OpenCV Python开发 第一章 图像处理基础
OpenCV Python开发 第一章 图像处理基础
- 不同的色彩空间
- Gray灰度图
- BGR图
- HSV图
- 色调H
- 饱和度S
- 明度V
- 傅里叶变换
- 高通滤波和低通滤波
- 自定义卷积
- 为什么卷积核最好是方阵?
- 为什么卷积核的维数是奇数?
- 为什么卷积核的所有元素和为 0 0 0?
- OpenCV中的卷积
- 边缘与轮廓
- 边缘检测与Canny算法
- 熟悉轮廓检测
- 边界框、最小矩形区域和最小闭圆轮廓
- 图轮廓与Douglas-Peucker算法
- 形状检测
- 直线检测
- 圆检测
- 章节总结
- 本章所有API
- 本章完整代码
不同的色彩空间
色彩是人的眼睛对于不同频率的光线的不同感受, 色彩既是客观存在的(不同频率的光)又是主观感知的, 有认识差异. “色彩空间”一词源于西方的“Color Space”, 又称作“色域”, 色彩学中, 人们建立了多种色彩模型,以一维、二维、三维甚至四维空间坐标来表示某一色彩,这种坐标系统所能定义的色彩范围即色彩空间. 我们经常用到的色彩空间主要有RGB, CMYK, Lab, HSV等.
OpenCV中主要有Gray, BGR, 以及HSV三种色彩空间
通常来说, 一副长宽为n, m的图片, 是由n*m个像素点组成的, 在单通道图像(如灰度图)中, 每一个像素的值为0~255之间的一个整数, 而在多通道图像中, 比如BGR图像, 每一个像素都是一个1*3的行向量, 像素pixel=[B, G, R], 其中B,G,R每个值都是0~255的一个整数, 分别代表了其B(蓝), G(绿), R(红)的程度. 三个值叠加起来就成了我们可以看到的颜色.
Gray灰度图
灰度图是通过去除彩色信息来将其转换成灰度图, 灰度图对中间处理过程特别有效, 大量应用在目标检测、跟踪算法.
以3通道图像为例, 转换成灰度图image_gray最简单的算法就是对原图像image_original的每个像素的3个通道值进行简单的算术平均平均.
i m a g e _ g r a y [ i ] [ j ] = ∑ k = 0 2 i m a g e _ o r i g i n a l [ i ] [ j ] [ k ] / 3 image\_gray[i][j] = \sum_{k=0}^{2}image\_original[i][j][k]/3 image_gray[i][j]=k=0∑2image_original[i][j][k]/3
而OpenCV中内置了各种图像之间的转换函数cvtColor
cvtColor(src, code, dst=None, dstCn=None)
后面两个可选参数一般不去赋值, 主要是前面两个参数. src是被转换的图像, code是转换方式, 具体如下表(由于code的可选值实在太多, 这里只简单列举几个)
| code | 意义 |
|---|---|
| cv.COLOR_BGR2GRAY | src是BGR图, 将src转换成灰度图并返回 |
| cv.COLOR_BGR2RGB | src是BGR图, 将src转换成RGB图并返回 |
| cv.COLOR_BGR2HSV | src是BGR图, 将src转换成HSV图并返回 |
Python实现的代码如下:
def myBGR2GRAY(img_orig):
"""
将BGR图img转换成灰度图并显示
:param img_orig:
"""
length = img_orig.shape[0]
width = img_orig.shape[1]
img_gray = np.zeros((length, width))
for i in range(length):
for j in range(width):
img_gray[i][j] = np.uint8(sum(img_orig[i][j])/3)
for i in range(3):
plt.subplot(1, 3, i+1)
if 0 == i:
# matplotlib使用RGB空间, 而OpenCV使用BGR, 故使用matplotlib显示OpenCV读取的图像的话, 需要将BGR转换成RGB
plt.imshow(cv.cvtColor(img_orig, cv.COLOR_BGR2RGB))
plt.title("原图")
elif 1 == i:
plt.imshow(img_gray, cmap="gray") # cmap表示显示图像的方式, gray表示以灰度图显示
plt.title("算术平均灰度图")
else:
plt.imshow(cv.cvtColor(img_orig, cv.COLOR_BGR2GRAY), cmap="gray")
plt.title("OpenCV转换的灰度图")
plt.xticks([]), plt.yticks([]) # 隐藏X,Y轴
plt.show() # 这句不能漏, 而且只要写一次
运行结果如下, 可以看到相比于OpenCV内置的转灰度图的函数, 上面介绍的简单的取算术平均效果一般

当然不是所有的图都可以有效且合理地转换成灰度图, 比如说二值图(每个像素值不是0就是255)就无法很好地转换成灰度图. 而灰度图可以通过某些算法比较好地转换成伪彩图
BGR图
相比于灰度图, BGR图保留了彩色信息, 学过web的可能更熟悉RGB图, 他们两者很相似, 只是三元数组的顺序不同. 在RGB图中, 由于三元数组[R, G, B]每个字母都是0~255的一个整数, 即8位整型, 故每个字母可以用两个十六进制表示, 比如[15, 32, 255] = [0000 1111, 0010 0000, 1111 1111] = #0F20FF, 这个表示广泛应用于web前端和UI涉及中
HSV图
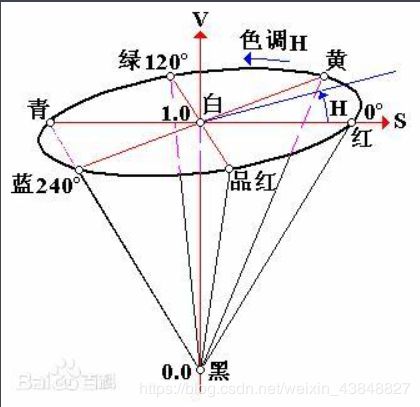
色调H
用角度度量, 取值范围为0°~360°, 从红色开始按逆时针方向计算, 红色为0°, 绿色为120°,蓝色为240°. 它们的补色是:黄色为60°, 青色为180°,品红为300°;
饱和度S
饱和度S表示颜色接近光谱色的程度. 一种颜色, 可以看成是某种光谱色与白色混合的结果. 其中光谱色所占的比例愈大, 颜色接近光谱色的程度就愈高, 颜色的饱和度也就愈高. 饱和度高, 颜色则深而艳. 光谱色的白光成分为0, 饱和度达到最高. 通常取值范围为0%~100%, 值越大, 颜色越饱和.
