大数据采集架构
概述

一般来说,当在Hadoop集群上,有足够数据处理的时候,通常会有很多生产数据的服务器。这些服务器的数量上百甚至成千上万。小的数据还可以直接从应用程序写入HDFS,但庞大数量的服务器试着将海量数据直接写入HDFS或者HBase集群,会因为多种原因导致重大问题。
所以这个中间系统(数据采集系统)就是将应用程序发送过来的信息转发到分布式的后台服务器集群上,
ChuKwa
ChuKwa是一个开源的用于监控大部分分布式系统的数据采集系统,它是构建在Hadoop的HDFS和Map/Reduce框架之上的,继承了Hadoop的可伸缩性和鲁棒性。
但此项目已不活跃。
Flume
Flume是Cloudera提供一个高可用的、高可靠的、分布式的海量日志采集、聚合和传输的系统。Flume支持在日志系统中定制各类数据发送方,用于数据收集;同时,Flume提供对数据进行简单处理,并写到各种数据接收方的能力。

数据发生器产生的数据被单个运行Flume所在服务器上的Agent所收集,然后数据收容器从各个agent上汇集数据并将采集到的数据存入到HDFS或者HBase中。
在整个数据传输的过程中,流动的是事件(Event)。事件是Flume内部数据传输的最基本单元。它是由一个可选头部和一个负载数据的字节数组(该数据组是从数据源接入点传入,并传输给传输器(HDFS/HBase))构成。
Flume系统首先将event进行封装,然后利用agent进行其解析,并依据规则传输给HBase或HDFS。
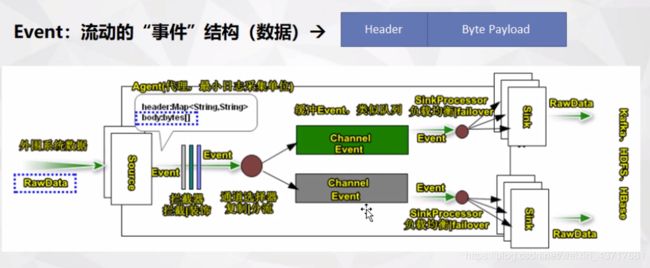



扇入就是Source可以接受多个输入,扇出就是Sink可以将数据输出多个目的地。
Flume实际上是一个分布式的管道架构,可以看做在数据源和目的地之间有一个agent的网络,并支持数据路由
数据路由
Flume Agent包括Source、Channel、Sink组成。
Source
Source负责接收数据,并将接受的数据以Flume的event格式进行封装,然后将其传递到一个或者多个通道(channel)。
Source是可以进行配置的

memory:内存
avro:对象序列化的一种技术,
port:端口是7877.例:服务器是一栋房子,这栋房子有很多窗户,端口就可以看作为窗户
Channel
Channel只是一个暂时的存储容器,它将从Source出接收到的event格式的数据缓存起来,在Source和Sink之间起着一个桥梁的作用。Channel是一个完整的事务,这一点保证了在收发时的一致性,并且它可以和任意数量的Source和Sink链接。
Memory Channel:写入内存。非持久化存储,断电、宕机丢失信息
File Channel:写入文件


