python爬取app数据
python环境部署
python环境部署这里不做叙述
MYSQL操作
安装MySQL驱动
由于MySQL服务器以独立的进程运行,并通过网络对外服务,所以,需要支持Python的MySQL驱动来连接到MySQL服务器。MySQL官方提供了mysql-connector-python驱动,但是安装的时候需要给pip命令加上参数–allow-external:
$ pip install mysql-connector-python --allow-external mysql-connector-python
如果上面的命令安装失败,可以试试另一个驱动:
$ pip install mysql-connector
我们演示如何连接到MySQL服务器的test数据库:
导入MySQL驱动:
import mysql.connector
注意把password设为你的root口令:
conn = mysql.connector.connect(user=‘root’, password=‘password’, database=‘test’)
cursor = conn.cursor()
创建user表:
cursor.execute(‘create table user (id varchar(20) primary key, name varchar(20))’)
插入一行记录,注意MySQL的占位符是%s:
cursor.execute(‘insert into user (id, name) values (%s, %s)’, [‘1’, ‘Michael’])
cursor.rowcount
1
提交事务:
conn.commit()
cursor.close()
运行查询:
cursor = conn.cursor()
cursor.execute(‘select * from user where id = %s’, (‘1’,))
values = cursor.fetchall()
values
[(‘1’, ‘Michael’)]
关闭Cursor和Connection:
cursor.close()
Trueconn.close()
由于Python的DB-API定义都是通用的,所以,操作MySQL的数据库代码和SQLite类似。
小结
执行INSERT等操作后要调用commit()提交事务;
MySQL的SQL占位符是%s。
cookie操作
序言
我们在使用爬虫的时候,经常会用到cookie进行模拟登陆和访问。在使用urllib库做爬虫,我们需要借助http.cookiejar库中的CookieJar来实现。
安装cookiejar库
一般http库已经包含了cookiejar,如果没有那么使用pip install --upgrade cookiejar即可
CookieJar类的子类:
CookieJar:管理HTTP cookie值、存储HTTP请求生成的cookie、向传出的HTTP请求添加cookie的对象。整个cookie都存储在内存中,对CookieJar实例进行垃圾回收后cookie也将丢失。
FileCookieJar:从CookieJar派生而来,用来创建FileCookieJar实例,检索cookie信息并将cookie存储到文件中。filename是存储cookie的文件名。delayload为True时支持延迟访问访问文件,即只有在需要时才读取文件或在文件中存储数据。
MozillaCookieJar:从FileCookieJar派生而来,创建与Mozilla浏览器 cookies.txt兼容的FileCookieJar实例。
LWPCookieJar:从FileCookieJar派生而来,创建与libwww-perl标准的 Set-Cookie3 文件格式兼容的FileCookieJar实例。
代码示例
获取cookie
# -*- coding: utf-8 -*-
from urllib import request
from http import cookiejar
class Cookie:
def get_ccokie(self, url='http://www.baidu.com'):
# 创建cookiejar实例对象
cookie = cookiejar.CookieJar()
print(cookie)
#创建管理器
cookie_handler = request.HTTPCookieProcessor(cookie)
http_handler = request.HTTPHandler()
https_handler = request.HTTPSHandler()
#创建请求管理器
opener = request.build_opener(cookie_handler,http_handler,https_handler)
#发起请求
url = url if url.strip() != '' else 'http://www.baidu.com'
req = request.Request(url)
response = opener.open(req)
# 查看请求结果
print(response.reason) # OK
print(cookie)
return cookie
# 保存cookie到文件
def save_cookie(self, url='http://www.baidu.com'):
# 创建cookiejar实例对象
cookie = cookiejar.MozillaCookieJar("cookie.txt")
print(cookie)
#
# 创建管理器
cookie_handler = request.HTTPCookieProcessor(cookie)
http_handler = request.HTTPHandler()
https_handler = request.HTTPSHandler()
# 创建请求求管理器
opener = request.build_opener(cookie_handler, http_handler, https_handler)
req = request.Request(url)
# 发起请求
response = opener.open(req)
# 查看请求结果
print(response.reason) # OK
cookie.save()
#从文件读取cookie
def load_cookie(self, url='http://www.baidu.com', file='cookie.txt'):
# 创建cookiejar实例对象
cookie = cookiejar.MozillaCookieJar()
cookie.load(file)
print(cookie)
# app抓取实例
环境
以有银子app为实例
所需扩展库
requests库(一种http扩展库)
教程参考: https://www.liaoxuefeng.com/wiki/1016959663602400/1183249464292448
pip install --upgrade requests
BeautifulSoup(html解析库,可能还需要安装lxml库)
教程参考:
https://www.crummy.com/software/BeautifulSoup/bs4/doc/index.zh.html#id15
安装
pip install --upgrade BeautifulSoup4
如果执行报错:
To get rid of this warning, pass the additional argument 'features="html5lib"' to the BeautifulSoup constructor
说明没有找到合适的解析器,可能是标准的html解析器无法使用,安装第三方的解析器 lxml .
