【简单总结】TextCNN的复习回顾
【简单总结】TextCNN
原文链接:Convolutional Neural Networks for Sentence Classification
1.简单介绍TextCNN
TextCNN模型是由 Yoon Kim提出的使用卷积神经网络来处理NLP问题的模型.相比较nlp中传统的rnn/lstm等模型,cnn能更加高效的提取重要特征,这些特征在分类中占据着重要位置.论文所提出的模型结构如下图所示:
:

与图像当中CNN的网络相比,textCNN 最大的不同便是在输入数据的不同:
-
图像是二维数据, 图像的卷积核是从左到右, 从上到下进行滑动来进行特征抽取。
-
自然语言是一维数据, 虽然经过word-embedding 生成了二维向量,但是对词向量做从左到右滑动来进行卷积没有意义. 比如 "今天" 对应的向量[0, 0, 0, 0, 1], 按窗口大小为 1* 2 从左到右滑动得到[0,0], [0,0], [0,0], [0, 1]这四个向量, 对应的都是"今天"这个词汇, 这种滑动没有帮助.
TextCNN的成功, 不是网络结构的成功, 而是通过引入已经训练好的词向量来在多个数据集上达到了超越benchmark 的表现,进一步证明了构造更好的embedding, 是提升nlp 各项任务的关键能力。
二. TextCNN 的优势
-
TextCNN最大优势网络结构简单 ,在模型网络结构如此简单的情况下,通过引入已经训练好的词向量依旧有很不错的效果,在多项数据数据集上超越benchmark。
-
网络结构简单导致参数数目少, 计算量少, 训练速度快,在单机单卡的v100机器上,训练165万数据, 迭代26万步,半个小时左右可以收敛。
三.TextCNN 的流程T
1.Word Embedding 分词构建词向量
如图二所示, textCNN 首先将 "今天天气很好,出来玩" 分词成"今天/天气/很好/,/出来/玩, 通过word2vec或者GLOV 等embedding 方式将每个词成映射成一个5维(维数可以自己指定)词向量, 如 "今天" -> [0,0,0,0,1], "天气" ->[0,0,0,1,0], "很好" ->[0,0,1,0,0]等等。
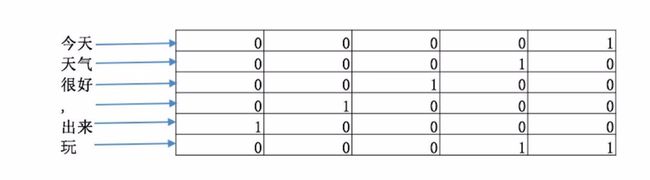
这样做的好处主要是将自然语言数值化,方便后续的处理。从这里也可以看出不同的映射方式对最后的结果是会产生巨大的影响, nlp 当中目前最火热的研究方向便是如何将自然语言映射成更好的词向量。我们构建完词向量后,将所有的词向量拼接起来构成一个6*5的二维矩阵,作为最初的输入
2. Convolution 卷积

在CNN 中常常会提到一个词channel, 图三 中 深红矩阵与 浅红矩阵 便构成了两个channel 统称一个卷积核, 从这个图中也可以看出每个channel 不必严格一样, 每个4*5 矩阵与输入矩阵做一次卷积操作得到一个feature map. 在计算机视觉中,由于彩色图像存在 R, G, B 三种颜色, 每个颜色便代表一种channel。
根据原论文作者的描述, 一开始引入channel 是希望防止过拟合(通过保证学习到的vectors 不要偏离输入太多)来在小数据集合获得比单channel更好的表现,后来发现其实直接使用正则化效果更好。
不过使用多channel 相比与单channel, 每个channel 可以使用不同的word embedding, 比如可以在no-static(梯度可以反向传播) 的channel 来fine tune 词向量,让词向量更加适用于当前的训练。
对于channel在textCNN 是否有用, 从论文的实验结果来看多channels并没有明显提升模型的分类能力, 七个数据集上的五个数据集 单channel 的textCNN 表现都要优于 多channels的textCNN。
3。TextCNN总结
TextCNN结构简单,精度比较高,只是速度相比没有Fasttext快,模型这种东西,没有绝对的好坏之说,所以根据不同数据集选择不同的模型,也是一门技术.