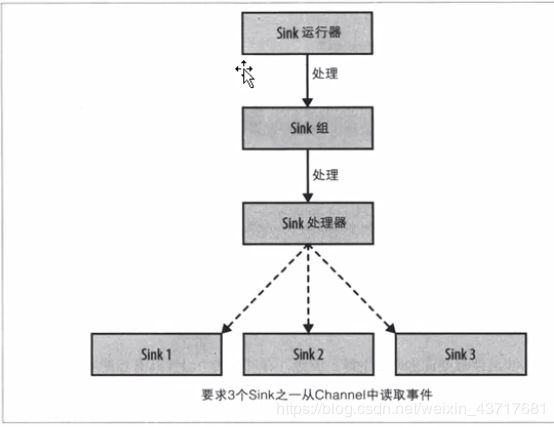
Sink
Sink负责从管道中读出数据并发给下一个Agent或者最终目的地。

运行机制
Flume的核心是Agent,Agent对外有两个进行交互的地方,一个是接受数据输入的Source,一个是数据输出Sink。Source将接收到的数据发送给Channel,Channel作为一个数据缓冲区会暂时存放这些数据,随后Sink会将Channel中的数据发送给指定的地方,例如:HDFS。只有在Sink将Channel中的数据成功发送出去之后,Channel才将临时存放的数据进行删除,这保证了数据传输的可靠性和安全性。
Flume还支持多级Flume的Agent。例如:Sink可以将数据写到下一个Agent的Source中
为保证Flume的可靠性,Flume在Source和Channel之间采用Interceptors拦截器用来更改或者检查Flume的events数据。在多Channel情况下,Flume可以采用默认管道选择器(即,每一个管道传递的都是相同的events)或者多路复用通道选择器(依据每一个event的头部header的地址选择通道)实现Channel的选择。
为了保证负载均衡,采用Sink线程用于激活被被选择的Sinks群中特定的sink
Scribe
Scribe是Facebook开发的分布式日志系统,它能够从各种日志源上收集日志,存储到一个中央存储系统上,以便于进行集中统计分析处理。它为日志的“分布式收集,统一处理”提供了一个可扩展的,高容错的方案。
例如:当后端的存储系统崩溃时,Scribe会将数据写到本地磁盘上,当存储系统恢复正常后,Scribe将日志重新加载到存储系统中。
Scribe由Scribe Agent、Scribe和存储系统三部分组成。
Scribe Agent实际上是一个ThriftClient。各个数据源需要通过Thrift向Scribe传输数据,每条数据记录包含一个Category和一个Message,可以在Scribe配置中指定Thrift线程数,默认是3。
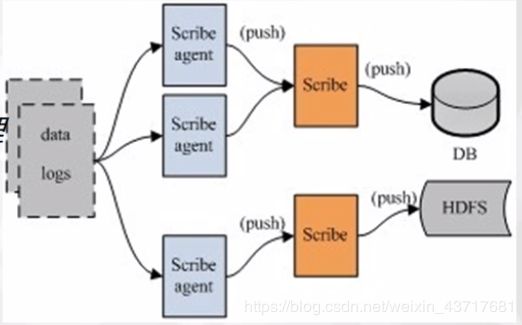
Scribe Agent:a Thrift Client(客户端)
Scribe:共享队列,以目录形式
存储系统:采集信息的存储
Thrift-远程过程调用框架
Thrift入门
在本地运行程序,在远端的服务器上有所感知(在客户端写代码,在服务器端执行对应代码)
Kafka
Kafka是一种分布式发布-订阅系统。构建实时数据管道和数据流应用程序,
Kafka是一个作家的名字。
Kafka类比于一个电商平台,所有信息都汇集于此
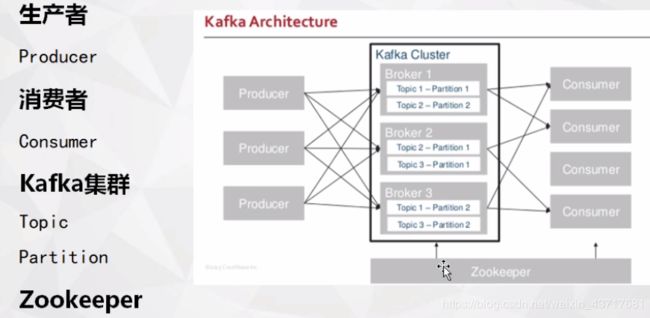
kafka集群负责收生产者的数据,同时可能会将这些信息进行分类,分门别类管理信息。例如:topic2在broker1有,在broker2也有,当topic2都在broker的时候,海量数据过来时,系统的性能瓶颈就挺严重的。多个broker相当于我们将数据进行分布式处理,我们一个主题分布在不同的broker上边,当数据过来时我们根据实际情况进行负载均衡,来实现系统均衡。而且我们根据实际情况在cluster里边随机加入broker进行扩充。
为避免有的broker旱的旱死,涝的涝死。Zookeeper就是一种进行协调的分布式节点的框架,提供一种机制来观察分布式节点工作的情况,从而实现比较好的负载均衡。
Producer
向kafka的主题(topic)提供数据。Producer决定向哪些主题发布?推送到哪些分区?以什么方式进行推送?
Topics
数据源可以使用Kafka按主题发布信息给订阅者
Topics是消息的分类名。Kafka集群或Broker为每一个主题都会维护一个分区日志。每一个分区日志是有序的消息序列,并且消息是连续追加到分区日志上,且消息不可更改。分区中每条消息都会被分配顺序ID号,也被成为偏移量,它是在该分区中的唯一标识。Kafka集群保留了所有发布的消息,直至消息过期(只有过期的数据才会被自动清除以释放磁盘空间)
一个主题可以有多个分区,这些分区可以作为并行处理单元,这样能使kafka有能力且有效的处理海量数据,这些分区日志会被分配到kafka集群中的多个服务器上进行处理,每个分区也会备份到kafka集群的多个服务器上。
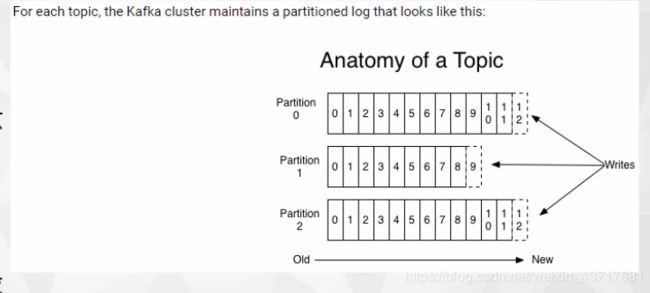
Topics消息会被均匀的分布到Partition()0、Partition1、Partition2分区日志中,每个Partition中的消息都是有序的,生产的消息被不断追加到PartitionLog上,其中的每一个消息都被赋予了一个唯一的偏移值(offset)
Kafka为每个分区分配一台服务器作为leader,用于处理所有分区的读和写请求。且为每个分区分配另个或多个服务器作为follower。Follower服务器对leader服务器中的分区进行备份,一旦leader服务器宕机,其他的某个Follower服务器会被选为Leader。
Consumers
Kafka提供一种单独的消费者抽象,此抽象具有两种模式的特征消费组,Queuing和Publish-SubScribe。消费者使用相同的消费组名字来标识。Kafka支持以组的形式消费Topic,也可以各成一个。
Push和Pull机制
Producer到Broker的过程是Push(有数据送到Broker);而Consumer到Broker的过程是Pull。它通过Consumer主动获取数据,而不是Broker把数据主动发送到Consumer端的。
这种Push-and-Pull消息传输机制,这种机制,让Consumer可以自主决定是否批量的从Broker接收数据。
Zookeeper
作为一种分布式服务框架,提供协调和同步分布式系统各节点的资源配置等服务,是分布式系统一致性服务的软件。Kafka主要是利用Zookeeper解决分布式应用中遇到的数据管理问题,如名称服务、集群管理、分布式应用配置项的管理等。
多个Broker协同合作、Producer和Consumer部署在各个业务逻辑中被调用都是通过Zookeeper管理协调请求和转发。
通过Zookeeper管理实现了高性能的分布式消息发布订阅系统。
Kafka架构核心特性
1)压缩功能
Kafka支持对消息进行压缩,在Producer端进行压缩之后,在Consumer端须进行解压。
进行压缩减少传输的数据量,减轻对网络传输的压力
为了区分消息是否进行压缩,Kafka在消息头部添加了一个描述压缩属性字节,这个字节的后两位表示消息的压缩采用的编码,如果后两位为0,则表示消息未被压缩。
2)消息可靠性
为保证消息传输成功,当一个消息被发送后,Producer会等待Broker成功接收到消息的反馈(可设置参数控制等待时间),如果消息在途中丢失或是其中一个Broker挂掉,Producer会重新发送;Broker记录了Partition中的一个offset值,这个值指向Consumer下一个即将消费Message。当Consumer收到了消息,但却在处理过程中挂掉,此时Consumer可以通过这个Offset值重新找到上一个消息再进行处理。
3)备份机制
一个备份数量为n的集群允许有n-1个节点失败。在所有备份节点中,有一个节点作为Lead节点,这个节点保存了其他备份节点列表,并维持各个备份间的状态同步。
Kafka的核心特征保证了其能保持高可靠性、容错性、可扩展性以及并发性的处理消息。
实例