明度V
明度表示颜色明亮的程度, 对于光源色, 明度值与发光体的光亮度有关;对于物体色, 此值和物体的透射比或反射比有关. 通常取值范围为0%(黑)到100%(白).
RGB颜色模型是面向硬件的, 而HSV(Hue Saturation Value)颜色模型是面向用户的.
HSV模型的三维表示从RGB立方体演化而来. 设想从RGB沿立方体对角线的白色顶点向黑色顶点观察, 就可以看到立方体的六边形外形. 六边形边界表示色彩, 水平轴表示纯度, 明度沿垂直轴测量.

傅里叶变换
这里我只简单介绍一下傅里叶变化, 太详细会占用很大篇幅. 这里我引用另一位博主的非常详细的介绍:
傅里叶变换理论
图像中的傅里叶变换
图像的频率是表征图像中灰度变化剧烈程度的指标,是灰度在平面空间上的梯度。如大面积的沙漠在图像中是一片灰度变化缓慢的区域,对应的频率值很低;而对于地表属性变换剧烈的边缘区域在图像中是一片灰度变化剧烈的区域,对应的频率值较高。傅里叶变换在实际中有非常明显的物理意义,设f是一个能量有限的模拟信号,则其傅里叶变换就表示f的频谱。从纯粹的数学意义上看,傅里叶变换是将一个函数转换为一系列周期函数来处理的。从物理效果看,傅里叶变换是将图像从空间域转换到频率域,其逆变换是将图像从频率域转换到空间域。换句话说,傅里叶变换的物理意义是将图像的灰度分布函数变换为图像的频率分布函数。傅里叶逆变换是将图像的频率分布函数变换为灰度分布函数。
傅里叶变换前图像是由对在连续空间上的采样得到一系列点的集合,通常用一个二维矩阵表示空间上各点,记为z=f(x,y)。又因空间是三维的,图像是二维的,因此空间中物体在另一个维度上的关系就必须由梯度来表示,这样我们才能通过观察图像得知物体在三维空间中的对应关系。
傅里叶频谱图上我们看到的明暗不一的亮点,其意义是指图像上某一点与邻域点差异的强弱,即梯度的大小,也即该点的频率的大小, 图像中的低频部分指低梯度的点,高频部分相反。一般来讲,梯度大则该点的亮度强,否则该点亮度弱。这样通过观察傅里叶变换后的频谱图,也叫功率图,我们就可以直观地看出图像的能量分布. 如果频谱图中暗的点数更多,那么实际图像是比较柔和的(因为各点与邻域差异都不大,梯度相对较小);反之,如果频谱图中亮的点数多,那么实际图像一定是尖锐的、边界分明且边界两边像素差异较大的。
对频谱移频到原点以后,可以看出图像的频率分布是以原点为圆心,对称分布的。将频谱移频到圆心除了可以清晰地看出图像频率分布以外,还有一个好处,它可以分离出有周期性规律的干扰信号,比如正弦干扰。一幅频谱图如果带有正弦干扰,移频到原点上就可以看出,除了中心以外还存在以另一点为中心、对称分布的亮点集合,这个集合就是干扰噪音产生的。这时可以很直观的通过在该位置放置带阻滤波器消除干扰。

图像处理中常用到的是离散傅里叶变换(DTF)以及快速傅里叶变换(FFT), 两者本质并无区别, FFT是实现DFT的一种快速算法.
