【玩转华为云】手把手教你用Modelarts基于YOLO V3算法实现物体检测

本篇推文共计2000个字,阅读时间约3分钟。
华为云—华为公司倾力打造的云战略品牌,2011年成立,致力于为全球客户提供领先的公有云服务,包含弹性云服务器、云数据库、云安全等云计算服务,软件开发服务,面向企业的大数据和人工智能服务,以及场景化的解决方案。

华为云用在线的方式将华为30多年在ICT基础设施领域的技术积累和产品解决方案开放给客户,致力于提供稳定可靠、安全可信、可持续创新的云服务,做智能世界的“黑土地”,推进实现“用得起、用得好、用得放心”的普惠AI。华为云作为底座,为华为全栈全场景AI战略提供强大的算力平台和更易用的开发平台。

华为云官方网站
ModelArts是华为云产品中面向开发者的一站式AI开发平台,为机器学习与深度学习提供海量数据预处理及半自动化标注、大规模分布式Training、自动化模型生成,及端-边-云模型按需部署能力,帮助用户快速创建和部署模型,管理全周期AI工作流。

华为云官方网站

基于YOLO V3算法实现物体检测
本实验将我们将聚焦于用YOLO V3算法实现物体检测,在ModelArts的Notebook开发环境中实现用YOLO V3算法构建一个物体检测的神经网络模型,并在该环境中实现对物体检测神经网络模型的训练与测试,最终达到实现物体检测的实验目的。

基于YOLO V3算法实现物体检测
实验流程
1.准备实验环境与创建开发环境
2.下载数据与训练代码
3.准备数据
4.Yolo_v3模型训练
5.Yolo_v3模型测试
1
1.1进入ModelArts
首先需要进入华为云Modelarts主页,输入自己的账号密码:
https://www.huaweicloud.com/product/modelarts.html
点击进入“进入控制台”
在左侧开发环境处,点击Notebook:
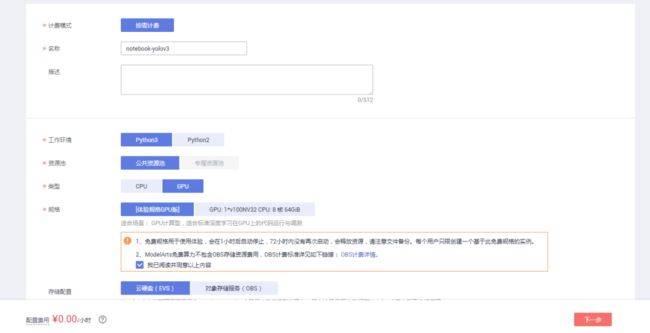
点击“创建”,填写配置信息:
名称:自定义(此处我设置的是notebook-yolov3)
工作环境:Python3
资源池:公共资源池
类型:GPU
规格:体验规格GPU(这样就不要花费)
存储配置:云硬盘
这里我说说我对云硬盘与对象存储服务的理解:
云硬盘对应的是云服务器,就如同电脑的自带硬盘,存储在云硬盘的数据可以随时的在云端查看。
对象存储服务就如同移动硬盘,可以随时做资料备份。
按“下一步”确认信息无误,点击“提交”即可:
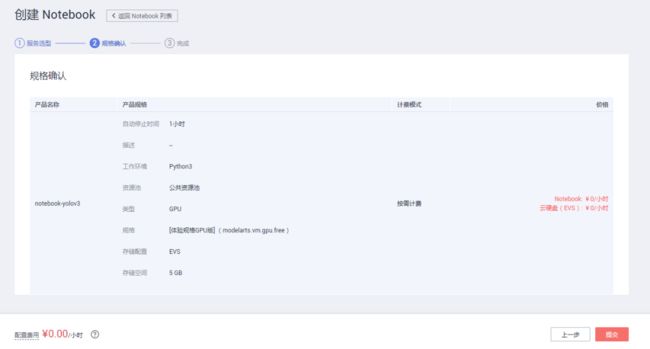
即可完成创建:
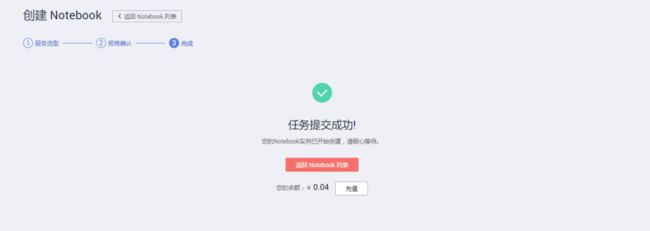
点击“返回Notebook列表”,即看到正在运行的Notebook环境:
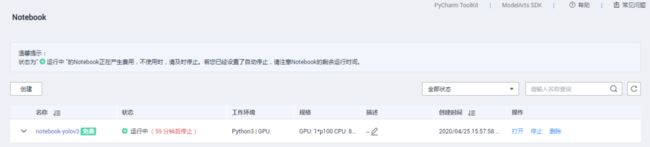
点击进入创建的notebook-yolov3中:

点击选择右侧的“New”
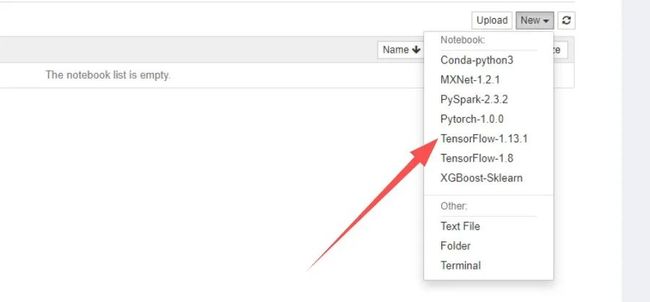
点击选择TensorFlow 1.13.1开发环境后,进入下面的页面:

输入下面代码后,点击“Run”进行测试:
print("Hello world!")
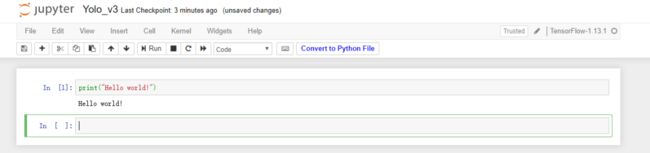
成功输出“Hello world!”,说明环境配置正确
2
2.数据和代码下载
点击“Run”运行下面代码,进行实验代码和实验数据的下载和解压:
from modelarts.session import Session
sess = Session()
if sess.region_name == 'cn-north-1':
bucket_path="modelarts-labs/notebook/DL_object_detection_yolo/yolov3.tar.gz"
elif sess.region_name == 'cn-north-4':
bucket_path="modelarts-labs-bj4/notebook/DL_object_detection_yolo/yolov3.tar.gz"
else:
print("请更换地区到北京一或北京四")
sess.download_data(bucket_path=bucket_path, path="./yolov3.tar.gz")
# 解压文件
!tar -xf ./yolov3.tar.gz
# 清理压缩包
!rm -r ./yolov3.tar.gz本实验案例使用coco数据集,共80个类别:
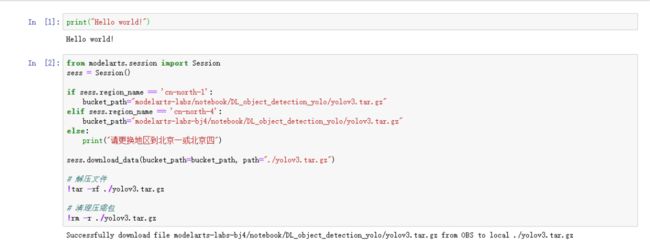
下载后的代码和数据保存在了之前设置的云硬盘(EVS)中
这里是已经下载好的文件目录:
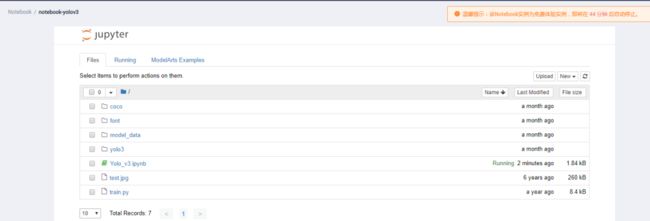
3
3.准备数据
运行以下代码,进行文件路径定义:
from train import get_classes, get_anchors
# 数据文件路径
data_path = "./coco/coco_data"
# coco类型定义文件存储位置
classes_path = './model_data/coco_classes.txt'
# coco数据anchor值文件存储位置
anchors_path = './model_data/yolo_anchors.txt'
# coco数据标注信息文件存储位置
annotation_path = './coco/coco_train.txt'
# 预训练权重文件存储位置
weights_path = "./model_data/yolo.h5"
# 模型文件存储位置
save_path = "./result/models/"
classes = get_classes(classes_path)
anchors = get_anchors(anchors_path)
# 获取类型数量和anchor数量变量
num_classes = len(classes)
num_anchors = len(anchors)运行代码后的输出结果:
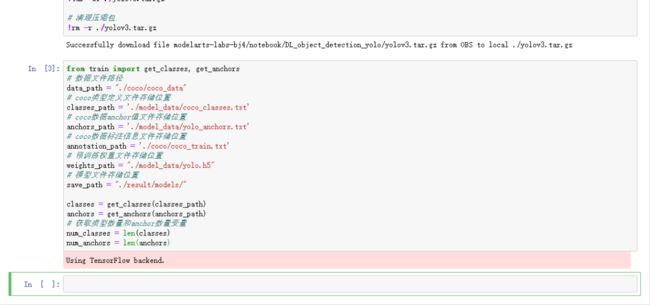
读取标注数据:
import numpy as np
# 训练集与验证集划分比例
val_split = 0.1
with open(annotation_path) as f:
lines = f.readlines()
np.random.seed(10101)
np.random.shuffle(lines)
np.random.seed(None)
num_val = int(len(lines)*val_split)
num_train = len(lines) - num_val运行界面:
以下代码是数据读取函数,构建数据生成器。每次读取一个批次的数据至内存训练,并做数据增强:
def data_generator(annotation_lines, batch_size, input_shape, data_path,anchors, num_classes):
