MySql学习系列(一)
学习内容
1、软件安装及服务器设置。
2、使用图形界面软件 Navicat for SQL
简易步骤:
解压缩文件,复制key
打开文件夹中的navicat.exe
用户名随意,输入key,然后连接数据库
输入密码,连接名改成自己喜欢的
剩下的自己探索,怎么在navicat中创建数据库、表等等
3、数据库基础知识 数据库定义 关系型数据库 二维表 行 列 主键 外键
4、MySQL数据库管理系统 数据库 数据表 视图 存储过程
1.1MySQL 软件安装及数据库基础
1.软件安装及服务器设置。
教程 http://www.runoob.com/mysql/mysql-install.html
登录 MySQL:
当 MySQL 服务已经运行时, 我们可以通过 MySQL 自带的客户端工具登录到 MySQL 数据库中, 首先打开命令提示符, 输入以下格式的命名:
mysql -h 主机名 -u 用户名 -p
参数说明:
-h : 指定客户端所要登录的 MySQL 主机名, 登录本机(localhost 或 127.0.0.1)该参数可以省略;
-u : 登录的用户名;
-p : 告诉服务器将会使用一个密码来登录, 如果所要登录的用户名密码为空, 可以忽略此选项。
如果我们要登录本机的 MySQL 数据库,只需要输入以下命令即可:
mysql -u root -p
按回车确认, 如果安装正确且 MySQL 正在运行, 会得到以下响应:
Enter password:
若密码存在, 输入密码登录, 不存在则直接按回车登录。登录成功后你将会看到 Welcome to the MySQL monitor… 的提示语。
然后命令提示符会一直以 mysq> 加一个闪烁的光标等待命令的输入, 输入 exit 或 quit 退出登录。
2.使用图形界面软件 Navicat for SQL
群里提供破解版Navicat for SQL,看群公告或聊天记录搜索888查找。
简易步骤: 1、解压缩文件,复制key 2、打开文件夹中的navicat.e 3、用户名随意,输入key,然后连接数据库 4、输入密码,连接名改成自己喜欢的
3.数据库基础知识 数据库定义 关系型数据库 二维表 行 列 主键 外键
3.1 数据库(database)
保存有组织的数据的容器(通常是一个文件或一组文件)。
3.2 表(table)
某种特定类型数据的结构化清单。
1、表是一种结构化的文件,可用来存储某种特定类型的数据。表可以保存顾客清单、 产品目录,或者其他信息清单。
这里的关键一点在于,存储在表中的数据是同一种类型的数据或清单。
2、数据库中的每个表都有一个名字来标识自己。 这个名字是唯一的,即数据库中没有其他表具有相同的名字。
3、表由列组成。列存储表中某部分的信息。
3.3 列(column)
表中的一个字段。所有表都是由一个或多个列组成的。
4、数据库中每个列都有相应的数据类型。数据类型(datatype)定义了列可以存储哪些数据种类。
3.4 行(row)
表中的一个记录。表中的数据是按行存储的,所保存的每个记录存储在自己的行内。如果将表想象为网格,网格中垂直的列为表列,水平行为表行。
3.2主键 外键
1、表中每一行都应该有一列(或几列)可以唯一标识自己。 顾客表可以使用顾客编号,而订单表可以使用订单 ID。雇员表可以使用雇员 ID或雇员社会安全号。
主键(primary key)
一列(或一组列),其值能够唯一标识表中每一行。唯一标识表中每行的这个列(或这几列)称为主键。主键用来表示一个特定的行。没有主键,更新或删除表中特定行就极为困难,因为你不能保证操作只涉及相关的行
2、表中的任何列都可以作为主键,只要它满足以下条件:
任意两行都不具有相同的主键值;
每一行都必须具有一个主键值(主键列不允许 NULL值);
主键列中的值不允许修改或更新;
主键值不能重用(如果某行从表中删除,它的主键不能赋给以后的新行)。
主键通常定义在表的一列上,但并不是必需这么做,也可以一起使用多个列作为主键。在使用多列作为主键时,上述条件必须应用到所有列,所有列值的组合必须是唯一的(但单个列的值可以不唯一)。
3、外键
一张表的列同时存在于表1和表2中,它不是表1的主键,是表2的主键,则为表2的外键。
外键用于关联两个表。
4.MySQL数据库管理系统 数据库 数据表 视图 存储过程
1、所谓的关系型数据库,是建立在关系模型基础上的数据库,借助于集合代数等数学概念和方法来处理数据库中的数据。