Python的NumPy中包含了FFT的包, 其中包含了函数fft2(), 可以快速计算一幅图像的离散傅里叶变换DFT(), 计算过程分几步, 具体如以下代码
# 傅里叶变换
def myFFT(img_orig):
"""
对图像ff_img做傅里叶变换, 并显示原图, 以及傅里叶频谱
:param img_orig: 处理的图像
"""
# 先将图片转换成灰度图
if 2 == len(img_orig.shape): # 长度为2说明ff_img已经是灰度图
pass
else:
img_orig = cv.cvtColor(img_orig, cv.COLOR_BGR2GRAY)
f = np.fft.fft2(img_orig) # 做频率变换
fshift = np.fft.fftshift(f) # 转移像素做幅度普
sectrum = np.log(np.abs(fshift)) # 取绝对值,将复数变化成实数,取对数是为了将数据变化到0-255
images = [img_orig, sectrum]
titles = ['原图', '原图傅里叶变换频谱']
for i in range(2):
plt.subplot(1, 2, i + 1)
plt.imshow(images[i], cmap='gray')
plt.title(titles[i], loc='center')
plt.xticks([]), plt.yticks([]) # 隐藏X,Y轴
plt.show()
运行结果如下

傅里叶变换是很多常见图像处理操作的基础, 比如边缘检测, 以及接下来的高通滤波和低通滤波
高通滤波和低通滤波
高通滤波器(HPF)相当于一个二极管, 只允许高于某一阈值的频段通过, 截断图像中的低频部分. 而根据傅里叶变换的原理, 图像内部对象与对象之间的边缘属于高频部分, 因此高通滤波可以提取图像中所有对象的边缘和轮廓, 应用于边缘检测.
相应的, 低通滤波就是保留图像中对象的细节, 比如面部表情, 而去除对象的边缘和轮廓
滤波其实是对图像的卷积(什么是矩阵卷积点击这里), 使用的卷积核必须满足以下条件:
- 最好是方阵, 且行数列数都为奇数
- 所有元素的和为0
- 通常情况下, 元素分布是从中心向外辐射状对称的
例如以下的两个方阵, 都称为 卷积核(kernel)
[ − 1 − 1 − 1 − 1 8 − 1 − 1 − 1 − 1 ] [ − 1 − 1 − 1 − 1 − 1 − 1 1 2 1 − 1 − 1 2 4 2 − 1 − 1 1 2 1 − 1 − 1 − 1 − 1 − 1 − 1 ] \left[ \begin{matrix} -1 & -1 & -1 \\ -1 & 8 & -1 \\ -1 & -1 & -1 \end{matrix} \right] \left[ \begin{matrix} -1 & -1 & -1 & -1 & -1 \\ -1 & 1 & 2 & 1 & -1\\ -1 & 2 & 4 & 2 & -1\\ -1 & 1 & 2 & 1 & -1\\ -1 & -1 & -1 & -1 & -1 \end{matrix} \right] ⎣⎡−1−1−1−18−1−1−1−1⎦⎤⎣⎢⎢⎢⎢⎡−1−1−1−1−1−1121−1−1242−1−1121−1−1−1−1−1−1⎦⎥⎥⎥⎥⎤
def myHighBlur(img_orig):
"""
对图像img进行高通滤波
:param img_orig:
"""
# 先将img转换成灰度图
if 2 == len(img_orig.shape): # 长度为2说明ff_img已经是灰度图
pass
else:
img_orig = cv.cvtColor(img_orig, cv.COLOR_BGR2GRAY)
kernel_3x3 = np.array([[-1, -1, -1],
[-1, 8, -1],
[-1, -1, -1]])
kernel_5x5 = np.array([[-1, -1, -1, -1, -1],
[-1, 1, 2, 1, -1],
[-1, 2, 4, 2, -1],
[-1, 1, 2, 1, -1],
[-1, -1, -1, -1, -1]])
img_convoled_3x3 = ndimage.convolve(img_orig, kernel_3x3)
img_convoled_5x5 = ndimage.convolve(img_orig, kernel_5x5)
img_blurred = cv.GaussianBlur(img_orig, (11, 11), 0) # 高斯滤波其实是低通滤波器
img_GaussianHPF = img_orig - img_blurred # 原图减去低通滤波得到高通滤波
images = [img_orig, img_convoled_3x3, img_convoled_5x5, img_blurred, img_GaussianHPF]
titles = ['原图灰度图', '原图3x3卷积', '原图5x5卷积', '高斯低通滤波', '高斯高通滤波']
for i in range(5):
plt.subplot(2, 3, i + 1)
plt.imshow(images[i], cmap='gray')
plt.title(titles[i], loc='center')
plt.xticks([]), plt.yticks([]) # 隐藏X,Y轴
plt.show()def myHighBlur(img):
"""
对图像img进行高通滤波
:param img:
"""
# 先将img转换成灰度图
if 2 == len(img.shape): # 长度为2说明ff_img已经是灰度图
pass
else:
img = cv.cvtColor(img, cv.COLOR_BGR2GRAY)
kernel_3x3 = np.array([[-1, -1, -1],
[-1, 8, -1],
[-1, -1, -1]])
kernel_5x5 = np.array([[-1, -1, -1, -1, -1],
[-1, 1, 2, 1, -1],
[-1, 2, 4, 2, -1],
[-1, 1, 2, 1, -1],
[-1, -1, -1, -1, -1]])
img_convoled_3x3 = ndimage.convolve(img, kernel_3x3)
img_convoled_5x5 = ndimage.convolve(img, kernel_5x5)
img_blurred = cv.GaussianBlur(img, (11,11), 0) # 高斯滤波其实是低通滤波器
img_GaussianHPF = img-img_blurred # 原图减去低通滤波得到高通滤波
images = [img, img_convoled_3x3, img_convoled_5x5, img_blurred, img_GaussianHPF]
titles = ['原图灰度图', '原图3x3卷积', '原图5x5卷积', '高斯低通滤波', '高斯高通滤波']
for i in range(5):
plt.subplot(2, 3, i + 1)
plt.imshow(images[i], cmap='gray')
plt.title(titles[i], loc='center')
plt.xticks([]), plt.yticks([]) # 隐藏X,Y轴
plt.show()
运行结果如下, 可以看到经过高斯低通滤波处理后原图会变得模糊, 经过高通滤波后原图只剩人物的轮廓, 面部细节被去除

自定义卷积
前面已经介绍过卷积核的3个条件, 这里稍微解释一下几个疑点.
