Kylin -- 增量构建 自动合并分区 自动删除Segment
增量构建应用场景
Kylin在每次Cube的构建都会从Hive中批量读取数据,而对于大多数业务场景来说,Hive中的数据处于不断增长的状态。为了支持Cube中的数据能够不断地得到更新,且无需重复地为已经处理过的历史数据构建Cube,因此对于 Cube引入了增量构建的功能
理解Cube、Cuboid与Segment的关系
Kylin将Cube划分为多个Segment(对应就是HBase中的一个表),每个Segment用起始时间和结束时间来标志。Segment代表一段时间内源数据的预计算结果。一个Segment的起始时间等于它之前那个Segment的结束时间,同理,它的结束时间等于它后面那个Segment的起始时间。同一个Cube下不同的Segment除了背后的源数据不同之外,其他如结构定义、构建过程、优化方法、存储方式等都完全相同。
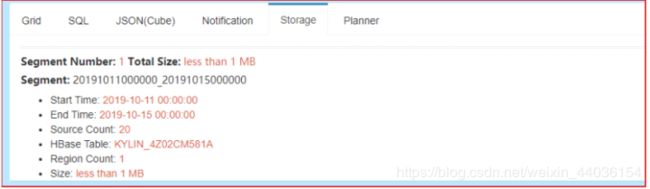
一个Cube,可以包含多个Cuboid,而Segment是指定时间范围的Cube,可以理解为Cube的分区。对应就是HBase中的一张表。该表中包含了所有的Cuboid。
例如:以下为针对某个Cube的Segment
| Segment名称 |
分区时间 |
HBase表名 |
| 201910110000000-201910120000000 |
20191011 |
KYLIN_41Z8123 |
| 201910120000000-201910130000000 |
20191012 |
KYLIN_5AB2141 |
| 201910130000000-201910140000000 |
20191013 |
KYLIN_7C1151 |
| 201910140000000-201910150000000 |
20191014 |
KYLIN_811680 |
| 201910150000000-201910160000000 |
20191015 |
KYLIN_A11AD1 |
全量构建与增量构建
全量构建
在全量构建中,Cube中只存在唯一的一个Segment,该Segment没有分割时间的概念,也就没有起始时间和结束时间。全量构建和增量构建各有其适用的场景,用户可以根据自己的业务场景灵活地进行切换。对于全量构建来说,每当需要更新Cube数据的时候,它不会区分历史数据和新加入的数据,也就是说,在构建的时候会导入并处理所有的原始数据。
增量构建
增量构建只会导入新Segment指定的时间区间内的原始数据,并只对这部分原始数据进行预计算。
全量构建和增量构建的对比
| 全量构建 |
增量构建 |
| 每次更新时都需要更新整个数据集 |
每次只对需要更新的时间范围进行更新,因此离线计算量相对较小 |
| 查询时不需要合并不同Segment的结果 |
查询时需要合并不同Segment的结果,因此查询性能会受影响 |
| 不需要后续的Segment合并 |
累计一定量的Segment之后,需要进行合并 |
| 适合小数据量或全表更新的Cube |
适合大数据量的Cube |
全量构建与增量构建的Cube查询方式对比:
- 全量构建Cube
