GAN网络学习之DCGAN(二)
初识DCGAN
问:什么是DCGAN?
答:DC意为deep convolution,它把卷积神经网络应用在对抗生成网络中。
问:DCGAN相对于GAN做了哪些改变?
答:有以下几点:
(1)池化层pooling被卷积层convolution代替,网络结构中没有池化层。
具体而言,在生成模型中,允许卷积层代替池化层完成空间上采样的学习;
在判别模型中,允许卷积层代替池化层完成空间下采样的学习;
(2)在生成模型和判别模型中使用batchnorm。解决的问题是1)初始化差的问题;2)梯度消失、弥散等问题;3)防止生成模型把所有样本收敛于同一点;
(3)相比CNN移除了全连接层;
(4)使用激活函数不同,生成模型中出输出层使用tanh外,其他全部采用 Relu;判别模型全部采用Leaky ReLU。
DCGAN网络结构
1 G网络
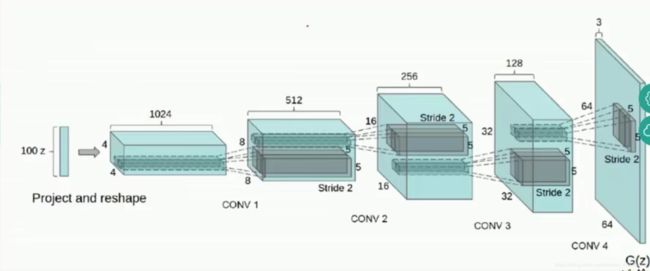
100z代表一个100维的噪音向量,先通过一个简单的全连接层reshape成4X4X1024的特征图形式,再通过四层CONV层实现反卷积,最终输出一个64X64X3的图片。
2 D网络
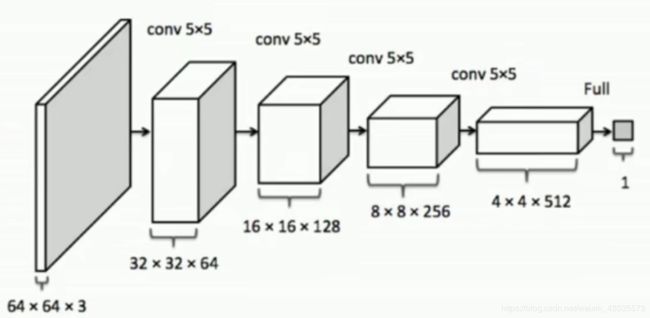
代码讲解
1 数据及代码
数据:人脸数据 提取码:c8u3
卡通图像 提取码:6u6m
DCGAN代码提取码:umsx
2 代码讲解
(1)创建结构
main.py文件
dcgan = DCGAN(
sess,
input_width=FLAGS.input_width, //输入输出数据的大小
input_height=FLAGS.input_height,
output_width=FLAGS.output_width,
output_height=FLAGS.output_height,
batch_size=FLAGS.batch_size, //一次迭代用到图像的数量
c_dim=FLAGS.c_dim, //通道数,黑白为1,彩色为3
dataset_name=FLAGS.dataset, //数据集名字
input_fname_pattern=FLAGS.input_fname_pattern,
is_crop=FLAGS.is_crop, //是否进行crop
checkpoint_dir=FLAGS.checkpoint_dir, //存储模型参数的路径
sample_dir=FLAGS.sample_dir)
model.py文件
class DCGAN(object):
def __init__(self, sess, input_height=108, input_width=108, is_crop=True,
batch_size=64, sample_num = 64, output_height=64, output_width=64,
y_dim=None, z_dim=100, gf_dim=64, df_dim=64,
gfc_dim=1024, dfc_dim=1024, c_dim=3, dataset_name='default',
input_fname_pattern='*.jpg', checkpoint_dir=None, sample_dir=None):
self.sess = sess
self.is_crop = is_crop
self.is_grayscale = (c_dim == 1)
self.batch_size = batch_size
self.sample_num = sample_num
self.input_height = input_height
self.input_width = input_width
self.output_height = output_height
self.output_width = output_width
self.y_dim = y_dim
self.z_dim = z_dim //生成模型输入数据的维度
self.gf_dim = gf_dim //filter大小的基数
self.df_dim = df_dim
self.gfc_dim = gfc_dim //全连接层的大小
self.dfc_dim = dfc_dim
self.c_dim = c_dim
# batch normalization : deals with poor initialization helps gradient flow
self.d_bn1 = batch_norm(name='d_bn1') //判别模型:3层batchnorm;生成模型:4层batchnorm
self.d_bn2 = batch_norm(name='d_bn2')
if not self.y_dim:
self.d_bn3 = batch_norm(name='d_bn3')
self.g_bn0 = batch_norm(name='g_bn0')
self.g_bn1 = batch_norm(name='g_bn1')
self.g_bn2 = batch_norm(name='g_bn2')
if not self.y_dim:
self.g_bn3 = batch_norm(name='g_bn3')