为什么卷积核最好是方阵?
理论上说, 卷积核可以不是方阵, 图像处理中也并非不能用长方形, 但考虑一般来说图像中各个方向比较对称,那么卷积核也做成对称的可能更符合现实情况一些。具体问题具体分析,如用卷积神经网络做行人检测,考虑照片中的行人一般是长条型,那么用长方形卷积核可能反而更好。
为什么卷积核的维数是奇数?
这就涉及到卷积过程中一个叫做padding的步骤, 简单来说就是是否给被卷积图像周围扩充一圈, 扩充出来的位置填0还是填多少. 当卷积核的维数是奇数的时候, padding时才可以做到左右、上下对称, 不会出现上边和左边扩充两列, 下边和右边只扩充一列的情况.
为什么卷积核的所有元素和为 0 0 0?
假设有以下卷积核, 我们看到这个卷积核的作用是, 将中心位置的像素值的9倍, 减去周围8个像素值, 这就导致中心位置的像素与其他像素之间的差值被放大, 这样会将图像锐化
[ − 1 − 1 − 1 − 1 9 − 1 − 1 − 1 − 1 ] \left[ \begin{matrix} -1 & -1 & -1 \\ -1 & 9 & -1 \\ -1 & -1 & -1 \end{matrix} \right] ⎣⎡−1−1−1−19−1−1−1−1⎦⎤
OpenCV中的卷积
OpenCV和SciPy一样提供了图像卷积函数
filter2D(src, ddepth, kernel, dst=None, anchor=None, delta=None, borderType=None)
后面4个可选参数一般不去特别赋值, 主要是前面3个参数src, ddepth, kernel
| 必要参数 | 解释 |
|---|---|
| src | 被卷积图像, 可灰度图可RGB图 |
| ddepth | 目标图像的深度 |
| kernel | 卷积核 |
其中ddepth这个值不是随便取的, 一般情况下取-1, 表示目标图像与原图像同深度, 当然还有其它值可以选, 具体参考下面的表格
| Input depth(src.depth) | 对应可选的Output depth (ddepth) |
|---|---|
| CV_8U | -1 / CV_16S / CV_32F / CV_64F |
| CV_16U / CV_16S | -1 / CV_32F / CV_64F |
| CV_32F | -1 / CV_32F / CV_64F |
| CV_64F | -1 / CV_64F |
这些变量表示的意义如下表
| 数值 | 类型 | 取值范围 |
|---|---|---|
| CV_8U | 8位无符号整数 | 0~255 |
| CV_8S | 8位符号整数 | -128~127 |
| CV_16U | 16位无符号整数 | 0~65535 |
| CV_16S | 16位符号整数 | -32768~32767 |
| CV_32S | 32位符号整数 | -2147483648……2147483647 |
| CV_32F | 32位浮点数 | -FLT_MAX ………FLT_MAX |
| CV_64F | 64位浮点数 | -DBL_MAX ……….DBL_MAX |
边缘与轮廓
前面我们介绍了基础操作之一, 滤波, 这节我们来看检测, 分为边缘检测和轮廓检测
边缘检测与Canny算法
Canny边缘算法非常复杂, 这里简单提一下, 感兴趣的朋友参照这里
Canny算法分为5个步骤: 高斯滤波去噪, 计算梯度, 在边缘上使用非最大抑制(NMS), 在检测到的边缘上使用双阈值去除假阳性, 最后分析所有的边缘之间的连接, 以保留真正的边缘并消除不明显的边缘.
好在OpenCV提供了一个非常方便的Canny函数, 该算法非常流行, 不仅仅是因为它的效果, 还因为它在OpenCV中的实现非常简单, 仅需一句代码.
def myCanny(img_orig):
"""
对图像进行Canny边缘检测, img必须为灰度图
:param img_orig:
"""
# 先将img转换成灰度图
if 2 == len(img_orig.shape): # 长度为2说明ff_img已经是灰度图
pass
else:
img_orig = cv.cvtColor(img_orig, cv.COLOR_BGR2GRAY)
img_canny = cv.Canny(img_orig, 200, 300) # Canny检测, 双阈值为200和300
images = [img_orig, img_canny]
titles = ['原图', 'Canny边缘检测']
for i in range(2):
plt.subplot(1, 2, i + 1)
plt.imshow(images[i], cmap='gray')
plt.title(titles[i], loc='center')
plt.xticks([]), plt.yticks([]) # 隐藏X,Y轴
plt.show()
运行结果如下

cv.Canny(image, threshold1, threshold2, edges=None, apertureSize=None, L2gradient=None)
后面3个参数我们不去管它, 主要是前面3个, image是原图像(灰度图最佳), 后面两个是检测边缘时的两个阈值, 低于threshold1, 或高于threshold2的部分会被舍弃.