- 查询引擎只需向存储引擎访问单个Segment所对应的数据,无需进行Segment之间的聚合
- 为了加强性能,单个Segment的数据也有可能被分片存储到引擎的多个分区上,查询引擎可能仍然需要对单个Segment不同分区的数据做进一步的聚合
- 增量构建Cube
- 由于不同时间的数据分布在不同的Segment之中,查询引擎需要向存储引擎请求读取各个Segment的数据
- 增量构建的Cube上的查询会比全量构建的做更多的运行时聚合,通常来说增量构建的Cube上的查询会比全量构建的Cube上的查询要慢一些。
对于小数据量的Cube,或者经常需要全表更新的Cube,使用全量构建需要更少的运维精力,以少量的重复计算降低生产环境中的维护复杂度。而对于大数据量的Cube,例如,对于一个包含两年历史数据的Cube,如果需要每天更新,那么每天为了新数据而去重复计算过去两年的数据就会变得非常浪费,在这种情况下需要考虑使用增量构建
增量构建Cube过程
1、指定分割时间列
增量构建Cube的定义必须包含一个时间维度,用来分割不同的Segment,这样的维度称为分割时间列(Partition Date Column)。
2、增量构建过程
- 在进行增量构建时,将增量部分的起始时间和结束时间作为增量构建请求的一部分提交给Kylin的任务引擎
- 任务引擎会根据起始时间和结束时间从Hive中抽取相应时间的数据,并对这部分数据做预计算处理
- 将预计算的结果封装成为一个新的Segment,并将相应的信息保存到元数据和存储引擎中。一般来说,增量部分的起始时间等于Cube中最后一个Segment的结束时间。
增量Cube的创建
创建增量Cube的过程和创建普通Cube的过程基本类似,只是增量Cube会有一些额外的配置要求
1、配置Model
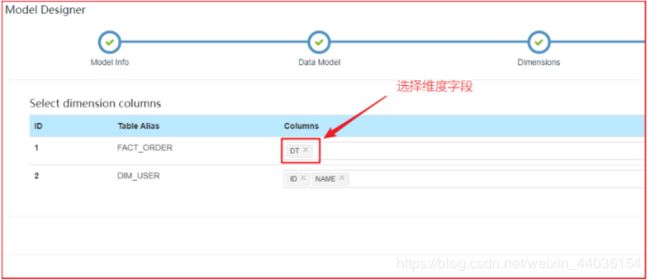
增量构建的Cube需要指定分割时间列。例如:将日期分区字段添加到维度列中
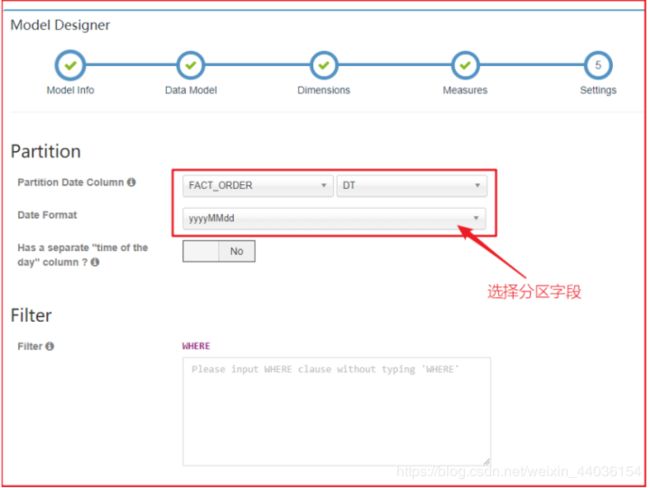
在设置中,配置分区列,并指定日期格式
注意事项
- 注意构建Cube时,选择的分区时间为,起始时间(包含)、结束时间(不保存),对应了从Hive从获取数据源的条件
INSERT OVERWRITE TABLE `kylin_intermediate_cube_order_1582ee64_45f9_cf22_bef2_e0b455efc284` SELECT
`FACT_ORDER`.`DT` as `FACT_ORDER_DT`
,`FACT_ORDER`.`USER_ID` as `FACT_ORDER_USER_ID`
,`FACT_ORDER`.`PRICE` as `FACT_ORDER_PRICE`
FROM `ITCAST_KYLIN_DW`.`FACT_ORDER` as `FACT_ORDER`
INNER JOIN `ITCAST_KYLIN_DW`.`DIM_USER` as `DIM_USER`
ON `FACT_ORDER`.`USER_ID` = `DIM_USER`.`ID`
