OpenCv学习笔记3(图像识别:检测直线和圆, 图像分割,SURF特征匹配)
1.用霍夫变换检测直线和圆
霍尔夫变换是图像处理中从图像中识别几何形状的基本方法之一。
原理:在原始图像坐标系下的一个点(直线)对应了参数坐标系下的一条直线(点)。
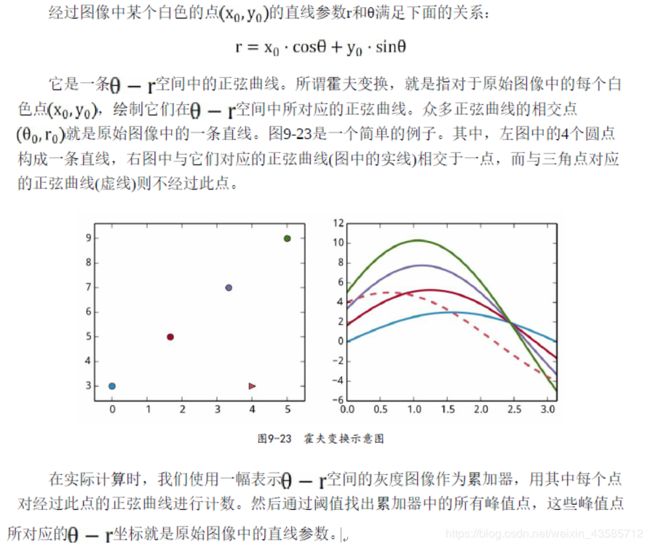
OpenCV提供了如下三种霍夫变换相关的函数:
HoughLines:检测图像中的直线。
HoughLinesP:检测图像中的直线段。
HoughCircles:检测图像中的圆。
HoughLinesP(image, rho, theta, threshold[, lines[, minLineLength[, maxLineGap]]])
image参数为进行直线检测的图像
rho和theta参数分别为累加器中每个点所表示的r和θ的大小。其中rho的单位是像素点,而theta是以弧度表示的角度。
值越小则累加器 的尺寸越大,最后找出的直线的参数的精度越高,但是运算时间也越长。
threshold参数是 在累加器中寻找峰值时所使用的阈值,即只有大于此值的峰值点才被当作与某条直线相对 应。
由于HoughLinesP()检测的是图像中的线段,因此minLineLength参数指定线段的最小长度。
maxLineGap参数则指定线段的最大间隙。当有多条线段共线时,间隙小于此值 线段将被合并为一条线段。
下面是检测图像中的直线
import cv2
import numpy as np
import matplotlib.pyplot as pl
pl.rcParams["font.family"] = "SimHei"#直接修改配置字典,设置默认字体
img = cv2.imread("E:/ruanjianDM/jupyternoerbookDM/picture/building.jpg",0)
#输入图像进行边缘检测,得到一个二值图像
#(输入图像,阈值1,阈值2)阈值越小,从图像中检测的细节越多
img_binary = cv2.Canny(img, 100, 255)
#(被检测的图像,累加器参数,,在累加器中寻找峰值时所使用的阈值,线段的最小长度,线段的最大间隙)
#HoughLinesP()的返回值是一个形状为(N,1,4)的数组,其中N为线段数,第二轴的4个元素为线段的起点和终点:x0、y0、x1、y1。
lines = cv2.HoughLinesP(img_binary, rho=1, theta=np.deg2rad(0.1),#度数转为弧度
threshold=96, minLineLength=33,maxLineGap=4)#(85,1,4)
fig, ax = pl.subplots(figsize=(8, 6))
pl.imshow(img, cmap="gray")
from matplotlib.collections import LineCollection
lc = LineCollection(lines.reshape(-1, 2, 2))
ax.add_collection(lc)
ax.axis("off")

检测圆形的HoughCircles()的参数如下:
HoughCircles(image, method, dp, minDist [, circles[, param1[, param2[, minRadius[, maxRadius]]]]])
method参数为圆形检测的算法,目前OpenCV中只实现了一种检测算法:CV_HOUGH_GRADIENTP
dp参数和直线检测中的rho参数类似,决定了检测的精度, dp=1时累加器的分辨率和输入图像相同,而dp=2时累加器的分辨率为输入图像的一半。
minDist参数是检测到的所有圆的圆心之间的最小距离,当它过小时会检测出很多近似的圆形,若过大则可能会漏掉一些结果。
param1参数相当于边缘检测Canny()的第二个阈值,Canny()的第一个阈值自动设置为它的一半。
param2参数是累加器上的阈值,它的值越小检测出的圆形越多。
minRadius和maxRadius参数指定圆形的半径范围,缺省都为0表示范围不限。
下面是检测图像中的圆
import cv2
import numpy as np
import matplotlib.pyplot as pl
pl.rcParams["font.family"] = "SimHei"#直接修改配置字典,设置默认字体
img = cv2.imread("E:/ruanjianDM/jupyternoerbookDM/picture/coins.png",0)
#为了获得较好的边缘检测结果,调用GaussianBlur()对图像进行模糊处理。
img_blur = cv2.GaussianBlur(img, (0, 0), 1.8)
circles = cv2.HoughCircles(img_blur, cv2.HOUGH_GRADIENT,dp=2.0, minDist=20.0,
param1=170, param2=44, minRadius=16, maxRadius=40)#(1,24,3)
x, y, r = circles[0].T#(1,24,3)变成(24,3)。第一列给x,2-y,3-r
fig, ax = pl.subplots(figsize=(8, 6))
pl.imshow(img, cmap="gray")