pip install --upgrade lxml
xlwings (execl处理库)
pip install --upgrade xlwings
教程参考:
https://blog.csdn.net/asanscape/article/details/80372743
tips:
如果安装过程出现报错,根据错误提示进行调整,比如报错urllib3之类的错误,可能是urllib3库中某些东西影响了安装,可以先卸载urllib3,安装成功后,再安装urllib3
urllib3是使用requests库所依赖的,也需要安装的
各excel库对比

Pandas扩展库
安装:
pip install pandas
简介:
Pandas(Python Data Analysis Library)基于Numpy构建,让基于Numpy的应用更简单,被广泛应用于金融行业,流行的数据分析工具
将多个dict转成list的合集
import pandas as pd
data = [
{'A': 'A1','B': 'B2','C': 'C3','D': 'D4'},
{'A': 'AA1','C': 'CC3','D': 'DD4','E': 'EE5'},
{'A': 'AAA1','B': 'BBB2','C': 'CCC3','D': 'DDD4','E': 'EEE5'}
]
df = pd.DataFrame(data).fillna('null')
ls = df.values.tolist()
ls.insert(0, df.columns.tolist())
print(ls)
pillow图片处理库
PIL(Python Imaging Library)是Python一个强大方便的图像处理库,名气也比较大。不过只支持到Python 2.7。
PIL官方网站:http://www.pythonware.com/products/pil/
Pillow是PIL的一个派生分支,但如今已经发展成为比PIL本身更具活力的图像处理库。目前最新版本是3.0.0。
Pillow的Github主页:https://github.com/python-pillow/Pillow
Pillow的文档(对应版本v3.0.0):
https://pillow.readthedocs.org/en/latest/handbook/index.html
Pillow的文档中文翻译(对应版本v2.4.0):http://pillow-cn.readthedocs.org/en/latest/
Python 3.x 安装Pillow
给Python安装Pillow非常简单,使用pip或easy_install只要一行代码即可。
在命令行使用PIP安装:
pip install Pillow
或在命令行使用easy_install安装:
easy_install Pillow
安装完成后,使用from PIL import Image就引用使用库了。比如:
from PIL import Image
im = Image.open("bride.jpg")
im.rotate(45).show()
阿里云oss接口
一、OSS安装
1、安装python-devel
对于Windows和Mac OS X系统,由于安装Python的时候会将Python依赖的头文件一并安装,因此您无需安装python-devel。
对于CentOS、RHEL、Fedora系统,请执行以下命令安装python-devel:
yum install python-devel
对于Debian,Ubuntu系统,请执行以下命令安装python-devel:
apt-get install python-dev
2、pip安装oss2
使用pip安装即可,也可以参考下方官网安装:
pip install oss2
oss安装
安装成功可以执行以下命令检测安装结果:
>>> import oss2
>>> oss2.__version__
'2.5.0'
3、python卸载oss2
如果安装失败,建议通过pip卸载然后重装。卸载命令如下:
pip uninstall oss2
二、OSS的使用
1、创建存储空间
以下代码用于创建存储空间:
# -*- coding: utf-8 -*-
import oss2
auth = oss2.Auth('', '')
# Endpoint以杭州为例,其它Region请按实际情况填写。yourBucketName就是你要创建的Bucket
bucket = oss2.Bucket(auth, 'http://oss-cn-hangzhou.aliyuncs.com', '')
bucket.create_bucket(oss2.models.BUCKET_ACL_PRIVATE)
2、上传文件
以下代码用于上传文件至OSS:
# -*- coding: utf-8 -*-
import oss2
auth = oss2.Auth('', '')
# 如上描述
bucket = oss2.Bucket(auth, 'http://oss-cn-hangzhou.aliyuncs.com', '')
# 由本地文件路径加文件名包括后缀组成,例如/users/local/myfile.txt
bucket.put_object_from_file('', '')
yourLocalFile由本地文件路径加文件名包括后缀组成,例如/users/local/myfile.txt