WHERE 1=1 AND (`FACT_ORDER`.`DT` >= '20191011' AND `FACT_ORDER`.`DT` < '20191012');2、参看Segment
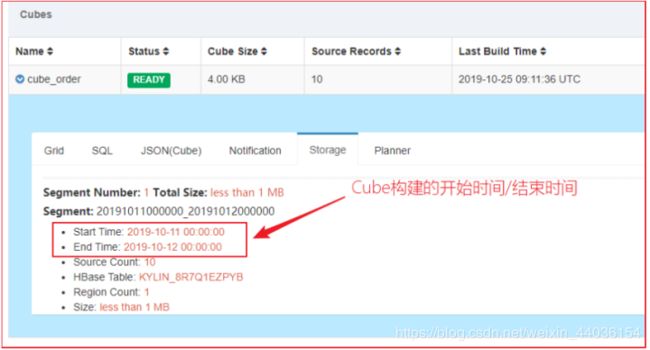
3、构建 20191012、20191013的Cube数据
INSERT OVERWRITE TABLE `kylin_intermediate_cube_order_16b6b739_cf24_fa63_c9bb_f8932b8c5d15` SELECT
`FACT_ORDER`.`DT` as `FACT_ORDER_DT`
,`FACT_ORDER`.`USER_ID` as `FACT_ORDER_USER_ID`
,`FACT_ORDER`.`PRICE` as `FACT_ORDER_PRICE`
FROM `ITCAST_KYLIN_DW`.`FACT_ORDER` as `FACT_ORDER`
INNER JOIN `ITCAST_KYLIN_DW`.`DIM_USER` as `DIM_USER`
ON `FACT_ORDER`.`USER_ID` = `DIM_USER`.`ID`
WHERE 1=1 AND (`FACT_ORDER`.`DT` >= '20191012' AND `FACT_ORDER`.`DT` < '20191013');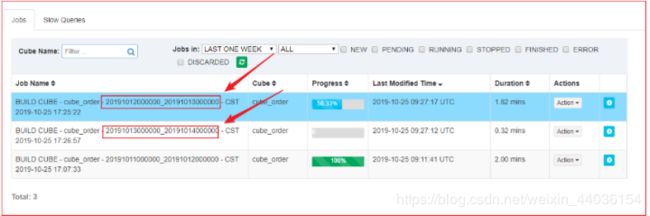
4、查看增量构建Cube对应的Segment

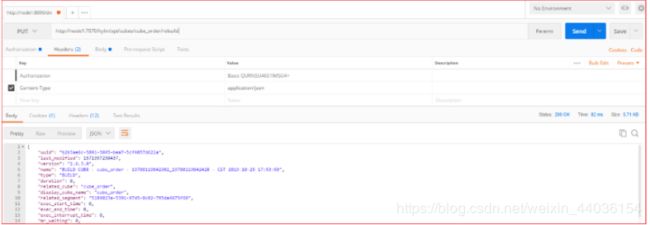
REST API触发增量构建
在Web GUI上进行的所有操作,其背后调用的都是同一套Rest API。将来可以SHELL脚本调度REST API触发构建。
| 属性 |
值 |
| URL |
http://node1:7070/kylin/api/cubes/{Cube名称}/rebuild |
| 请求方式 |
PUT |
| RequestBody(JSON字符串) |
{"startTime":时间戳, "endTime": "时间戳", "buildType": "BUILD/MERGE/REFRESH"} |
注意:
- Kylin中Cube构建的时间采用CST(北京时间),而REST提交的时间采用的是UTC(世界标准时间)
- CST = UTC + 8
- startTime、endTime提交到Kylin,应该 +8 个小时
参考JSON:
{
"startTime": "1570838400000",
"endTime": "1570924800000",
"buildType": "BUILD"
}时间戳转换工具:
http://tool.chinaz.com/Tools/unixtime.aspx
Cube碎片管理
增量构建的问题
日积月累,增量构建的Cube中的Segment越来越多,该Cube的查询性能也会越来越慢,因为需要在单点的查询引擎中完成越来越多的运行时聚合。为了保持查询性能:
- 需要定期地将某些Segment合并在一起
- 或者让Cube根据Segment保留策略自动地淘汰那些不会再被查询到的陈旧Segment