n = len(annotation_lines)
i = 0
while True:
image_data = []
box_data = []
for b in range(batch_size):
if i==0:
np.random.shuffle(annotation_lines)
image, box = get_random_data(annotation_lines[i], input_shape, data_path,random=True) # 随机挑选一个批次的数据
image_data.append(image)
box_data.append(box)
i = (i+1) % n
image_data = np.array(image_data)
box_data = np.array(box_data)
y_true = preprocess_true_boxes(box_data, input_shape, anchors, num_classes) # 对标注框预处理,过滤异常标注框
yield [image_data, *y_true], np.zeros(batch_size)
def data_generator_wrapper(annotation_lines, batch_size, input_shape, data_path,anchors, num_classes):
n = len(annotation_lines)
if n==0 or batch_size<=0: return None
return data_generator(annotation_lines, batch_size, input_shape, data_path,anchors, num_classes)运行界面:
4
4.Yolov3模型训练
本实验使用的是Keras深度学习框架搭建YOLOv3神经网络模型。
在实验中可以进入Notebook的管理控制台查看相应的源码实现。
构建神经网络:
import keras.backend as K
from yolo3.model import preprocess_true_boxes, yolo_body, yolo_loss
from keras.layers import Input, Lambda
from keras.models import Model
# 初始化session
K.clear_session()
# 图像输入尺寸
input_shape = (416, 416)
image_input = Input(shape=(None, None, 3))
h, w = input_shape
# 设置多尺度检测的下采样尺寸
y_true = [Input(shape=(h//{0:32, 1:16, 2:8}[l], w//{0:32, 1:16, 2:8}[l], num_anchors//3, num_classes+5))
for l in range(3)]
# 构建YOLO模型结构
model_body = yolo_body(image_input, num_anchors//3, num_classes)
# 将YOLO权重文件加载进来,如果希望不加载预训练权重,从头开始训练的话,可以删除这句代码
model_body.load_weights(weights_path, by_name=True, skip_mismatch=True)
# 定义YOLO损失函数
model_loss = Lambda(yolo_loss, output_shape=(1,), name='yolo_loss',
arguments={'anchors': anchors, 'num_classes': num_classes, 'ignore_thresh': 0.5})([*model_body.output, *y_true])
# 构建Model,为训练做准备
model = Model([model_body.input, *y_true], model_loss)点击“Run”,运行界面如下:

