trie 树及其可持久化
trie 树及其可持久化
前言
本文主要介绍字符串组的存储方法,trie 字典树,首先我们讨论 trie 树的几个问题:
- trie 树的提出
- trie 树的实现
- trie 树的应用
在 trie 树的应用之中,我们介绍的它的特殊形式:01 字典树,并介绍区间异或最值问题。掌握 trie 树的相关算法后,讨论 trie 树的可持久化,解决更多的问题。
trie 字典树
trie 树的提出
存储大量的字符串时,一般的做法是,每一个串都分别记录,这样空间的使用就是总字符个数。我们考虑这样一个例子:字符串 A = aaaaaab 字符串 B = aaaaaac,这两个串是不同的,但是它们有很长的公共前缀,在最后一位,它们“分支”了,走向两个不同的串,这种枝丫一样的扩展方式,启示着人们优化存储空间的方法。
trie 树的构建
下面是一个 trie 树的例子,每个单词的结尾对应一个单词节点。反过来。从根节点到每一个单词节点的路径上的字母就组成字符串。
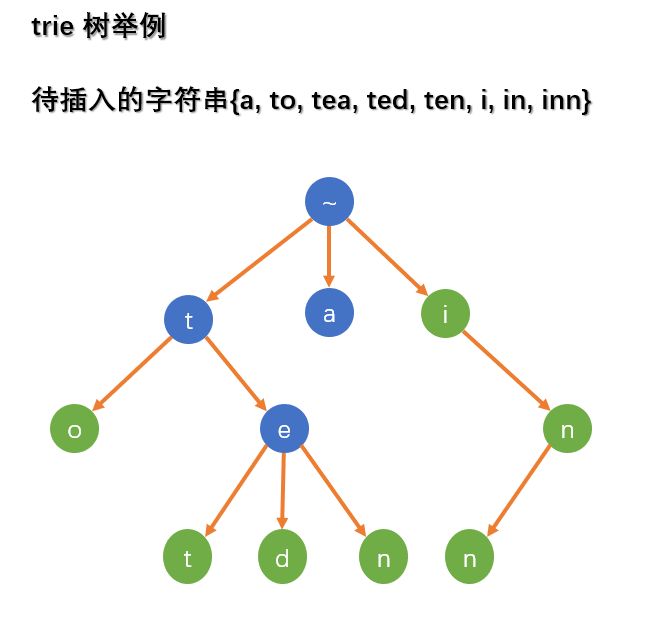
具体来说,用 ch[i][j] 保存第 i 个字符的编号为 j 的儿子,如果结点不存在,则表示不存在这样一个字符串。使用 trie 的时候,往往需要一些结点的附加信息,这都并不复杂。
下面的代码中,val[i] > 0 表示这是一个单词节点。
struct Trie
{
int ch[maxn][sigmasize];
int val[maxn];
int sz;
Trie(){ sz = 1; memset(ch[0], 0, sizeof(ch[0]));}
int idx(char c){ return c - 'a'; }
inline void insert(char *s, int v)
{
int u = 0, n = strlen(s);
for(int i = 0; i < n; i++)
{
int c = idx(s[i]);
if(!ch[u][c])
{
memset(ch[sz], 0, sizeof(ch[sz]));
val[sz] = 0;
ch[u][c] = sz++;
}
u = ch[u][c];
}
val[u] = v;
}
inline bool find(char *s)
{
int u = 0, n = strlen(s);
for(int i = 0; i < n; i++)
{
int c = idx(s[i]);
if(ch[u][c] == 0) return false;
u = ch[u][c];
}
return true;
}
};
trie 树的应用
trie 具有一些优美的性质:
-
两个串的最长公共前缀是两个点的
lca到根的字符串。 -
可以方便的统计在所给出的所有串中某个前缀出现的次数。
-
可以方便的进行字符串的字典序排序。
-
可以进行词频统计。
-
是 A h o − C o r a s i k Aho-Corasik Aho−Corasik 自动机的匹配构建基石。
trie 树的优化(拓展)
读者应该已经发现了,trie 树的空间还没有优化到极致,还存在着为添加父子关系而预留的儿子接口,这使得每一个节点的接口数量达到字符集大小。
优化方法是,采用左儿子-右兄弟法表示这棵 trie,下面给出具体的算法。
struct Trie
{
int head[maxnode]; // head[i]为第i个结点的左儿子编号
int next[maxnode]; // next[i]为第i个结点的右兄弟编号
char ch[maxnode]; // ch[i]为第i个结点上的字符
int sz; // 结点总数
void clear()
{
sz = 1; tot[0] = head[0] = next[0] = 0;
}
void insert(const char *s)
{
int u = 0, v, n = strlen(s);
tot[0]++;
for(int i = 0; i < n; i++)
{
bool found = false;