熟悉轮廓检测
在计算机视觉中, 轮廓检测则是另一个比较重要的任务, 不单是用来检测图像或者视频帧中物体的轮廓, 而且还有其他操作与轮廓检测有关, 比如计算多边形边界, 形状逼近和计算显著性区域. 由于NumPy中的矩形区域可以使用数组切片来定义, 这些操作就显得比较简单.
我们通过下面的例子来熟悉API
def apiTest():
img = np.zeros((200, 200), dtype=np.uint8) # 200*200的全黑图像
img[50:150, 50:150] = 255 # 在img中间取一段100*100的全白
ret, img_thresh = cv.threshold(img, 127, 255, 0) # 设置阈值
img_modified, contours, hierarchy = cv.findContours(deepcopy(img_thresh), cv.RETR_TREE, cv.CHAIN_APPROX_SIMPLE)
img_colored = cv.cvtColor(img, cv.COLOR_GRAY2BGR)
img_contoured = cv.drawContours(img_colored, contours, -1, (0, 255, 0), 2)
images = [img_thresh, img_contoured]
titles = ['原图', '轮廓检测']
for i in range(2):
plt.subplot(1, 2, i + 1)
if 0 == i:
plt.imshow(cv.cvtColor(img, cv.COLOR_GRAY2RGB))
else:
plt.imshow(images[i])
plt.title(titles[i], loc='center')
plt.xticks([]), plt.yticks([]) # 隐藏X,Y轴
plt.show()
运行效果如下, 很明显地将原图中白色区域地轮廓用绿色标注了出来

这里用到了几个函数, 介绍一下
threshold(src, thresh, maxval, type, dst=None)
这个函数实现了图像地阈值分割, thresh为设置地阈值, maxval为阈值的最大值, type见下表
| type取值 | 意义 | 具体含义 |
|---|---|---|
| THRESH_BINARY | 二进制阈值化 | 大于阈值为1, 小于阈值为0 |
| THRESH_BINARY_INV | 反二进制阈值化 | 大于阈值为0, 小于阈值为1 |
| THRESH_TRUNC | 截断阈值化 | 大于阈值为阈值, 小于阈值不变 |
| THRESH_TOZERO | 阈值化为0 | 大于阈值不变, 小于阈值的全为0 |
| THRESH_TOZERO_INV | 反阈值化为0 | 大于阈值为0, 小于阈值不变 |
findContours(image, mode, method, contours=None, hierarchy=None, offset=None)
这个函数有3个参数, 输入图像image, 层次类型mode, 以及轮廓逼近方法method. 它也有三个返回值, 依次是: 修改后的图像, 图像的轮廓, 以及它们的层次.
需要注意的是:
-
这个函数会直接修改输入图像并返回, 所以调用时建议使用原图的deepcopy
- 由函数返回的曾次数相当重要: cv.RETR_TREE参数会得到图像中轮廓的整体层次结构, 以此来建立轮廓之间的关系. 如果只想得到最外面的轮廓, 可以使用cv.RETR_EXTERNAL. 这对消除包含在其它轮廓中的轮廓很有用.
drawContours(image, contours, contourIdx, color, thickness=None, lineType=None, hierarchy=None, maxLevel=None, offset=None)
这个函数看名字就知道是在图像中绘制轮廓.
- 第一个参数image是指明在哪幅图像上绘制轮廓;image为三通道才能显示轮廓
- 第二个参数contours是轮廓本身,在Python中是一个list;
- 第三个参数contourIdx指定绘制轮廓list中的哪条轮廓,如果是-1,则绘制其中的所有轮廓。
- 第四个参数color为用什么颜色进行绘制。
- 第五个参数thickness为绘制的线条的粗细
边界框、最小矩形区域和最小闭圆轮廓
有了前面的基础, 我们就可以开始处理一些比较复杂的问题
检测正方形这种形状很简单, 下面我们来检测一些不规则图形, 比如下面这只戒指.

现实的应用会对目标的边界框, 最小矩形区域以及最小闭圆特别感兴趣. 将findContours与其它OpenCV API的功能相结合, 就能非常容易地实现这些功能. 所谓最小, 就是用面积最小的图形, 去覆盖整个被识别的目标.