yourObjectName是上传后的保存地址
tips(多种上传文件方式):
bucket.put_object(key, data, headers=None, progress_callback=None)
上传一个普通文件。
Bucket.put_object_from_file(key, filename, headers=None, progress_callback=None)
上传一个本地文件到OSS的普通文件。
Bucket.append_object(key, position, data, headers=None, progress_callback=None, init_crc=None)[source]
追加上传一个文件。
3、下载文件
以下代码用于将指定的OSS文件下载到本地文件:
# -*- coding: utf-8 -*-
import oss2
auth = oss2.Auth('', '')
bucket = oss2.Bucket(auth, 'http://oss-cn-hangzhou.aliyuncs.com', '')
# 由本地文件路径加文件名包括后缀组成,例如/users/local/myfile.txt
bucket.get_object_to_file('', '')
yourLocalFile是保存在本地哪个文件夹
yourObjectName是线上文件地址
4、列举文件即获取文件夹列表
以下代码用于列举指定存储空间下的10个文件:
# -*- coding: utf-8 -*-
import oss2
from itertools import islice
auth = oss2.Auth('', '')
bucket = oss2.Bucket(auth, 'http://oss-cn-hangzhou.aliyuncs.com', '')
# oss2.ObjectIteratorr用于遍历文件。
for b in islice(oss2.ObjectIterator(bucket), 10):
print(b.key)
5、删除文件
以下代码用于删除指定文件:
# -*- coding: utf-8 -*-
import oss2
auth = oss2.Auth('', '')
bucket = oss2.Bucket(auth, 'http://oss-cn-hangzhou.aliyuncs.com', '')
bucket.delete_object('')
app分析
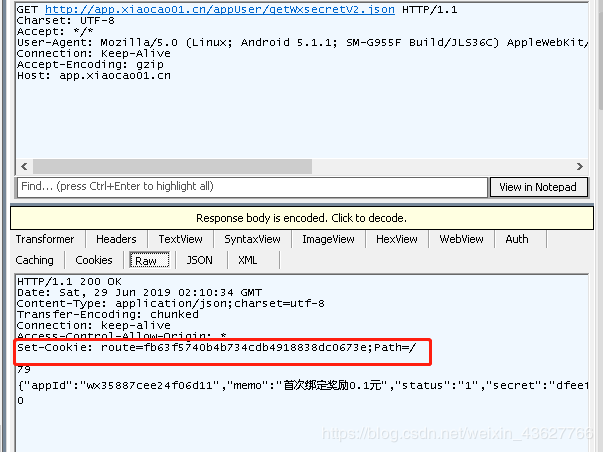
首先使用fildder抓包工具+夜神安卓模拟器对app进行接口分析
获取cookie的接口:
多线程加队列
思路
采用threading多线程+队列queue,首先把所有文章分类依次加入队列,也就是以单个分类为单位,目前使用dict保存分类单位。
import threading #多线程
import queue # 队列
步骤
1、请求到所有分类,加入队列,循环完毕后开启多线程
for cat in cats_json:
# 合并请求参数(该方法要求python3.5+)
params = {**self.params, **self.cat_params}
params[self.map['cat_param']] = cat[self.map['cat_id']]
#添加到队列
self.addQueue(self.list_url, params, cat)
# 启动多线程
self.handleWorkers(len(cats_json))
2、多线程开启,每个线程依次从队列中获取任务并进行处理
# 多线程处理
def handleWorkers(self, threadNum=1):
# threadNum 可以调节线程数, 进而控制抓取速度
#threadNum = 1
# 当前时间
startTime = time.time()
# 线程列表
threads = []
for i in range(0, threadNum):
# 创建一个线程
t = threading.Thread(target=self.fetchUrl, args=(self.urlQueue,))
threads.append(t)
for t in threads:
# 设置守护进程
t.setDaemon(True)
# 启动进程
t.start()
for t in threads:
# 多线程多join的情况下,依次执行各线程的join方法, 这样可以确保主线程最后退出, 且各个线程间没有阻塞
t.join()
endTime = time.time()
print('主线程结束, Time cost: %s ' % (endTime - startTime))
3、具体的业务逻辑处理,值得注意的是线程锁的应用(threading.Lock() )
多线程再完成一些共享资源的读写操作的时候往往会出现文件被锁定,数据错乱的问题,那么这时候需要使用threading.Lock() 来保证依次执行这些共享操作,比如文件的操作,使用锁可以避免多个线程同时使用该文件。
具体用法有两种
一种:
lock = threading.Lock()
lock.acquire()
# 文件等操作
lock.release
一种
lock = threading.Lock()
with lock;
# 文件等操作
pass(pass可加可不加)