self.dataset_name = dataset_name
self.input_fname_pattern = input_fname_pattern
self.checkpoint_dir = checkpoint_dir
self.build_model()
定义判别模型有两种输入(model.py的build_model(self)):
self.inputs = tf.placeholder(
tf.float32, [self.batch_size] + image_dims, name='real_images')
self.sample_inputs = tf.placeholder(
tf.float32, [self.sample_num] + image_dims, name='sample_inputs')
batchnorm的位置是:conv之后,relu之前
self.h0 = tf.reshape(
self.z_, [-1, s_h16, s_w16, self.gf_dim * 8]) //将输入向量转化成特征图形式
h0 = tf.nn.relu(self.g_bn0(self.h0)) //conv之后,batchnorm ,然后relu
反卷积
self.h1, self.h1_w, self.h1_b = deconv2d(
h0, [self.batch_size, s_h8, s_w8, self.gf_dim*4], name='g_h1', with_w=True)
h1 = tf.nn.relu(self.g_bn1(self.h1))
(2)训练
def train(self, config):
"""Train DCGAN"""
if config.dataset == 'mnist':
data_X, data_y = self.load_mnist()
else:
data = glob(os.path.join("./data", config.dataset, self.input_fname_pattern))
#np.random.shuffle(data)
d_optim = tf.train.AdamOptimizer(config.learning_rate, beta1=config.beta1) \
.minimize(self.d_loss, var_list=self.d_vars)
g_optim = tf.train.AdamOptimizer(config.learning_rate, beta1=config.beta1) \
.minimize(self.g_loss, var_list=self.g_vars)
try:
tf.global_variables_initializer().run()
except:
tf.initialize_all_variables().run()
self.g_sum = merge_summary([self.z_sum, self.d__sum,
self.G_sum, self.d_loss_fake_sum, self.g_loss_sum])
self.d_sum = merge_summary(
[self.z_sum, self.d_sum, self.d_loss_real_sum, self.d_loss_sum])
self.writer = SummaryWriter("./logs", self.sess.graph)
sample_z = np.random.uniform(-1, 1, size=(self.sample_num , self.z_dim))
if config.dataset == 'mnist':
sample_inputs = data_X[0:self.sample_num]
sample_labels = data_y[0:self.sample_num]
else:
sample_files = data[0:self.sample_num]
sample = [
get_image(sample_file,
input_height=self.input_height,
input_width=self.input_width,
resize_height=self.output_height,
resize_width=self.output_width,
is_crop=self.is_crop,
is_grayscale=self.is_grayscale) for sample_file in sample_files]
if (self.is_grayscale):
sample_inputs = np.array(sample).astype(np.float32)[:, :, :, None]
else:
sample_inputs = np.array(sample).astype(np.float32)
counter = 1
start_time = time.time()
if self.load(self.checkpoint_dir):
print(" [*] Load SUCCESS")
else:
print(" [!] Load failed...")