for(v = head[u]; v != 0; v = next[v]) if(ch[v] == s[i])
{
found = true;
break;
}
if(!found)
{
v = sz++;
tot[v] = 0;
ch[v] = s[i];
next[v] = head[u];
head[u] = v;
head[v] = 0;
}
u = v;
tot[u]++;
}
}
};
01 字典树
介绍完普适的 trie 树,下面介绍一种在“异或”领域翻江倒海的数据结构,01 字典树是 trie 的一个变体,每一个节点要么是 1 要么是 0, 所以 01 字典树一定是一个二叉树,通过 01 字典树可以方便的求解一些与异或有关的问题。
01 字典树的构建
我们按照最大数字的二进制位的长度来确定树的高度,其余不足位数的在之前使用 0 补齐,将这些串插入到 trie 树中即可。
在具体的实现中,我们不需要存储这些串,使用二进制运算判断二进制位是 0 还是 1 即可。
可以参考下面的代码:
struct Trie
{
int sz;
int ch[maxn][2], val[maxn];
inline void init()
{
this->sz = 1;
memset(ch[0], 0, sizeof(ch[0]));
}
inline void insert(int x)
{
int u = 0;
for(int i = maxlog; i >= 0; i--)
{
int c = (x & (1 << i)) >> i;
if(ch[u][c] == 0)
{
ch[u][c] = sz;
this->sz = sz + 1;
}
u = ch[u][c];
}
val[u] = 1;
}
}trie;
异或问题
在介绍 01 字典树的应用之前,先来介绍异或问题。异或问题是研究数列上的异或性质的一类问题,例如区间最大异或,异或和相关问题等,解决这些问题通常用到下面的几个性质:
- 交换律 a ⨁ b = a ⨁ b a \bigoplus b = a \bigoplus b a⨁b=a⨁b .
- 结合律 ( a ⨁ b ) ⨁ c = a ⨁ ( b ⨁ c ) \left( a \bigoplus b \right)\bigoplus c = a \bigoplus \left( b \bigoplus c \right) (a⨁b)⨁c=a⨁(b⨁c)
- 自反性 x ⨁ x = 0 x \bigoplus x = 0 x⨁x=0
- 或 0 不变性 x ⨁ 0 = x x \bigoplus 0 = x x⨁0=x
根据自反性质,区间的异或值具有前缀性质,即
⨁ i = l r a i = ( ⨁ i = 1 l − 1 a i ) ⨁ ( ⨁ i = 1 r a i ) \bigoplus_{i = l}^{r} a_i = \left( \bigoplus_{i = 1}^{l - 1} a_i \right) \bigoplus \left( \bigoplus_{i = 1}^{r} a_i\right) i=l⨁rai=(i=1⨁l−1ai)⨁(i=1⨁rai)
因此我们可以更方便地处理问题。
01 字典树与最大异或值问题
考虑这样一个问题,求解一个数与一个给定数列中的哪一个数的异或值是最大的。
不难发现,一个数的二进制 01 串中的高位决定数的大小的优先级更高,最高位为 1 的数无论如何都比最高位为 0 的数大。利用这个性质,我们得到一个基于贪心的想法,因为在异或操作中,相同为 0, 不同唯一,于是我们尽量寻找最高一位与原串不同的串即可,这个过程可以在 01 字典树上实现,每一次如果有可能,只需要走向原串的反方向即可。
具体实现参考代码:
struct Trie
{
int sz;
int ch[maxn][2], val[maxn];
inline void init()
{
this->sz = 1;
memset(ch[0], 0, sizeof(ch[0]));
}
inline void insert(int x)