一般会使用在循环中,确保循环中每次操作都是独立的,避免造成数据混乱
附录
html转义和反转义
在爬网页的时候,有时候会返回一些转义的字符,比如,在抓取某个网站的时候,返回的内容是直接通过js输出到页面的,也就是说我们获取到的是通过js转义后的字符串,并且存在于script标签中
document.writeln(unescape("%3Cp%20style%3D%22font-size%3A%
这种形式无法直接获取数据,首先需要使用正则匹配中被转义的字符串,也就是unescape后面的字符串,最后还需要进行转义,转义的方法如下
用 Python 来处理转义字符串有多种方式,而且 py2 和 py3 中处理方式不一样,在 python2 中,反转义串的模块是 HTMLParser。
python2
import HTMLParser
HTMLParser().unescape(‘a=1&b=2’)
‘a=1&b=2’
Python3 把 HTMLParser 模块迁移到 html.parser
python3
from html.parser import HTMLParser
HTMLParser().unescape(‘a=1&b=2’)
‘a=1&b=2’
到 python3.4 之后的版本,在 html 模块新增了 unescape 方法。
python3.4
import html
html.unescape(‘a=1&b=2’)
‘a=1&b=2’
推荐最后一种写法,因为 HTMLParser.unescape 方法在 Python3.4 就已经被废弃掉不推荐使用,意味着之后的版本有可能会被彻底移除。
另外,sax 模块也有支持反转义的函数
from xml.sax.saxutils import unescape
unescape(‘a=1&b=2’)
‘a=1&b=2’
以上的解码操作主要是处理html转义字符,也就是html对&,<>等符号的转义后的反转义处理
使用以上方法解码js中escape编码处理过的字符串,发现都达不到效果,也就是没有生效,
于是根据代码中存在%3C等编码字符,所以使用urldecode方式进行解码,具体如下:
from urllib import parse
url_data = parse.unquote(str) //解码以后会把特殊的符号<,/&等还原,最后得到
%u8bf4%u5230%u5c0f%u6c88%u9633%uff0c%u4ed6%u6700%u8fd1%u51e0%u5e74
此时发现虽然标签还原了,但是标签的内容还是编码字符,观察编码发现所有的都是由%u和四位数字+字母组成,其实这就是js escape编码,每个汉字都是“%u”符号加4位字符编码
所以通过分析,我们发现js中escape编码是%u,而python3使用urillib进行编码是%u变为%5Cu
因此只需要在输出时,再进行一次替换即可
python 编码
#编码
import urllib
print(urllib.parse.quote('你好哈'.encode('unicode-escape')).replace('%5Cu', '%u'))
%u4f60%u597d%u54c8%3Cas%3E
python 解码
escape则不是将%u替换为%5Cu来处理,而是%u替换为\u,进行处理,相当于json字段处理过程
#escape 解码
import urllib
st ="%u4F60%u597D%3Cas%3E".replace('%u', '\\u')
print(st)
k =urllib.parse.unquote(st.encode().decode('unicode-escape'))
# 这里的unqoute方法主要是解码一些特殊字符的编码,比如<,/>等等,一般是html标签
print(k)
\u4F60\u597D%3Cas%3E
你好
或者可以使用json库来解码
import json
s ="%u4F60%u597D%3Cas%3E"
jsonObj = '"' + "".join([(i and "\\" + i) for i in s.split('%')]) + '"'
print(json.loads(jsonObj))
你好
注意:这里的unquote方法可以解码%3Cp%20这种编码,类似于php的urlencode编码。st.encode().decode(‘unicode-escape’)这里是对经过js的escape编码后的字符串进行%u替换为\u后的字符进行解码成中文的处理
通过这两步处理,就可以处理经过js escape编码后的字符,核心在于将%u替换\u的步骤,否则将无法解码成功
BUG总结
保存webp格式图片报错
报错内容:OSError(‘cannot write mode RGBA as JPEG’)
原因 使用PIL(python3安装Pillow库,python2安装PIL库)的image的对象处理图片时保存为RGB类型的jpg格式
解析 需要丢弃Alpha频道或保存为支持透明度的东西 - 比如PNG。
该image-class有一个方法convert可以用来转换RGBA到RBG-之后,你就可以使用JPG。
im = Image.open("audacious.png")
rgb_im = im.convert('RGB')
rgb_im.save('audacious.jpg')
或者保存支持透明度的png也可以
rgb_im.save('audacious.jpg','PNG')