def drawShapes(img):
"""
在图像img上标注边界框, 最小矩形区域以及最小闭圆
:param img:
"""
img_orig = deepcopy(img)
img = cv.pyrDown(img) # 图像金字塔, 下采样, 输出图像大小为原图像的1/4
# 下一步取得灰度图的二值图像
ret, img_threshed = cv.threshold(cv.cvtColor(deepcopy(img), cv.COLOR_BGR2GRAY), 127, 255, cv.THRESH_BINARY)
# 获得边框list
image_contoured, contours, hier = cv.findContours(img_threshed, cv.RETR_EXTERNAL, cv.CHAIN_APPROX_SIMPLE)
for con in contours:
# 获得边框的坐标(x, y)为最左上角像素的坐标, w, h为该边框的宽和高
x, y, w, h = cv.boundingRect(con)
# 用绿色(0, 255, 0), 将两个点(x, y)和(x+w, y+h)确定的矩形区域给标注出来, 绿色的标注线粗细为2
cv.rectangle(img, (x, y), (x+w, y+h), (0, 255, 0), 2)
rect_min = cv.minAreaRect(con) # 找到最小矩形区域
box = cv.boxPoints(rect_min) # 计算最小矩形区域的坐标
box = np.int0(box) # 将坐标映射到整数
# 画出边框, 蓝线, 粗细为3
# 这里注意, box是一个边框对象, 而drawContours()接受的必须是边框的一个list, 故这里需要将box装换成list
# 至于第四个参数, 这里写0和-1没区别. 0 表示只画出第二个参数list中的第一个边框, -1表示画出List中的所有边框
cv.drawContours(img, [box], 0, (0, 0, 255), 3)
(x, y), radius = cv.minEnclosingCircle(con) # 计算最小闭圆的圆心和半径
center = (int(x), int(y)) # 映射到整数
radius = int(radius) # 映射到整数
# 画出这个最小闭圆, 用黄色, 粗细2
img = cv.circle(img, center, radius, (255, 255, 0), 2)
# 画出所有边框, 红色, 粗细1
img_contoured = cv.drawContours(img, contours, -1, (255, 0, 0), 1)
images = [img_orig, img_contoured]
titles = ['原图', """边界框(绿)\n 最小矩形区(蓝)\n 最小闭圆(黄)\n 所有边界(红)"""]
for i in range(2):
plt.subplot(1, 2, i + 1)
plt.imshow(images[i])
plt.title(titles[i], loc='center')
plt.xticks([]), plt.yticks([]) # 隐藏X,Y轴
plt.show()
运行结果如下

这里简单解释一下几个新的API
"""
pyrDown()实现了金字塔的下采样, 图像长宽减半, 分辨率也会下降, 整个图像会显得很模糊. 默认是长宽各取原来的1/2, 也可以取原来的1/4, 1/8等等.
pyrDown()可以简单理解为, 将一幅图像缩小, 但是不保留原来的清晰度
"""
pyrDown(src, dst=None, dstsize=None, borderType=None)
"""
boundingRect(img)这个函数很简单, array是一个二值图,也就是它的参数, 返回四个值,分别是x, y,w,h;
x,y是矩阵左上点的坐标,w,h是矩阵的宽和高
然后利用 rectangle(img, (x,y), (x+w,y+h), (0,255,0), 2)画出该矩形
同理, 之后下面3个函数也是一样的道理
"""
boundingRect(array)
rectangle(img, pt1, pt2, color, thickness=None, lineType=None, shift=None)
minAreaRect(points)
minEnclosingCircle(points)
circle(img, center, radius, color, thickness=None, lineType=None, shift=None)
这里给出上面整个drawShapes函数的逻辑
首先我们需要对原图像的灰度图像进行二值化操作. 这样可在这个灰度图像上执行所有计算轮廓的操作, 但在原图像上可以用色彩信息来画出这些轮廓. 说白了就是保护原图像不被修改
第一步, 我们计算出一个简单的边界框:
x, y, w, h = cv.boundingRect(con)
这个操作非常简单, 它将轮廓信息转换成(x, y)坐标, 并加上矩形的高度和宽度. 画出这个矩形也非常简单, 仅用下面一句就可以实现.
cv.rectangle(img, (x, y), (x+w, y+h), (0, 255, 0), 2)
第二步我们计算出包围目标的最小矩形区域:
rect = cv.minAreaRect(con)
box = cv.boxPoints(rect)
box = np.int0(box)
这里用到一种很有趣的机制: OpenCV没有函数能直接从轮廓信息中计算出最小矩形顶点的坐标. 所以需要计算出最小矩形区域, 然后计算这个矩形的顶点. 注意计算出来的顶点坐标是浮点型, 但是像素坐标必须是整型.所以需要一个强制转换. 然后再用下面的代码画出这个矩形
# 画出边框, 蓝线, 粗细为3
# 这里注意, box是一个边框对象, 而drawContours()接受的必须是边框的一个list, 故这里需要将box装换成list
# 至于第四个参数, 这里写0和-1没区别. 0 表示只画出第二个参数list中的第一个边框, -1表示画出List中的所有边框
cv.drawContours(img, [box], 0, (0, 0, 255), 3)
最后检查的边界轮廓为最小闭圆
(x, y), radius = cv.minEnclosingCircle(con)
minEnclosingCircle()返回一个二元组, 第一个元素为圆心的坐标组成的元组, 第二个元素为圆的半径值
细心的朋友不知道发现没有, 大多数绘图函数都会把绘图的颜色和密度放在最后两个参数
图轮廓与Douglas-Peucker算法
很多时候,物体的形状都是变换多样的, 而凸形状上的任意两点之间的连线, 都在该形状里面.
利用这一点, OpenCV提供了cv.approPloyDP()这个API, 它用来计算近似的多边形框.
"""
该函数接受3个参数
第一个参数curve为轮廓
第二个参数epsilon为罗马字母ε表示轮廓与近似多边形的最大差值, 这个值越小, 多边形与源轮廓拟合地越好
第三个参数为bool类型, 表示这个多边形是否闭合
"""
approxPolyDP(curve, epsilon, closed, approxCurve=None)
ϵ \epsilon ϵ值对获取有用的轮廓非常重要, 所以需要理解. 一般来说, ϵ \epsilon ϵ取近似多边形与源轮廓两者周长的差值, 这个值越小, 近似多边形越理想.
在了解了 ϵ \epsilon ϵ之后, 我们需要得到轮廓的周长信息来作为参考值, 这可以通过OpenCV内置的cv.arcLength()来完成
epsilon = 0.001 * cv.arcLength(cnt, True) # 该函数返回轮廓cnt的周长, True表示轮廓是闭合的
approx = cv.approxxPloyDP(cnt, epsilon, True)
这样, 我们就得到了源轮廓的一个近似轮廓approx.