from matplotlib.collections import EllipseCollection
#使用EllipseCollection快速绘制多个圆形
ec = EllipseCollection(widths=2*r, heights=2*r, angles=0, units="xy",
facecolors="none", edgecolors="red",transOffset=ax.transData, offsets=np.c_[x, y])
ax.add_collection(ec)
ax.axis("off")

2.图像分割
一般的图像中颜色丰富、信息繁杂,不利于计算机进行图像识别。因此通常会使用图像分割技术,将图像中相似的区域进行合并,使得图像更容易理解和分析。下面介绍OpenCV中提供的两种常见的图像分割算法。
2.1Mean-Shift算法
pyrMeanShiftFiltering()使用Mean-Shift算法对图像进行分割。它的调用参数如下:
pyrMeanShiftFiltering(src, sp, sr[, dst[, maxLevel[, termcrit]]])
fig, axes = pl.subplots(1, 3, figsize=(9, 3))
img = cv2.imread("E:/ruanjianDM/jupyternoerbookDM/picture/fruits.jpg")
srs = [20, 40, 80]
for ax, sr in zip(axes, srs):
img2 = cv2.pyrMeanShiftFiltering(img, sp=20, sr=sr, maxLevel=1)
ax.imshow(img2[:,:,::-1])
ax.set_axis_off()
ax.set_title("sr = {}".format(sr))
fig.subplots_adjust(0.02, 0, 0.98, 1, 0.02, 0)

2.2分水岭算法(重要)
分水岭算法(Watershed)的基本思想是将图像的梯度当作地形图。图像中变化小的区域相当于地形图中的山谷,而变化大的区域相当于山峰。从指定的几个初始区域同时开始向地形灌不同数值的水,水面上升逐渐淹没山谷,并且范围逐渐扩大。
watershed()实现此算法,它的调用形式如下:
watershed(image, markers)
image参数是需要进行分割处理的图像,它必须是一个3通道8位图像。
markers参数是一个32位整数数组,其大小必须和image相同。 markers中值大于0的点构成初始灌溉区域,其值可以理解为水的颜色。
调用watershed()之后,markers中几乎所有的点都将被赋值为某个初始区域的值,而在两个区域的境界线上的点将被赋值为-1。
import cv2
import numpy as np
import matplotlib.pyplot as pl
pl.rcParams["font.family"] = "SimHei"#直接修改配置字典,设置默认字体
fig, axes = pl.subplots(1, 2, figsize=(10, 6))
a0,a1=axes[0],axes[1]
img = cv2.imread("E:/ruanjianDM/jupyternoerbookDM/picture/pills.png")
img_gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
a0.imshow(img_gray,cmap='gray')
#先调用blur()对药丸的灰度图像进行模糊处理,这样可以有效消除噪声,减少局域最值的个数。
img_gray = cv2.blur(img_gray, (15, 15))
_, img_binary = cv2.threshold(img_gray, 150, 255, cv2.THRESH_BINARY)
#局域最亮像素就是比周边临近的像素都亮的像素,使用dilate()对灰度图像进行膨胀处
#理,将每个像素都设置为邻近像素中的最大值,然后与原始图像中的值比较,如果值保持
#不变,该像素即为局域最亮像素。
peaks = img_gray == cv2.dilate(img_gray, np.ones((7, 7)), 1)
peaks =peaks*img_binary#非零值为局部最亮,其余为0值
peaks[1, 1] = True #设置初始值
from scipy.ndimage import label
markers, count = label(peaks) #对区域进行编号
marks=cv2.watershed(img, markers)#边界值为-1
img2=img
img2[marks == -1] = [0,0,255]
a1.imshow(img2)
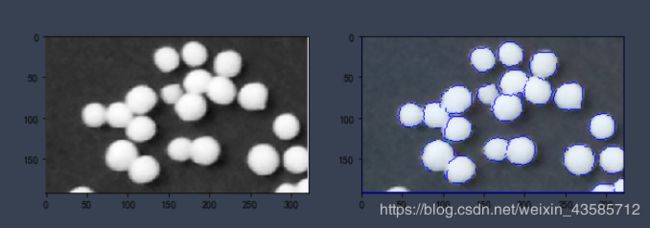
还在继续学习相关编程。
3.SURF特征匹配
SURF是一种快速提取图像特征点的算法,它所提取的图像特征具有缩放和旋转的不变性,而且它对图像的灰度变化也不敏感。对SURF算法的详细介绍还有待研究,这里只简单地介绍OpenCV中SURF类的用法。
对一副图像找关键点
import cv2
import numpy as np
