Scrapy常见问题
介绍下scrapy框架。
scrapy 是一个快速(fast)、高层次(high-level)的基于 python 的 web 爬虫构架,用于抓取web站点并从页面中提取结构化的数据。scrapy 使用了 Twisted异步网络库来处理网络通讯。
为什么要使用scrapy框架?scrapy框架有哪些优点?
它更容易构建大规模的抓取项目
它异步处理请求,速度非常快
它可以使用自动调节机制自动调整爬行速度
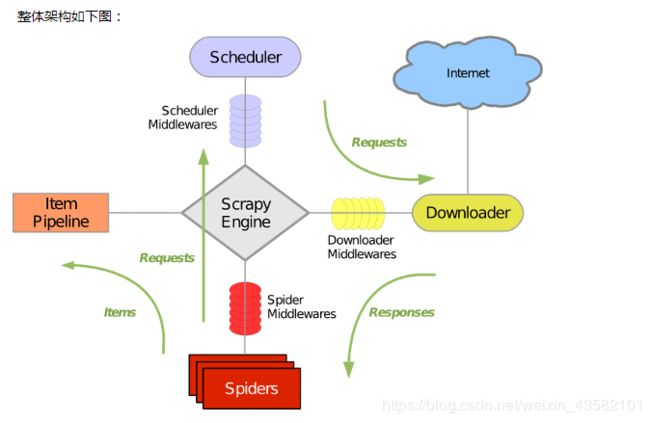
scrapy框架有哪几个组件/模块?简单说一下工作流程。
scrapy的去重原理
- 1.找到Request类:需要将dont_filter设置为False开启去重,默认是True,没有开启去重;
- 2.对于每一个url的请求,调度器都会根据请求得相关信息加密得到一个指纹信息,并且将指纹信息和set()集合中的指纹信息进行比对,如果set()集合中已经存在这个数据,就不在将这个Request放入队列中。如果set()集合中没有存在这个加密后的数据,就将这个Request对象放入队列中,等待被调度。
scrapy中间件有哪几种类,你用过哪些?
下载中间件,
- 爬虫发起请求request的时候调用,列如更换修改代理ip,修改UA
爬虫中间件
- 浏览器返回响应response的时候调用,无效的数据,特殊情况进行重试
scrapy如何实现大文件的下载?
当使用requests的get下载大文件/数据时,建议使用使用stream模式。
当把get函数的stream参数设置成False时,它会立即开始下载文件并放到内存中,如果文件过大,有可能导致内存不足。
当把get函数的stream参数设置成True时,它不会立即开始下载,当你使用iter_content或iter_lines遍历内容或访问内容属性时才开始下载。需要注意一点:文件没有下载之前,它也需要保持连接。
iter_content:一块一块的遍历要下载的内容
iter_lines:一行一行的遍历要下载的内容
使用上面两个函数下载大文件可以防止占用过多的内存,因为每次只下载小部分数据。
Scrapy 相 BeautifulSoup 或 lxml 比较,如何呢?
BeautifulSoup 及 lxml 是 HTML 和 XML 的分析库。Scrapy 则是 编写爬虫,爬取网页并获取数据的应用框架(application framework)。Scrapy 提供了内置的机制来提取数据(叫做 选择器(selectors))。
但如果您觉得使用更为方便,也可以使用 BeautifulSoup(或 lxml)。 总之,它们仅仅是分析库,可以在任何 Python 代码中被导入及使用。换句话说,拿 Scrapy 与 BeautifulSoup (或 lxml) 比较就好像是拿 jinja2 与 Django 相比。
Scrapy 支持 HTTP 代理么?
是的。(从 Scrapy 0.8 开始)通过 HTTP 代理下载中间件对 HTTP 代理提供了支持。参考 HttpProxyMiddleware 。
Scrapy 是以广度优先还是深度优先进行爬取的呢?
默认情况下,Scrapy 使用 LIFO 队列来存储等待的请求。简单的说,就是深度优先顺序。深度优先对大多数情况
下是更方便的。如果您想以 广度优先顺序 进行爬取,你可以设置以下的设定:
DEPTH_PRIORITY = 1
SCHEDULER_DISK_QUEUE = 'scrapy.squeue.PickleFifoDiskQueue'
SCHEDULER_MEMORY_QUEUE = 'scrapy.squeue.FifoMemoryQueue'
为什么 Scrapy 下载了英文的页面,而不是我的本国语言?
尝试通过覆盖 DEFAULT_REQUEST_HEADERS 设置来修改默认的 Accept-Language 请求头。
我能在不创建 Scrapy 项目的情况下运行一个爬虫(spider)么?
是的。您可以使用 runspider 命令。例如,如果您有个 spider 写在 my_spider.py 文件中,您可以运行:
scrapy runspider my_spider.py
我收到了 “Filtered offsite request” 消息。如何修复?
这些消息(以 DEBUG 所记录)并不意味着有问题,所以你可以不修复它们。这些消息由 Offsite Spider 中间件(Middleware)所抛出。 该(默认启用的)中间件筛选出了不属于当前 spider 的站点请求。
我能对大数据(large exports)使用 JSON 么?
这取决于您的输出有多大。参考 JsonItemExporter 文档中的 这个警告 。我能在信号处理器(signal handler)中返回(Twisted)引用么? 有些信号支持从处理器中返回引用,有些不行。
将所有爬取到的 item 转存(dump)到 JSON/CSV/XML 文件的最简单的方法?
dump 到 JSON 文件:
scrapy crawl myspider -o items.json
dump 到 CSV 文件:
scrapy crawl myspider -o items.csv
dump 到 XML 文件:
scrapy crawl myspider -o items.xml
分析大 XML/CSV 数据源的最好方法是?
使用 XPath 选择器来分析大数据源可能会有问题。选择器需要在内存中对数据建立完整的 DOM 树,这过程速度很慢且消耗大量内存。
为了避免一次性读取整个数据源,您可以使用 scrapy.utils.iterators 中的 xmliter 及 csviter 方法。 实际上,这也是 feed spider(参考 Spiders )中的处理方法。
Scrapy 自动管理 cookies 么?
是的,Scrapy 接收并保持服务器返回来的 cookies,在之后的请求会发送回去,就像正常的网页浏览器做的那样。
我应该使用 spider 参数(arguments)还是设置(settings)来配置 spider 呢?
spider 参数 及 设置(settings) 都可以用来配置您的 spider。没有什么强制的规则来限定要使用哪个,但设置(se
ttings)更适合那些一旦设置就不怎么会修改的参数,而 spider 参数则意味着修改更为频繁,在每次 spider 运行
都有修改,甚至是 spider 运行所必须的元素 (例如,设置 spider 的起始 url)。
这里以例子来说明这个问题。假设您有一个 spider 需要登录某个网站来 爬取数据,并且仅仅想爬取特定网站的特定部分(每次都不一定相同)。 在这个情况下,认证的信息将写在设置中,而爬取的特定部分的 url 将是 spider。