为了计算凸形状, 需要用convexHull()来获取处理过的轮廓信息, 可通过下面一行代码来实现
hull = cv.convexHull(cnt)
细心的同学可能注意到了, 我们引入近似的轮廓是为了逼近源轮廓, 而为了得到这个近似的轮廓, 我们首先需要一个完整的源轮廓, 这是个先有鸡还是先有蛋的问题. 事实上, 我们引入近似的轮廓不光光是为了逼近源轮廓, 更是因为多边形的近似轮廓有更多的直线, 而不是曲线, 这就方便我们之后的操作和处理.
完整的多边形检测DP算法如下
def myDP(img):
"""
用多边形对img的轮廓进行拟合
:param img:
"""
ret, img_thresh = cv.threshold(cv.cvtColor(img, cv.COLOR_BGR2GRAY), 127, 255, cv.THRESH_BINARY) # 设置阈值
img_modified, contours, hier = cv.findContours(deepcopy(img_thresh), cv.RETR_EXTERNAL, cv.CHAIN_APPROX_SIMPLE)
black = cv.cvtColor(np.zeros((img.shape[1], img.shape[0]), dtype=np.uint8), cv.COLOR_GRAY2BGR)
for cnt in contours:
epsilon = 0.01*cv.arcLength(cnt, True)
approx = cv.approxPolyDP(cnt, epsilon, True)
hull = cv.convexHull(cnt)
cv.drawContours(black, [cnt], -1, (0, 255, 0), 2) # 源轮廓绿色
cv.drawContours(black, [approx], -1, (255, 255, 0), 2) # 近似多边形蓝色
cv.drawContours(black, [hull], -1, (0, 0, 255), 2) # hull红色
plt.imshow(cv.cvtColor(black, cv.COLOR_BGR2RGB))
plt.title("hull红色, 源轮廓绿色, approx蓝色", loc='center')
plt.xticks([]), plt.yticks([]) # 隐藏X,Y轴
plt.show()
上面贴出来的戒指的图像运行结果如下

形状检测
边缘检测和轮廓检测不仅重要, 而且经常会用到, 他们也是构成其他复杂操作的基础. 直线和圆检测与边缘轮廓检测有着密切的关系.
Hough变换是直线和形状检测背后的理论基础, 由Richard Duda和Peter Hart提出, 他们是对Paul Hough在20世纪60年代早期工作的扩展.
下面介绍OpenCV中的Hough变换的API
直线检测
首先介绍直线检测, 者可通过HoughLInes和HoughLinesP函数来实现, 它们仅有的前者使用标准的Hough变换, 后者使用概率Hough变换.
HoughLinesP只通过分析点的子集, 并估计这些点都属于一条直线的概率, 这是标准Hough变换的优化, 所以该函数执行起来消耗的资源会少一点. 来看一个例子
def lineDetect(img):
"""
检测图像中的直线
:param img:
"""
img_orig = deepcopy(img)
img_gray = cv.cvtColor(img, cv.COLOR_BGR2GRAY)
edges = cv.Canny(img_gray, 50, 120)
line = 100
minLineLength = 20
lines = cv.HoughLinesP(edges, 1, np.pi/180, 100, lines=line, minLineLength=minLineLength)
lines1 = lines[:, 0, :]
for x1, y1, x2, y2 in lines1:
cv.line(img, (x1, y1), (x2, y2), (0, 255, 0), 2)
images = [img_orig, img]
titles = ['原图', '直线检测']
for i in range(2):
plt.subplot(1, 2, i+1)
plt.imshow(cv.cvtColor(images[i], cv.COLOR_BGR2RGB))
plt.title(titles[i], loc='center')
plt.xticks([]), plt.yticks([]) # 隐藏X,Y轴
plt.show()
运行结果如下

首先解释一下HoughLinesP的几个参数
"""
image 参数表示边缘检测的输出图像,该图像为单通道8位二进制图像。
rho 参数表示参数极径 以像素值为单位的分辨率,这里一般使用 1 像素。
theta 参数表示参数极角 以弧度为单位的分辨率,这里使用 1度。
threshold 参数表示检测一条直线所需最少的曲线交点。
lines 参数表示储存着检测到的直线的参数对的容器,也就是线段两个端点的坐标。
minLineLength 参数表示能组成一条直线的最少点的数量,点数量不足的直线将被抛弃。
maxLineGap 参数表示能被认为在一条直线上的亮点的最大距离
"""
HoughLinesP(image, rho, theta, threshold, lines=None, minLineLength=None, maxLineGap=None)
HoughLinesP会接收一个由处理过的单通道二值图像, 普遍使用Canny滤波器来去噪后传给HoughLinesP
圆检测
类似的, OpenCV的HoughCircles()可以来检测圆, 它的使用与HoughLines很相似. 比如HoughLines有用来决定删除还是保留直线的两个参数minLineLength和maxLineGap, HoughCircle也有圆心间的最小距离和最小最大半径三个参数.
