Python对文件(外存)和内存的操作
Python对文件[外存]和内存的操作
- 一,什么是文件
- 二,文件的类型
- 三,文本文件的编码与解码
- 四,二进制文件的优点
- 五,文件的打开(打开权限)
- 1.调用open()方法
- (1). 方法的含义
- (2).方法的常用形式
- (3).mode的几种模式
- 默认模式
- 读模式
- 写模式
- 追加模式
- 六,文件的读
- 七,文件的写
- 八,游标操作
- 九,关闭文件
- 十,序列化操作
- 十一,内存操作
- 1. StringIO
- 2. BytesIO
一,什么是文件
文件是指存放在外存储器(如磁盘)上的信息集合,使用文件可以将应用程序所处理的数据保存起来
详情请参考书籍:《操作系统》对文件的专业定义
二,文件的类型
二进制文件和文本文件:
二进制文件不可用文本工具打开,打开为乱码,且为不定长的,按照一定规则写入,无法直接操作
文本文件可以说是二进制文件的子集,以明文形式打开,它的发明是便于人们阅读以及编写文件,它采用字符编码:如GBK、UTF-8、Unicode以及ASCII等等,每个字符对应特定的二进制数值
详情可参考:
https://www.sohu.com/a/195421380_114819
https://baike.baidu.com/item/%E4%BA%8C%E8%BF%9B%E5%88%B6%E6%96%87%E4%BB%B6/996661?fr=aladdin
三,文本文件的编码与解码
计算机中存储的数据信息都是用二进制数表示的,我们在屏幕上看到的英文、汉字等字符是二进制数转换( 解码 )之后的结果
对于计算机领域来说,简单来讲,将字符用某种二进制数表示而存储在计算机中,称为‘编码’;将存储在计算机中的二进制数解析成字符,称为‘解码’
编码拥有不同的编码格式,比较常用的例如:
ASCII编码:American Standard Code for Information Interchange,美国信息交换标准代码)
7位表示一个字符,共128个字符
ASCII码扩展一个字符占一个字节( 8位 ),共256个字符
只能显示26个基本拉丁字母,阿拉伯数字和英式标点符号,而对其他语言无能为力。
关键点:
0~9:48~57
a~z:97~122
A~Z:65~90
GBK编码:(GBK即“国标”、“扩展”汉语拼音的第一个字母,英文名称:Chinese Internal Code Specification)
兼容ASCII码,且扩展中文字符编码
一个汉字占2字节
一个字母占1字节
Unicode编码:
为了防止不同国家使用不同编码方式而造成解码错误问题(出现乱码)
全世界所有字符编码的集合,每个符号都给予独一无二的编码,计算机只要支持这个字符集,就能显示所有字符了
所有语言字符统一用2字节表示
UTF-8编码:(可变长编码)
本着节约的精神,UTF-8编码把一个Unicode字符根据不同的字符编码成1~6个字节
英文字母占1个字节
汉字占3个字节
很生僻的字符会占4~6个字节
使用什么编码格式编码就使用什么解码格式解码,在解码的过程中,若使用了错误的或者不同的解码格式(如用GBK编码,而使用UTF-8解码),则会出现乱码!
详情可以参考:
https://blog.csdn.net/weiwenjuan0923/article/details/52713387
https://www.jianshu.com/p/8342c584fa41
四,二进制文件的优点
1.二进制文件节约空间,用一串小数来打比方:按一种数据类型float为4个字节来存储数据,而不是像文本文件每个字符不按类别、分别存储为一个字节来存储
2.二进制文件更加快捷,计算机直接用二进制处理数据
3.精确度高,不会造成有效位丢失
详情可参考:
http://www.cnblogs.com/flying-roc/articles/1798817.html
五,文件的打开(打开权限)
在磁盘上读写文件的功能都是由操作系统提供的,现代操作系统不允许普通的程序直接操作磁盘,所以,读写文件就是请求操作系统打开一个文件对象(通常称为文件描述符),然后,通过操作系统提供的接口从这个文件对象中读取数据(读文件),或者把数据写入这个文件对象(写文件)。
1.调用open()方法
(1). 方法的含义
用于打开一个文件,赋予适当操作权限(读写等),并返回文件对象
(2).方法的常用形式
open ( path, mode[ , enccoding=])
接收两个参数,path:文件的路径(同一目录下的文件只需要文件名),mode:文件打开模式,赋予的权限。encoding设置打开的二进制编码模式,默认为系统默认的编码模式(不确定系统的编码模式,最好自行指定)
(3).mode的几种模式
默认模式
path指定文件必须存在,否则报错
- open(path) – 默认拥有[ 读 ] 权限
默认模式 mode = ‘t’,默认为文本模式
读模式
path指定文件必须存在,否则报错
-
open(path, ’ r ') – 拥有[ 读 ] 权限
以只读的方式打开文件,文件的游标会放在文件的开头 -
open(path, ’ rb ') – 拥有[ 读 ] 权限
以二进制只读的方式打开文件,文件的游标会放在文件的开头。
一般用于非文本文件,如图片等。 -
open(path, ’ r+ ’ ) – 拥有[ 读,写 ] 权限
[ ‘+’ 说明:打开一个文件进行更新操作(变得可读可写)]
打开一个文件用于读写,文件游标会放在文件的开头
注意:
(1) 进行write()写操作时,不清空源文件内容,而是在写入时按字节进行覆盖

