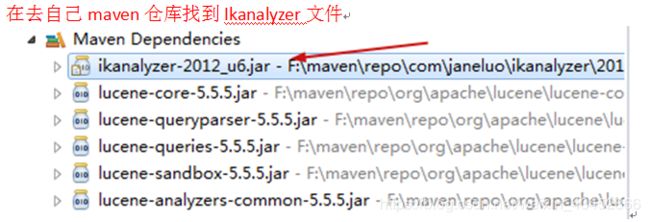
用压缩包工具打开
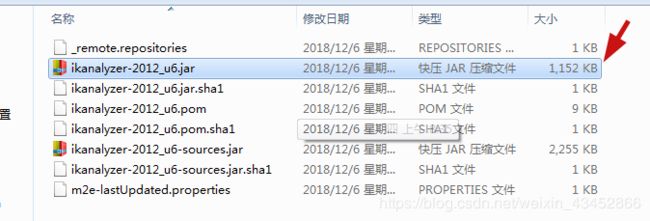
用压缩包工具打开,找到自己编译的俩个ik分词器class文件,然后替换这个俩个文件, 注意 是自己已经编译好的俩个class文件
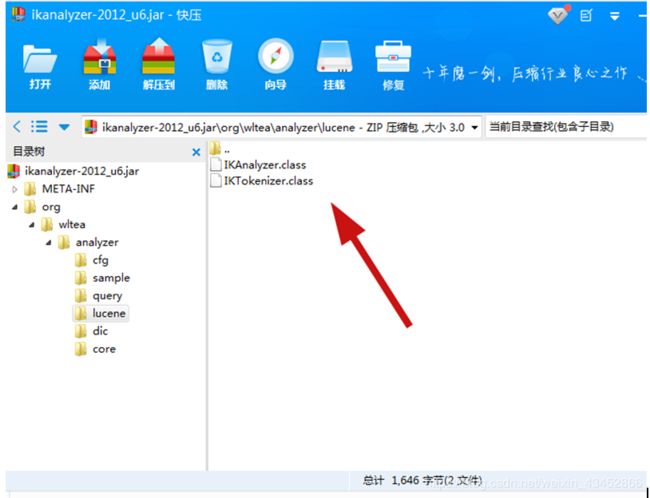
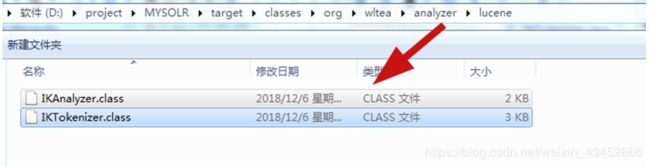
配置solr中文分词器
Solr本身不支持中文分词,所以要把我们编译的包上传到solr上
在虚拟机上opt目录创建一个目录
cd /opt mkdir ik
然后使用rz软件上传
( yum 安装文件上传工具
yum search sz
yum install lrzsz
rz 就是选择文件上传到linux的工作目录)
进入solr容器 用find . -name lib命令搜索当前目录下所有lib包得出

找到箭头路径然后进入该文件,里面就是之前打开的网页页面目录,使用的是weblogic部署,把路径复制下来
退出容器到之前cp下来的文件路径里把ik传入到solr容器复制路径里
docker cp ./ikanalyzer-2012_u6.jar my_solr:/opt/solr/server/solr-webapp/webapp/WEB-INF/lib
cp成功后重启容器
docker stop my_solr
docker start my_solr

进入solr容器找到之前的核(core)路径进去之后找到conf文件夹并进入,ls 显示当前路径的文件 可以看到managed-schema文件
core/conf目录下的两个配置文件非常重要
managed-schema 主要用于配置 可以提交到该core的所有field定义,field的类型定义,唯一标识符等
定义字段 _version_ 类型为long indexed="true" 会进行分词索引 stored="true"表示存储到磁盘
id
定义字段类型的别名
solrconfig.xml 主要用于配置solor的主要配置信息 比如lucene版本 缓存 数据目录 请求路径映射 等
表示lucene版本
5.5.4
表示数据目录 默认是data目录
${solr.data.dir:}
自动提交配置
当超过15000ms后自动提交所有数据
${solr.autoCommit.maxTime:15000}
是否马上就可以查询到
false
表示当路径为 /select时查询所有的数据
explicit
10
退出容器,cp一份managed-schema出来
docker cp my_solr:/opt/solr/server/solr/mycore/conf/managed-schema ./
打开文件查看:

箭头指向为主键id,当在新增数据的时候如没有设置id值那么默认会随机赋一个随机值
如要修改主键只需要修改该文件的id即可
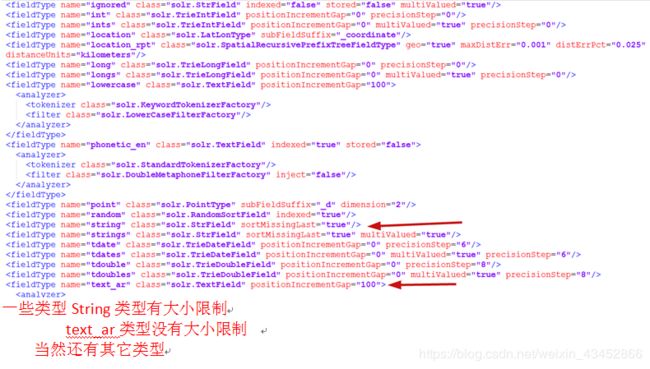

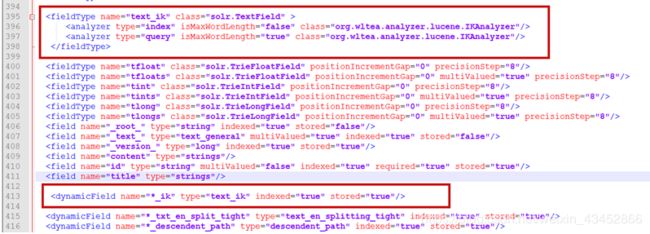
将solrhome下 配置文件managed-schema 添加一个字段类型 使用ik分词器
然后将对应需要进行中文分词的字段使用 text_ik该字段类型 如
之后再cp回去
docker cp ./managed-schema my_solr:/opt/solr/server/solr/mycore/conf
重启一下容器
docker stop my_solr
docker start my_solr
到页面插入json
{
"id":"3",
"title_ik":"我爱中国",
"content_ik":"中国牛逼的一批"
}
注意如果页面登录不上那么就是jar包出错了

输入查询
title_ik:我 ON title_ik:中国