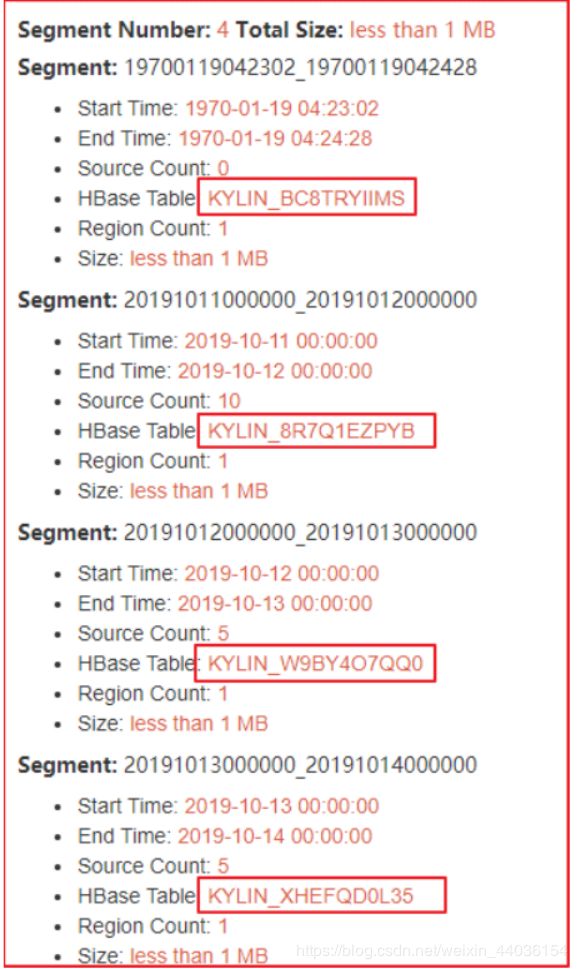
管理Cube碎片
上述案例,每天都会生成一个Segment,对应就是HBase中的一张表。增量构建的Cube每天都可能会有新的增量。这样的Cube中最终可能包含上百个Segment,这将会导致Kylin性能受到严重的影响。
- 从执行引擎的角度来说,运行时的查询引擎需要聚合多个Segment的结果才能返回正确的查询结果
- 从存储引擎的角度来说,大量的Segment会带来大量的文件,给存储空间的多个模块带来巨大的压力,例如Zookeeper、HDFS Namenode等
因此,有必要采取措施控制Cube中Segment的数量。
手动触发合并Segment
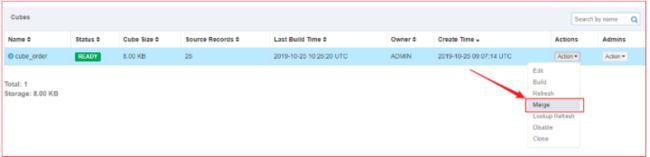
Kylin提供了一种简单的机制用于控制Cube中Segment的数量:合并Segments。在Web GUI中选中需要进行Segments合并的Cube,
操作步骤:
1、单击Action→Merge
2、选中需要合并的Segment,可以同时合并多个Segment,但是这些Segment必须是连续的
单击提交后系统会提交一个类型为“MERGE”的构建任务,它以选中的Segment中的数据作为输入,将这些Segment的数据合并封装成为一个新的Segment。新的Segment的起始时间为选中的最早的Segment的起始时间,它的结束时间为选中的最晚的Segment的结束时间。

注意事项
- 在MERGE类型的构建完成之前,系统将不允许提交这个Cube上任何类型的其他构建任务
- 在MERGE构建结束之前,所有选中用来合并的Segment仍然处于可用的状态
- 当MERGE构建结束的时候,系统将选中合并的Segment替换为新的Segment,而被替换下的Segment等待将被垃圾回收和清理,以节省系统资源
自动合并
手动维护Segment很繁琐,人工成本很高,Kylin中是可以支持自动合并Segment。
在Cube Designer的“Refresh Settings”的页面中有:
- Auto Merge Thresholds
- Retention Threshold

两个设置项可以用来帮助管理Segment碎片。这两项设置搭配使用这两项设置可以大大减少对Segment进行管理的麻烦。
1、Auto Merge Thresholds
- 允许用户设置几个层级的时间阈值,层级越靠后,时间阈值就越大
- 每当Cube中有新的Segment状态变为 READY的时候,会自动触发一次系统自动合并
- 合并策略
达到了阈值就跳过,没有达到阈值就合并到这个阈值,没满足不合并。
-
- 尝试最大一级的时间阈值,例如:针对(7天、28天)层级的日志,先检查能否将连续的若干个Segment合并成为一个超过28天的大Segment
- 如果有个别的Segment的时间长度本身已经超过28天,系统会跳过Segment
- 如果满足条件的连续Segment还不能够累积超过28天,那么系统会使用下一个层级的时间阈值重复寻找