下面来看一个例子
def circleDetect(img):
"""
检测图像中的圆形
:param img:
"""
img_orig = deepcopy(img)
img_copy = deepcopy(img)
img_gray = cv.cvtColor(img, cv.COLOR_BGR2GRAY)
img = cv.medianBlur(img_gray, 5)
circles = cv.HoughCircles(img, cv.HOUGH_GRADIENT, 1, 120, param1=100, param2=30, minRadius=40, maxRadius=100)
circles = np.uint16(np.around(circles))
for i in circles[0, :]:
cv.circle(img_copy, (i[0], i[1]), i[2], (0, 255, 0), 2) # 绿色标注圆周
cv.circle(img_copy, (i[0], i[1]), 2, (0, 0, 255), 3) # 红色标注圆心
images = [img_orig, img_copy]
titles = ['原图', '圆检测']
for i in range(2):
plt.subplot(1, 2, i+1)
plt.imshow(cv.cvtColor(images[i], cv.COLOR_BGR2RGB))
plt.title(titles[i], loc='center')
plt.xticks([]), plt.yticks([]) # 隐藏X,Y轴
plt.show()
运行结果如下
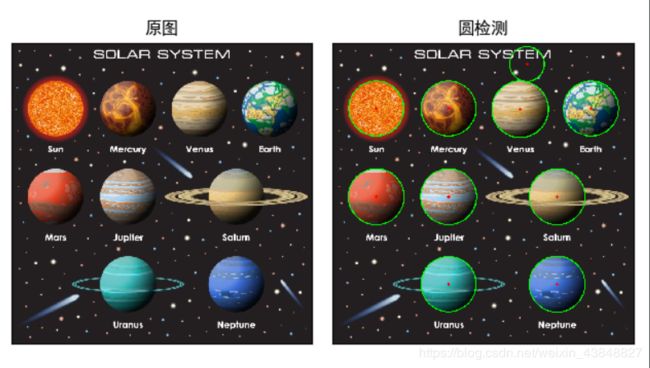
原理同直线检测是一样的, 这里就简单提一下HoughCircles的几个参数
"""
image 输入图像
method cv2.HOUGH_GRADIENT 也就是霍夫圆检测,梯度法
dp 计数器的分辨率图像像素分辨率与参数空间分辨率的比值.dp=1,则参数空间与图像像素空间(分辨率)一样大, dp=2,参数空间的分辨率只有像素空间的一半大
minDist 圆心之间最小距离,如果距离太小,会产生很多相交的圆,如果距离太大,则会漏掉正确的圆
param1 canny检测的双阈值中的高阈值,低阈值是它的一半
param2 最小投票数(基于圆心的投票数), 低于这个投票数的点会被丢弃
minRadius 需要检测院的最小半径
maxRadius 需要检测院的最大半径
"""
HoughCircles(image, method, dp, minDist, circles=None, param1=None, param2=None, minRadius=None, maxRadius=None)
至此, 本章内容结束, 我们来一个总结
章节总结
这章我们学习了色彩空间, 傅里叶变换和多种OpenCV的API. 特别需要掌握的是filter2D卷积, Canny边缘检测以及轮廓检测. 这些都是后续章节的基础.
等所有章节结束后, 我会将完整项目上传到github
本章所有API
"""
NumPy的API如下
"""
# 傅里叶频率变换
np.fft.fft2(img_orig)
# 转移像素形成傅里叶幅度普
fshift = np.fft.fftshift(np.fft.fft2(img_orig))
img_back = np.fft.ifft2(fshift)
"""
SciPy的API如下
"""
# 图像卷积
ndimage.convolve(input, weights, output=None, mode='reflect', cval=0.0,
origin=0)
"""
OpenCV的API如下
"""
# 色彩空间转换
cvtColor(src, code, dst=None, dstCn=None)
# 高斯低通滤波
GaussianBlur(src, ksize, sigmaX, dst=None, sigmaY=None, borderType=None)
# 图像卷积
filter2D(src, ddepth, kernel, dst=None, anchor=None, delta=None, borderType=None)
# Canny边缘检测
Canny(image, threshold1, threshold2, edges=None, apertureSize=None, L2gradient=None)
# 阈值分割
threshold(src, thresh, maxval, type, dst=None)
# 轮廓检测
findContours(image, mode, method, contours=None, hierarchy=None, offset=None)
# 标注出轮廓
drawContours(image, contours, contourIdx, color, thickness=None, lineType=None, hierarchy=None, maxLevel=None, offset=None)
# 金字塔下采样
pyrDown(src, dst=None, dstsize=None, borderType=None)
# 将轮廓i西南西转换成(x, y)坐标, 并加上矩形的高度和宽度
boundingRect(array)
# 画出矩形
rectangle(img, pt1, pt2, color, thickness=None, lineType=None, shift=None)
# 最小矩形区域
minAreaRect(points)
# 最小闭圆
minEnclosingCircle(points)
# 画出圆形
circle(img, center, radius, color, thickness=None, lineType=None, shift=None)
# 计算近似的多边形边框
approxPolyDP(curve, epsilon, closed, approxCurve=None)
# 获取处理过的轮廓信息
convexHull(cnt)
# 直线检测
HoughLinesP(image, rho, theta, threshold, lines=None, minLineLength=None, maxLineGap=None)
# 圆检测
HoughCircles(image, method, dp, minDist, circles=None, param1=None, param2=None, minRadius=None, maxRadius=None)
本章完整代码
本章所有代码已上传至本人资源(点此下载), 无需积分即可下载