Ceph OSDMap 机制浅析
OSDMap 机制是 Ceph 架构中非常重要的部分,PG 在 OSD 上的分布和监控由 OSDMap 机制执行。OSDMap 机制和 CRUSH 算法一起构成了 Ceph 分布式架构的基石。
OSDMap 机制主要包括如下3个方面:
1、Monitor 监控 OSDMap 数据,包括 Pool 集合,副本数,PG 数量,OSD 集合和 OSD 状态。
2、OSD 向 Monitor 汇报自身状态,以及监控和汇报 Peer OSD 的状态。
3、OSD 监控分配到其上的 PG , 包括新建 PG , 迁移 PG , 删除 PG 。
在整个 OSDMap 机制中,OSD充分信任 Monitor, 认为其维护的 OSDMap 数据绝对正确,OSD 对 PG 采取的所有动作都基于 OSDMap 数据,也就是说 Monitor 指挥 OSD 如何进行 PG 分布。
在 OSDMap 数据中 Pool 集合,副本数,PG 数量,OSD 集合这 4 项由运维人员来指定,虽然 OSD 的状态也可以由运维人员进行更改,但是实际运行的 Ceph 集群 A 中,从时间分布来看,运维人员对 Ceph 集群进行介入的时间占比很小,因此 OSD 的故障(OSD 状态)才是 Monitor 监控的主要目标。
OSD 故障监控由 Monitor 和 OSD 共同完成,在 Monitor 端,通过名为 OSDMonitor 的 PaxosService 线程实时的监控 OSD 发来的汇报数据(当然,也监控运维人员对 OSDMap 数据进行的操作)。在 OSD 端,运行一个 Tick 线程,一方面周期性的向 Monitor 汇报自身状态;另外一方面,OSD 针对 Peer OSD 进行 Heartbeat 监控,如果发现 Peer OSD 故障,及时向 Monitor 进行反馈。具体的 OSD 故障监控细节本文不做分析。
OSDMap 机制中的第1点和第2点比较容易理解,下面本文主要针对第3点进行详细分析。

如上图所示,在3个 OSD 的 Ceph 集群中,Pool 的副本数为3,某个 PG 的 Primary OSD 为 OSD0, 当 Monitor 检测到 3 个 OSD 中的任何一个 OSD 故障,则发送最新的 OSDMap 数据到剩余的 2 个 OSD 上,通知其进行相应的处理。

如上图所示,OSD 收到 MOSDMap 后,主要进行3个方面的处理
ObjectStore::Transaction::write(coll_t::meta()) 更新 OSDMap 到磁盘,保存在目录 /var/lib/ceph/OSD/ceph-
OSD::consume_map() 进行 PG 处理,包括删除 Pool 不存在的 PG; 更新 PG epoch(OSDmap epoch) 到磁盘(LevelDB); 产生 AdvMap 和 ActMap 事件,触发 PG 的状态机 state_machine 进行状态更新。
OSD::activate_map() 根据需要决定是否启动 recovery_tp 线程池进行 PG 恢复。
在OSD端,PG 负责 I/O 的处理,因此 PG 的状态直接影响着 I/O,而 pgstate_machine 就是 PG 状态的控制机制,但里面的状态转换十分的复杂,这里不做具体分析。
下面开始分析 PG 的创建,删除,迁移
PG 的创建由运维人员触发,在新建 Pool 时指定 PG 的数量,或增加已有的 Pool 的 PG 数量,这时 OSDMonitor 监控到 OSDMap 发生变化,发送最新的 MOSDMap 到所有的 OSD。
在 PG 对应的一组 OSD 上,OSD::handle_pg_create() 函数在磁盘上创建 PG 目录,写入 PG 的元数据,更新 Heartbeat Peers 等操作。
PG 的删除同样由运维人员触发,OSDMonitor 发送 MOSDMap 到 OSD, 在 PG 对应的一组 OSD 上,OSD::handle_PG _remove() 函数负责从磁盘上删除PG 所在的目录,并从 PGMap 中删除 PG ,删除 PG 的元数据等操作。
PG 迁移较为复杂,涉及到两个OSD与monitor的协同处理。例如,向已有3个OSD的集群中新加入OSD3,导致 CRUSH 重新分布 PG , 某个 PG 的分配变化结果为 [0, 1, 2 ] -> [3, 1, 2]。当然,CRUSH 的分配具有随机性,不同的 PG 中,OSD3 既可能成为 Primary OSD,也可能成为 Replicate OSD, 这里取 OSD3 作为 Primary OSD为例。
新加入的OSD3取代了原有的 OSD0 成为 Primary OSD, 由于 OSD3 上未创建 PG , 不存在数据,那么 PG 上的 I/O 无法进行,因此,这里引入 PG Temp 机制,即 OSD3 向 Monitor 发送 MOSDPG Temp,把 Primary OSD 指定为OSD1, 因为 OSD1 上保存了 PG 的数据,Client 发送到 PG 的请求都被转发到了 OSD1;与此同时,OSD1 向 OSD3 发送 PG 的数据,直到 PG 数据复制完成,OSD1 将 Primary OSD 的角色交还给 OSD3,Client 的 I/O 请求直接发送的 OSD3,这样就完成了 PG 的迁移。整个过程如下图所示。
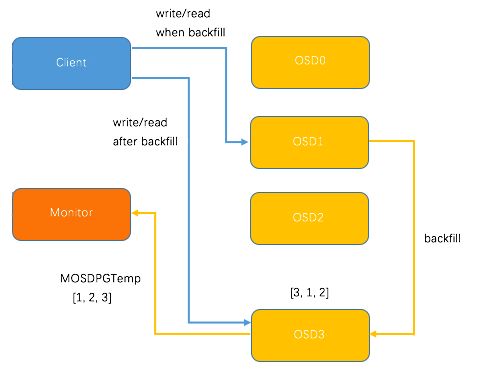
另外一种 PG 的迁移情景是 OSD3 作为 Replicate OSD 时,由 Primay OSD 向 OSD3 进行 PG 数据迁移,比上述 PG 迁移过程更为简单,这里不再详述。
本文从 PG 的视角阐述了 OSDMap 机制的基本原理,描述了 Monitor, OSD, PG 三者之间的关联。 在实际运维中,我们常常对于 OSD 状态和数量的变化引起的 PG 状态的变化感到疑惑,希望本文能够对解决的 PG 状态问题带来启发。