- 尝试最大一级的时间阈值,例如:针对(7天、28天)层级的日志,先检查能否将连续的若干个Segment合并成为一个超过28天的大Segment
示例1 - 理解Kylin自动合并策略
- 假设自动合并阈值设置为7天、28天
- 如果现在有A-H8个连续的Segment,它们的时间长度为28天(A)、7天(B)、1天(C)、1天(D)、1天(E)、1天(F)、1天(G)、1天(H)
- 此时,第9个Segment I加入,时间长度为1天。
自动合并策略为:
1、Kylin判断时候能将连续的Segment合并到28天这个阈值,由于Segment A已经超过28天,会被排除
2、剩下的连续Segment,所有时间加一起 B + C + D + E + F + G + H + I (7 + 1 + 1 + 1 + 1 + 1 + 1 + 1 = 14) < 28天,无法满足28天阈值,开始尝试7天阈值
3、跳过A(28)、B(7)均超过7天,排除
4、剩下的连续Segment,所有时间加一起 C + D + E + F + G + H + I(1 + 1 + 1 + 1 + 1 + 1 + 1 = 7)达到7天阈值,触发合并,提交Merge任务。并构建一个Segment X(7天)
5、合并后,Segment为:A(28天)、B(7天)、X(7天)
6、继续触发检查,A(28天)跳过,B + X(7 + 7 = 14)< 28天,不满足第一阈值,重新使用第二阈值触发
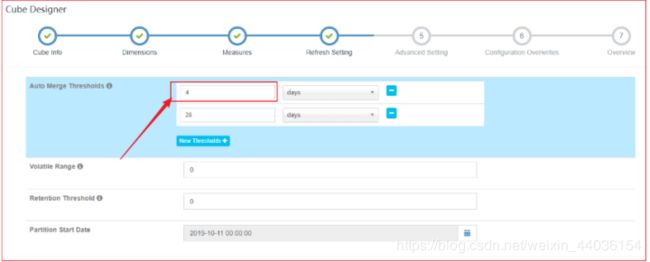
7、跳过B、X,尝试终止2、示例:配置自动合并4天的Segment
操作步骤:
1、配置自动合并阈值为(4、28)
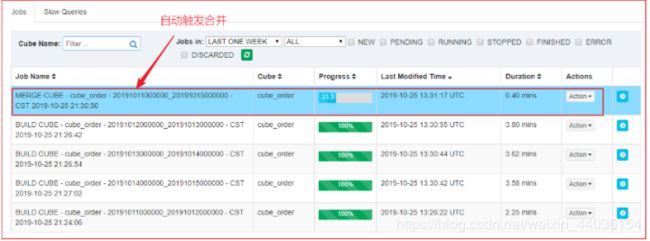
2、分别按照天构建分区Cube
3、自动触发合并Segment构建
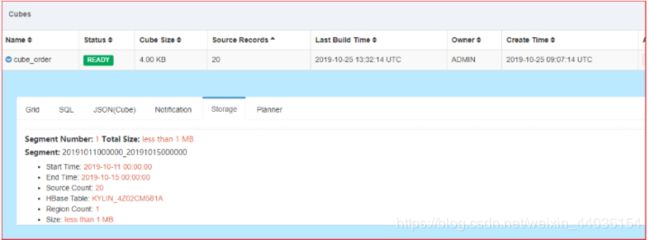
自动删除Segment
自动合并是将多个Segment合并为一个Segment,以达到清理碎片的目的。自动删除Segment则是及时清理不再使用的Segment。
在很多场景中,只会对过去一段时间内的数据进行查询,例如:
- 对于某个只显示过去1年数据的报表
- 支撑它的Cube其实只需要保留过去一年类的Segment即可
- 由于数据在Hive中已经存在备份,则无需在Kylin中备份超过一年的历史数据
可以将Retention Threshold设置为365。每当有新的Segment状态变为READY的时候,系统会检查每一个Segment。如果它的结束时间距离最晚的一个Segment的结束时间已经大于等于“Retention Threshold”,那么这个Segment将被视为无需保留。系统会自动地从Cube中删除这个Segment。

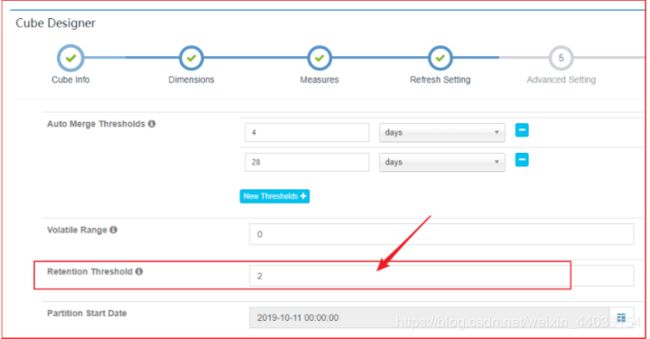
需求:
- 配置保留Segment为2天,分别构建增量Segment,测试Segment保留情况
操作步骤:
1、在Cube中设置Retension Threshold为2
2、重新构建Cube
3、测试超过指定保留时间的Segment,是否被自动移除