for epoch in xrange(config.epoch):
if config.dataset == 'mnist':
batch_idxs = min(len(data_X), config.train_size) // config.batch_size
else:
data = glob(os.path.join(
"./data", config.dataset, self.input_fname_pattern))
batch_idxs = min(len(data), config.train_size) // config.batch_size
for idx in xrange(0, batch_idxs):
if config.dataset == 'mnist':
batch_images = data_X[idx*config.batch_size:(idx+1)*config.batch_size]
batch_labels = data_y[idx*config.batch_size:(idx+1)*config.batch_size]
else:
batch_files = data[idx*config.batch_size:(idx+1)*config.batch_size]
batch = [
get_image(batch_file,
input_height=self.input_height,
input_width=self.input_width,
resize_height=self.output_height,
resize_width=self.output_width,
is_crop=self.is_crop,
is_grayscale=self.is_grayscale) for batch_file in batch_files]
if (self.is_grayscale):
batch_images = np.array(batch).astype(np.float32)[:, :, :, None]
else:
batch_images = np.array(batch).astype(np.float32)
batch_z = np.random.uniform(-1, 1, [config.batch_size, self.z_dim]) \
.astype(np.float32)
if config.dataset == 'mnist':
# Update D network
_, summary_str = self.sess.run([d_optim, self.d_sum],
feed_dict={
self.inputs: batch_images,
self.z: batch_z,
self.y:batch_labels,
})
self.writer.add_summary(summary_str, counter)
# Update G network
_, summary_str = self.sess.run([g_optim, self.g_sum],
feed_dict={
self.z: batch_z,
self.y:batch_labels,
})
self.writer.add_summary(summary_str, counter)
# Run g_optim twice to make sure that d_loss does not go to zero (different from paper)
_, summary_str = self.sess.run([g_optim, self.g_sum],
feed_dict={ self.z: batch_z, self.y:batch_labels })
self.writer.add_summary(summary_str, counter)
errD_fake = self.d_loss_fake.eval({
self.z: batch_z,
self.y:batch_labels
})
errD_real = self.d_loss_real.eval({
self.inputs: batch_images,
self.y:batch_labels
})
errG = self.g_loss.eval({
self.z: batch_z,
self.y: batch_labels
})
else:
# Update D network
_, summary_str = self.sess.run([d_optim, self.d_sum],
feed_dict={ self.inputs: batch_images, self.z: batch_z })
self.writer.add_summary(summary_str, counter)
# Update G network
_, summary_str = self.sess.run([g_optim, self.g_sum],
feed_dict={ self.z: batch_z })
self.writer.add_summary(summary_str, counter)
# Run g_optim twice to make sure that d_loss does not go to zero (different from paper)
_, summary_str = self.sess.run([g_optim, self.g_sum],
feed_dict={ self.z: batch_z })
self.writer.add_summary(summary_str, counter)
errD_fake = self.d_loss_fake.eval({ self.z: batch_z })
errD_real = self.d_loss_real.eval({ self.inputs: batch_images })
errG = self.g_loss.eval({self.z: batch_z})
counter += 1
print("Epoch: [%2d] [%4d/%4d] time: %4.4f, d_loss: %.8f, g_loss: %.8f" \
% (epoch, idx, batch_idxs,
time.time() - start_time, errD_fake+errD_real, errG))
if np.mod(counter, 100) == 1:
if config.dataset == 'mnist':
samples, d_loss, g_loss = self.sess.run(
[self.sampler, self.d_loss, self.g_loss],
feed_dict={
self.z: sample_z,
self.inputs: sample_inputs,
self.y:sample_labels,
}
)
save_images(samples, [8, 8],
'./{}/train_{:02d}_{:04d}.png'.format(config.sample_dir, epoch, idx))
print("[Sample] d_loss: %.8f, g_loss: %.8f" % (d_loss, g_loss))
else:
try:
samples, d_loss, g_loss = self.sess.run(
[self.sampler, self.d_loss, self.g_loss],
feed_dict={
self.z: sample_z,
self.inputs: sample_inputs,
},
)
save_images(samples, [8, 8],
'./{}/train_{:02d}_{:04d}.png'.format(config.sample_dir, epoch, idx))
print("[Sample] d_loss: %.8f, g_loss: %.8f" % (d_loss, g_loss))
except:
print("one pic error!...")
if np.mod(counter, 100) == 2:
self.save(config.checkpoint_dir, counter)