RDBMS 即关系数据库管理系统(Relational Database Management System)的特点:
1.数据以表格的形式出现
2.每行为各种记录名称
3.每列为记录名称所对应的数据域
4.许多的行和列组成一张表单
5.若干的表单组成database
2、数据库:数据库是一些关联表的集合。数据库是一个以某种有组织的方式存储的数据集合。
3、数据表:表是关系型数据库的基本存储结构。
4、视图:视图就是一条SELECT语句执行后返回的结果集。所以我们在创建视图的时候,主要的工作就落在创建这条SQL查询语句上。
视图为虚拟的表。它们包含的不是数据而是根据需要检索数据的查询。视图提供了一种封装 SELECT语句的层次,可用来简化数据处理,重新格式化或保护基础数据。
5、存储:创建存储过程,为以后使用而保存一条或多条SQL语句。简单来说,存储过程就是为以后使用而保存的一条或多条 SQL语句。可将其视为批文件, 虽然它们的作用不仅限于批处理。
1.2 MySQL 基础 (一)- 查询语句
#学习内容#
1、导入示例数据库,
教程 https://www.yiibai.com/mysql/how-to-load-sample-database-into-mysql-database-server.html
将下载的文件解压缩到临时文件夹中。为了简单起见,我们将把它解压缩到D:\worksp,如下所示 -
D:\software\bin>mysql -hlocalhost -uroot -p
创建数据库 -
mysql> CREATE DATABASE IF NOT EXISTS yiibaidb DEFAULT CHARSET utf8 COLLATE utf8_general_ci;
导入数据 -
mysql> use yiibaidb; --选择一个数据库
mysql> source D:/worksp/yiibaidb.sql;
测试导入结果
mysql> select city,phone,country from `offices`;
2、SQL是什么?MySQL是什么?
SQL(发音为字母 S-Q-L或 sequel)是 Structured Query Language(结构化查询语言)的缩写。 SQL是一种专门用来与数据库沟通的语言。
MySQL是一个关系型数据库管理系统。
数据库软件应称为数据库管理系统(DBMS)。数据库是通过 DBMS创建和操纵的容器,而具体它究竟是什么,形式如何,各种数据库都不一样。
3、查询语句 SELECT FROM
语句解释 去重语句 前N个语句 CASE…END判断语句
3.1 检索单个列
SELECT prod_name
FROM Products;
上述语句利用 SELECT语句从 Products表中检索一个名为 prod_name的列。所需的列名写在SELECT关键字之后, FROM关键字指出从哪个表中检索数据。
如上的一条简单 SELECT语句。数据没有过滤(过滤将得出结果集的一个子集),也没有排序。以后几课将讨论这些内容。
多条 SQL语句必须以分号(;)分隔。
SQL语句不区分大小写,因此SELECT与select是相同的。在处理 SQL语句时,其中所有空格都被忽略。 许多 SQL开发人员喜欢对 SQL关键字使用大写,而对列名和表名使用小写, 这样做使代码更易于阅读和调试。
3.2 检索多个列
唯一的不同是必须在SELECT关键字后给出多个列名,列名之间必须以逗号分隔,最后一个列名后不加。
SELECT prod_id, prod_name, prod_price
FROM Products;
3.3 检索所有列
SELECT *
FROM Products;
3.4 检索不同的值
办法就是使用 DISTINCT关键字, 顾名思义,它指示数据库只返回不同的值。
SELECT DISTINCT vend_id
FROM Products;
3.5 限制结果
在 SQL Server和 Access中使用SELECT时,可以使用TOP关键字来限制
最多返回多少行,如下所示:
SELECT TOP 5 prod_name
FROM Products;
上面代码使用SELECT TOP 5语句,只检索前 5行数据。
如果你使用 MySQL、 MariaDB、 PostgreSQL或者 SQLite,需要使用LIMIT
子句,像这样:
SELECT prod_name
FROM Products
LIMIT 5;
为了得到后面的 5行数据,需要指定从哪儿开始以及检索的行数,像这样:
SELECT prod_name FROM Products LIMIT 5 OFFSET 5;
LIMIT 5 OFFSET 5指示 MySQL等 DBMS返回从第 5行起的 5行数据,所以, LIMIT指定返回的行数, LIMIT带的 OFFSET指定从哪儿开始。
MySQL和MariaDB支持简化版的LIMIT4OFFSET3语句,即LIMIT3,4。
3.6 使用注释
1、
SELECT prod_name -- 这是一条注释
FROM Products;
注释使用–(两个连字符)嵌在行内。 --之后的文本就是注释。
2、
# 这是一条注释
SELECT prod_name
FROM Products;
在一行的开始处使用#, 这一整行都将作为注释。
3、你也可以进行多行注释,注释可以在脚本的任何位置停止和开始。
/* SELECT prod_name, vend_id
FROM Products; */
SELECT prod_name
FROM Products;
注释从/开始,到/结束, /和/之间的任何内容都是注释。
4、筛选语句 WHERE
语句解释 运算符/通配符/操作符
4.1 使用WHERE子句
在SELECT语句中,数据根据WHERE子句中指定的搜索条件进行过滤。WHERE子句在表名(FROM子句)之后给出,如下所示:
SELECT prod_name, prod_price
FROM Products
WHERE prod_price = 3.49;
这条语句从 products表中检索两个列,但不返回所有行,只返回prod_price值为3.49的行。
注意:WHERE 子句的位置
在同时使用 ORDER BY和 WHERE子句时, 应该让 ORDER BY位于WHERE之后,否则将会产生错误。
4.2 WHERE子句操作符
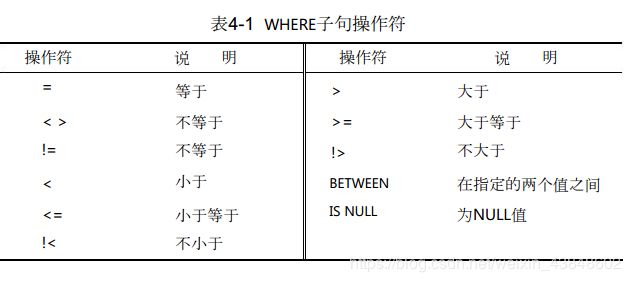
4.2.1 检查单个值
SELECT prod_name, prod_price
FROM Products
WHERE prod_price < 10;
4.2.2 不匹配检查
SELECT vend_id, prod_name
FROM Products
WHERE vend_id <> 'DLL01';
4.2.3 范围值检查
SELECT prod_name, prod_price
FROM Products
WHERE prod_price BETWEEN 5 AND 10;
4.2.4 空值检查
NULL
无值(no value),它与字段包含 0、空字符串或仅仅包含空格不同。
确定值是否为NULL,不能简单地检查是否= NULL。 SELECT语句有一个特殊的WHERE子句,可用来检查具有NULL值的列。 这个WHERE子句就是IS NULL子句。其语法如下:
SELECT prod_name
FROM Products
WHERE prod_price IS NULL;
5、分组语句 GROUP BY
聚集函数 语句解释 HAVING子句
6、排序语句 ORDER BY
语句解释 正序、逆序
6.1
为了明确地排序用SELECT语句检索出的数据,可使用ORDER BY子句。ORDERBY子句取一个或多个列的名字,据此对输出进行排序。 请看下面的例子:
SELECT prod_name
FROM Products
ORDER BY prod_name;
除了指示 DBMS软件对prod_name列以字母顺序排序数据的ORDER BY子句外, 这条语句与前面的语句相同。
注意:ORDER BY 子句的位置
在指定一条 ORDER BY子句时, 应该保证它是 SELECT语句中最后一条子句。如果它不是最后的子句,将会出现错误消息。
6.2 按多个列排序
SELECT prod_id, prod_price, prod_name
FROM Products
ORDER BY prod_price, prod_name;
6.3 按列位置排序
SELECT prod_id, prod_price, prod_name
FROM Products
ORDER BY 2, 3;
ORDER BY 2,3表示先按prod_price,再按prod_name进行排序。