import matplotlib.pyplot as pl
pl.rcParams["font.family"] = "SimHei"#直接修改配置字典,设置默认字体
img_gray1 = cv2.imread("E:/ruanjianDM/jupyternoerbookDM/picture/lena.jpg",0)
#然后创建SURF()对象,并设置hessianThreshold和nOctaves参数,这两个参数为计算关键点的参数,
#hessianThreshold越大则关键点的个数越少,nOctaves越大则关键点的尺寸范围越大。
surf = cv2.xfeatures2d.SURF_create (2000, 2)
#调用detect()方法从灰度图像中检测出关键点。
#它返回一个列表key_points,其中每个元素都是一个保存关键点信息的KeyPoint对象。
key_points1 = surf.detect(img_gray1)
#根据关键点的size属性按照从大到小的顺序排列关键点
key_points1.sort(key=lambda x:x.size, reverse=True)
#灰度图像通过cvtColor()转换成灰色的RGB格式的图像
img_color1 = cv2.cvtColor(img_gray1, cv2.COLOR_GRAY2RGB)
#调用drawKeypoints()可以在图像上绘制关键点
#(绘制的图像,关键点(前25个),输出图像,颜色设置,绘图标志)
#绘图标志:。图中红色圆圈的大小显示关键点的size属性,而半径线段的方向显示了关键点的方向属性angle。
cv2.drawKeypoints(img_color1, key_points1[:25], img_color1, color=(255, 0, 0),
flags=cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS)
pl.imshow(img_color1)
#调用SURF.compute()计算关键点列表key_points1对应的特征向量features1
_, features1 = surf.compute(img_gray1, key_points1)

如果关键点数很多,可以使用OpenCV提供的FlannBasedMatcher寻找匹配的特征向量。
"关键点数很多,可以使用OpenCV提供的FlannBasedMatcher寻找匹配的特征向量。"
import cv2
import numpy as np
import matplotlib.pyplot as pl
pl.rcParams["font.family"] = "SimHei"#直接修改配置字典,设置默认字体
"1.准备两幅图像"
img_gray1 = cv2.imread("E:/ruanjianDM/jupyternoerbookDM/picture/lena.jpg")
img_gray2 = cv2.imread("E:/ruanjianDM/jupyternoerbookDM/picture/lena1.jpg")
"2.直接计算关键点以及与之对应的特征向量"
key_points1, features1 = surf.detectAndCompute(img_gray1, None)
key_points2, features2 = surf.detectAndCompute(img_gray2, None)
"3.调用匹配算法"
FLANN_INDEX_KDTREE = 1
#创建FlannBasedMatcher对象时传递两个字典index_params和search_params,分别设置其索引参数和搜索参数。
index_params = dict(algorithm=FLANN_INDEX_KDTREE, trees=5)
search_params = dict(checks=100)
fbm = cv2.FlannBasedMatcher(index_params, search_params)
#调用knnMatch()对features1中的每个特征向量在features2中搜索k个最近的特征向量。
#这里设置参数k为1,只搜索最接近的特征向量。
match_list = fbm.knnMatch(features1, features2, k=2) #嵌套列表
matchesMask = [[0,0] for i in range(len(match_list))]
# ratio test as per Lowe's paper
for i,(m,n) in enumerate(match_list):
if m.distance < 0.8*n.distance:
matchesMask[i]=[1,0]
draw_params = dict(matchColor = (0,255,0), matchesMask = matchesMask, flags = 0)
img = cv2.drawMatchesKnn(img_gray1,key_points1,img_gray2,key_points2,match_list,None,**draw_params)
fig, axes = pl.subplots(1, 1, figsize=(15, 8))
axes.imshow(img[:,:,::-1])