ELK
ELk
ELK-概念
Logstash:日志收集
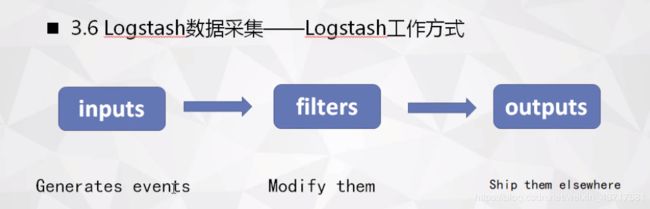
Inputs
(各种数据、各种规模、是一个插件式架构)
采集日志时将日志文件作为Logstash的input,还可以采集Redis(缓存数据库)中的数据,采集beats过来的数据
Filter
- 对收集的数据进行grok切分
- 对收集的数据进行mutate操作(rename、update、replace、split)
- 对收集的操作进行drop操作(删除满足条件的日志)
- 对收集的数据进行clone操作(克隆后增加、克隆后删除)
- 对收集的数据进行geoip操作(参照的IP地址库,添加IP地址对应的经纬度)
Output
output为ElasticSearch(例如:采集的数据输出到es,按天进行索引),也可以直接输出到图标后台(进行可视化,供上层人员进行决策)
ES(Elasticsearch):日志存储,索引
ElasticSearch是一个分布式、高扩展、高实时的搜索和数据分析引擎。它能很方便的使大量数据具有搜索、分析和探索的能力。充分利用ElasticSearch的水平伸缩性,能使数据在生产环境中变得更有价值。
Kibana:可视化(展示)和分析