6.4 指定排序方向
数据排序不限于升序排序(从 A到 Z), 这只是默认的排序顺序。 还可以使用ORDER BY子句进行降序(从 Z到 A)排序。 为了进行降序排序,必须指定DESC关键字。
SELECT prod_id, prod_price, prod_name
FROM Products
ORDER BY prod_price DESC;
如果想在多个列上进行降序排序,必须对每一列指定DESC关键字。
请注意, DESC是DESCENDING的缩写, 这两个关键字都可以使用。与DESC相对的是ASC(或ASCENDING),在升序排序时可以指定它。但实际上,ASC没有多大用处,因为升序是默认的(如果既不指定 ASC也不指定DESC, 则假定为ASC)。
提示:区分大小写和排序顺序
在对文本性数据进行排序时, A与a相同吗?a位于B之前, 还是Z之后?这些问题不是理论问题,其答案取决于数据库的设置方式。
在字典(dictionary)排序顺序中, A被视为与a相同, 这是大多数数据库管理系统的默认行为。但是, 许多 DBMS允许数据库管理员在需要时改变这种行为(如果你的数据库包含大量外语字符,可能必须这样做)。
这里的关键问题是,如果确实需要改变这种排序顺序,用简单的ORDER
BY子句可能做不到。你必须请求数据库管理员的帮助。
7、函数
时间函数 数值函数 字符串函数
8、SQL注释
9、SQL代码规范
[SQL编程格式的优化建议] https://zhuanlan.zhihu.com/p/27466166 [SQL Style Guide] https://www.sqlstyle.guide/
作业:
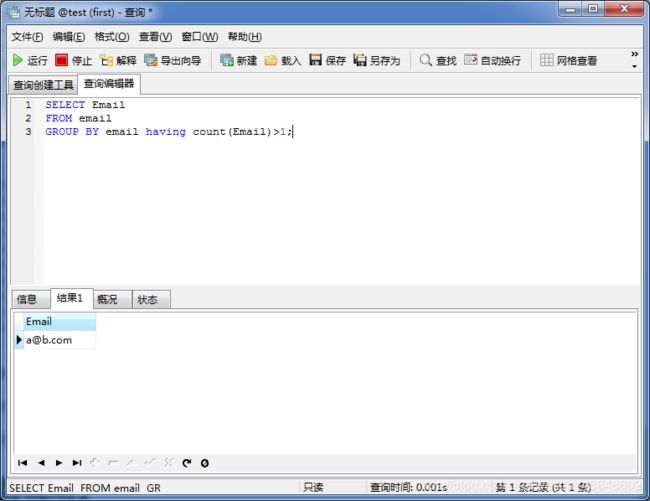
项目一:查找重复的电子邮箱(难度:简单)
1、创建表 代码:
CREATE TABLE email (
ID INT NOT NULL PRIMARY KEY,
Email VARCHAR(255)
);
选择navicat的命令界面,

回车就建立好了,需要刷新一下,就出来名字为email的表格了。
2、-- 插入数据
INSERT INTO email VALUES('1','[email protected]');
INSERT INTO email VALUES('2','[email protected]');
INSERT INTO email VALUES('3','[email protected]');

3、编写一个 SQL 查询,查找 Email 表中所有重复的电子邮箱。
SELECT Email
FROM email
GROUP BY email having count(Email)>1;
注意:count()不可以留下空格。
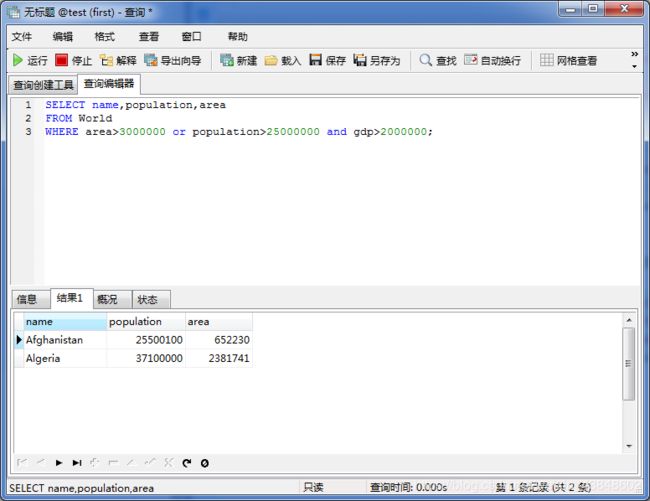
项目二:查找大国(难度:简单)
项目二 – 创建表
1、创建表 代码:
CREATE TABLE World (
name VARCHAR(50) NOT NULL,
continent VARCHAR(50) NOT NULL,
area INT NOT NULL,
population INT NOT NULL,
gdp INT NOT NULL
);
2、插入表格
INSERT INTO World
VALUES('Afghanistan','Asia',652230,25500100,20343000);
INSERT INTO World
VALUES('Albania','Europe',28748,2831741,12960000);
INSERT INTO World
VALUES('Algeria','Africa',2381741,37100000,188681000);
INSERT INTO World
VALUES('Andorra','Europe',468,78115,3712000);
INSERT INTO World
VALUES('Angola','Africa',1246700,20609294,100990000);
3、编写一个SQL查询,输出表中所有大国家的名称、人口和面积。
SELECT name,population,area
FROM World
WHERE area>3000000 or population>25000000 and gdp>2000000;