{
int u = 0;
for(int i = maxlog; i >= 0; i--)
{
int c = (x & (1 << i)) >> i;
if(ch[u][c] == 0)
{
ch[u][c] = sz;
this->sz = sz + 1;
}
u = ch[u][c];
}
val[u] = 1;
}
inline int query(int x)
{
int ans = 0, u = 0;
for(int i = maxlog; i >= 0; i--)
{
int c = (x & ( 1 << i)) >> i;
if(ch[u][c ^ 1])
{
ans = ans + (1 << i);
u = ch[u][c ^ 1];
}
else u = ch[u][c];
}
return ans;
}
}trie;
可持久化字典树
可持久化是一个重要的算法思想,结合备份与函数式编程的思想,是解决问题的利器。我对于可持久化的理解就是:支持回到一个历史版本并回答一些在历史版本上的询问,支持从一个历史版本,通过响应操作扩展出另一个新的版本,下面介绍 trie 是如何实现可持久化的。
对于问题的一个想法
既然我们现在要访问一个历史版本,那么我们直观的想法就是将每一个版本的 trie 结构体都存储下来,当需要一个新的结点时,我们完全复制一个历史版本,然后再它上面完成操作。这样的做法,正确性是显然的,但是空间开销却让人头疼。当务之急是减少存储空间,我们考虑将 trie 树上的一些“枝条”共用来减少空间上的浪费。
空间优化的实现
我们是这样做的:对于一个新建的版本,每插入一个点都新建一个节点,然后完全复制历史版本上同等地位点的全部儿子信息,可以看下面这张图来方便你的理解。
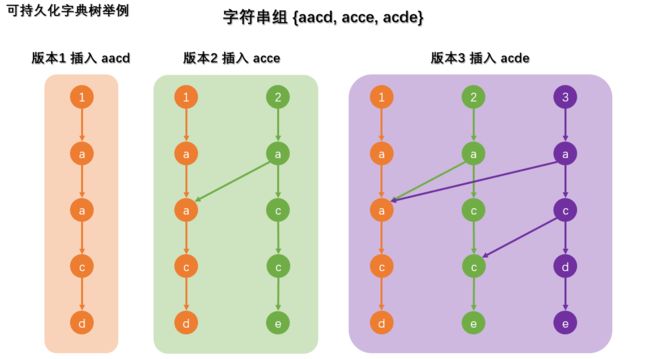
通过上图我们发现,从一个版本起点开始,遍历整棵树,一定只能获得该版本内的所有串,并且空间大大减少,是不是非常优美。
对于区间 [ l , r ] [l,r] [l,r]上的一些询问,我们转化为对版本 l − 1 l - 1 l−1 和 r r r 之间插值的询问。这样就可以通过可持久化的方法来求解区间信息。
因为 01 字典树的父子关系简单,下面以 01 字典树为例,提供代码:
struct Trie
{
int cnt;
int ch[maxn * 24][2], sum[maxn * 24];
inline int insert(int x, int val)
{
int o, y; o = y = ++cnt;
for(int i = 23; i >= 0; i--)
{
//复制儿子的所有相关信息
ch[y][0] = ch[x][0];
ch[y][1] = ch[x][1];
//更新位置计数
sum[y] = sum[x] + 1;
int c = (val & (1 << i)) >> i;
//新建结点
x = ch[x][c];
ch[y][c] = ++cnt;
y = ch[y][c];
}
sum[y] = sum[x] + 1;
return o;
}
inline int query(int l, int r, int val)
{
int ans = 0;
for(int i = 23; i >= 0; i--)
{
int c = (val & (1 << i)) >> i;
//使用差值判断是否存在
if(sum[ch[r][c ^ 1]] - sum[ch[l][c ^ 1]])
{
ans = ans + (1 << i);
r = ch[r][c ^ 1];
l = ch[l][c ^ 1];
}
else
{
r = ch[r][c];
l = ch[l][c];
}
}
return ans;
}
}trie;
后记
这是我写的关于字符串的原创系列的第二篇了,感觉对于字符串的理解更深入了,同时也感谢对文章直接间接帮助的文章。
推荐下面几篇关于 trie 树的文章:
-
《算法竞赛入门经典·训练指南》
-
01 字典树
-
可持久化 trie 树
谢谢阅读。