原 .txt文件:

改变后:(在utf-8编码的文件中,一个中文字符占3字节,一个半角英文字符占1字节,所以3个半角英文字符对应一个中文字符,一个一个对应,否则 .txt 文件会出错)

(2) 进行read()操作时,从头开始读,游标按字符为单位移动:

结果:
写模式
path指定文件可以不存在,不存在则会自动新建文件,不会报错
-
open(path, ’ w ’ ) – 拥有[ 写 ] 权限
以只写的形式打开文件,当文件存在时,清空原内容,重新开始写;当文件不存在时,创建新文件来写,文件的游标固然会放在文件的开头( 因为为文件为空 ) -
open(path, ‘wb’ ) – 拥有[ 写 ] 权限
以二进制形式只写形式打开文件,后续同上 -
open(path, ’ w+ ’ ) – 拥有[ 读,写 ] 权限
打开一个文件用于读写,后续同上
注意:
(1)以w+模式进行read()操作时,结果为空,因为每次打开文件都会先清空文件
(2)write()操作照常写入内容,不会执行清空原内容操作,清空操作是open(path, ‘w+’)操作执行造成的
追加模式
path指定文件可以不存在,不存在则创建新文件,不会报错
- open(path, ’ a ’ ) – 拥有[ 写 ] 权限
打开一个文件用于追加。若文件存在,则写入操作在原内容之后,游标在原内容结尾;若文件不存在,则新建文件开始写入,游标在开头 - open(path, ’ ab ’ ) – 拥有[ 写 ] 权限
以二进制格式打开文件进行追加。后续同上。 - open(path, ’ a+ ’ ) – 拥有[ 读,写 ] 权限
打开一个文件用于读写。后续同上。
注意:
a与a+write()操作无区别,但是a+拥有read()读权限操作,但是a没有
注意:
当open()模式包含二进制形式 ‘b’ 时,‘encoding=’参数不可设置,因为UTF-8和gbk为使文件以二进制编码形式打开,与b操作重复
六,文件的读
- file.read([size])
以文件所有内容整体为一个对象,按照文件内容形式 ( 有换行则换行,空格则空格,不会直接将内容拼接整行输出 ) 读取文件内容,size指定读取字符个数,默认读取全部内容
.py文件

.txt文件

输出:

- file.readline([size])
以文件的第一行为对象输出,默认输出一行,其余同上 - file.readlines()
文件每一行以字符串形式,组成一个列表的元素

- next(file)
迭代文件的每一行
.py文件
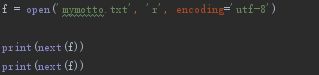
输出:
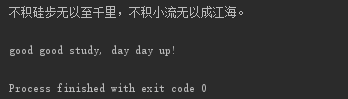
七,文件的写
- f.write(str)
直接将str写入文件 - f.writelines()
向文件写入一个序列字符串列表,如果需要换行则要自己加入每行的换行符。 - f.flush()
刷新文件内部缓冲,直接把内部缓冲区的数据立刻写入文件,而不是被动等待输出缓冲区写入
八,游标操作
-
file.tell()
返回游标当前位置,以字节为单位 -
seek(offset[,whence])
使游标偏移,按字节移动offset个字节
whence:3个值类型:0游标从文件开头算起,1从当前位置算起,2从文件末尾算起
.py文件
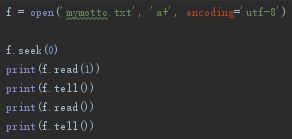
.txt文件

输出:

九,关闭文件
- 手动关闭 file.close()
每执行完一个 open() 操作就加上一个 close() 操作
出错可能导致文件没正常关闭,而使数据没写入外存而丢失数据!
文件执行写操作write()时,操作系统不会直接将数据立即写入外存,而是先放在内存缓存起来,空闲时再慢慢写入。只有调用close()方法时,操作系统才保证把没有写入的数据全部写入磁盘。忘记调用close()的后果是数据可能只写了一部分到磁盘,剩下的丢失了。
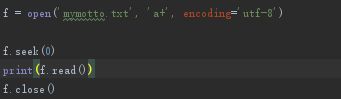
- 自动关闭 使用with语句
格式如下,语句执行完会自动执行close()操作关闭文件,使用 with 进行文件操作是个好习惯!
出错也能正常关闭文件

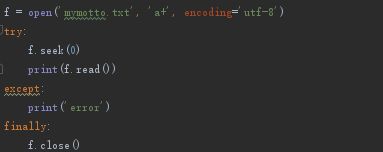
- 套用异常处理关闭 try-except-finally
出错也能正常关闭文件,类似于上面的 with 操作
十,序列化操作
注意:在程序的运行过程中,所有的变量都是在外存中的
序列化:把变量 ( 数据 ) 从内存中变成可存储(把内存中的各种数据类型的数据保存到本地磁盘持久化)或传输(把内存中的各种数据类型的数据通过网络传送给其它机器或客户端)的过程
序列化操作是一种另类的读写操作,它操作的对象为变量,它可将变量序列化后写入到一个文件或者从一个文件中反序列化读取数据(调用load()与dump()),类似于文件操作,但不同的是:
- 它还可以将变量序列化为bytes对象进行返回,读取则将序列化后的bytes对象进行反序列化转化为变量进行返回(调用loads()和dumps())
- 它使用二进制的方式读取,而不是类似文本文件采用二进制编码
-
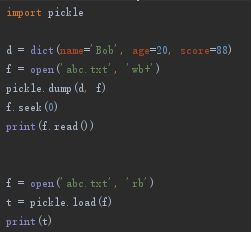
dump(seq, file) 操作
将seq数据序列 序列化 到file文件里 -
load(file) 操作
将序列化数据 反序列化 读取出来

-
dumps(seq) 操作
将seq数据序列 序列化 直接返回二进制数值 -
loads(file) 操作
将序列化数据 反序列化 使二进制数据转化成普通数据类型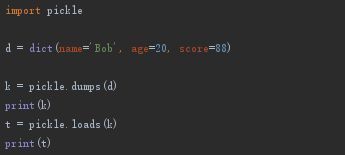
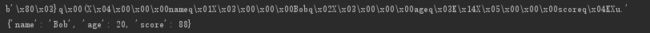
注意:
dump与load为一对操作
dumps与loads为一对操作
不可混用
详情请参考:
https://www.liaoxuefeng.com/wiki/001374738125095c955c1e6d8bb493182103fac9270762a000/00138683221577998e407bb309542d9b6a68d9276bc3dbe000
https://www.cnblogs.com/yyds/p/6563608.html
十一,内存操作
有些时候,数据读取不一定是在文件上,也可在内存中读取
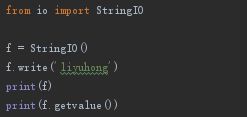
1. StringIO
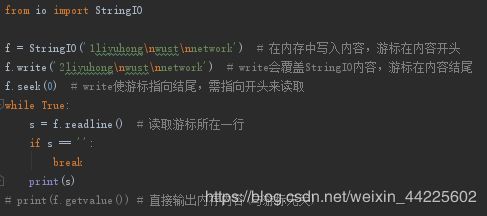
在内存中读写str,就要把str写入StringIO,需要创建StringIO对象实例,像写文件一样写入即可
进阶:
2. BytesIO
在内存中读写二进制数据,就要把二进制数据写入BytesIO,需要创建BytesIO实例
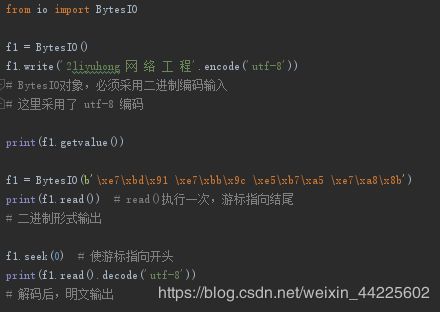
详情请参考:
https://www.cnblogs.com/284628487a/p/5590692.html