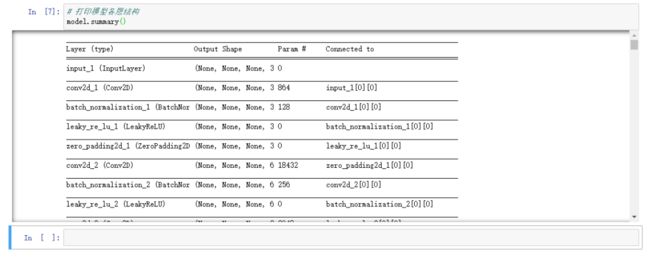
可通过如下代码,打印模型各层结构,带您了解模型细节:
# 打印模型各层结构
model.summary()运行代码如下:
训练回调函数定义:
from keras.callbacks import ReduceLROnPlateau, EarlyStopping
# 定义回调方法
reduce_lr = ReduceLROnPlateau(monitor='val_loss', factor=0.1, patience=3, verbose=1) # 学习率衰减策略
early_stopping = EarlyStopping(monitor='val_loss', min_delta=0, patience=10, verbose=1) # 早停策略运行代码后如下:

运行如下代码,点击“Run”,即可开始训练:
from keras.optimizers import Adam
from yolo3.utils import get_random_data
# 设置所有的层可训练
for i in range(len(model.layers)):
model.layers[i].trainable = True
# 选择Adam优化器,设置学习率
learning_rate = 1e-4
model.compile(optimizer=Adam(lr=learning_rate), loss={'yolo_loss': lambda y_true, y_pred: y_pred})
# 设置批大小和训练轮数
batch_size = 16
max_epochs = 2
print('Train on {} samples, val on {} samples, with batch size {}.'.format(num_train, num_val, batch_size))
# 开始训练
model.fit_generator(data_generator_wrapper(lines[:num_train], batch_size, input_shape, data_path,anchors, num_classes),
steps_per_epoch=max(1, num_train//batch_size),
validation_data=data_generator_wrapper(lines[num_train:], batch_size, input_shape, data_path,anchors, num_classes),
validation_steps=max(1, num_val//batch_size),
epochs=max_epochs,
initial_epoch=0,
callbacks=[reduce_lr, early_stopping])本次实验设置的batch_size = 16,max_epochs = 2
如何特殊需求的用户,可以在此基础上进行修改:
训练好了后结果如下:

5
5.Yolov3模型测试
运行以下代码,点击“Run”,打开一张测试图片:
from PIL import Image
import numpy as np
# 测试文件路径
test_file_path = './test.jpg'
# 打开测试文件
image = Image.open(test_file_path)
image_ori = np.array(image)
image_ori.shape运行界面如下:

继续输入“image”可看到打开的是哪张图片:
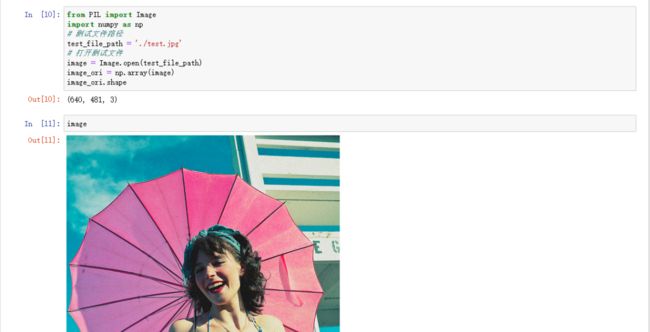
进行图片预处理操作:
from yolo3.utils import letterbox_image
new_image_size = (image.width - (image.width % 32), image.height - (image.height % 32))
boxed_image = letterbox_image(image, new_image_size)
image_data = np.array(boxed_image, dtype='float32')
image_data /= 255.
image_data = np.expand_dims(image_data, 0)
image_data.shape运行结果如下所示:

继续输入代码:
import keras.backend as K
sess = K.get_session()运行结果如下;

运行以下代码,构建模型:
from yolo3.model import yolo_body
from keras.layers import Input
# coco数据anchor值文件存储位置
anchor_path = "./model_data/yolo_anchors.txt"
with open(anchor_path) as f:
anchors = f.readline()
anchors = [float(x) for x in anchors.split(',')]
anchors = np.array(anchors).reshape(-1, 2)
yolo_model = yolo_body(Input(shape=(None,None,3)), len(anchors)//3, num_classes)运行界面如下:
加载模型权重,或将模型路径替换成上一步训练得出的模型路径:
# 模型权重存储路径
weights_path = "./model_data/yolo.h5"
yolo_model.load_weights(weights_path)运行界面如下:

定义IOU以及score:
IOU:将交并比大于IOU的边界框作为冗余框去除
score:将预测分数大于score的边界框筛选出来
iou = 0.45
score = 0.8运行界面如下:

构建输出[boxes, scores, classes]:
from yolo3.model import yolo_eval
input_image_shape = K.placeholder(shape=(2, ))
boxes, scores, classes = yolo_eval(
yolo_model.output,
anchors,
num_classes,
input_image_shape,
score_threshold=score,
iou_threshold=iou)运行界面如下:
依次输入下面的代码段,进行预测:
代码1:
out_boxes, out_scores, out_classes = sess.run(
[boxes, scores, classes],
feed_dict={
yolo_model.input: image_data,
input_image_shape: [image.size[1], image.size[0]],
K.learning_phase(): 0
})代码2:
class_coco = get_classes(classes_path)
out_coco = []
for i in out_classes:
out_coco.append(class_coco[i])代码3:
print(out_boxes)
print(out_scores)
print(out_coco)运行结果如下:

将预测结果绘制在图片上:
from PIL import Image, ImageFont, ImageDraw
font = ImageFont.truetype(font='font/FiraMono-Medium.otf',
size=np.floor(3e-2 * image.size[1] + 0.5).astype('int32'))
thickness = (image.size[0] + image.size[1]) // 300
for i, c in reversed(list(enumerate(out_coco))):
predicted_class = c
box = out_boxes[i]
score = out_scores[i]
label = '{} {:.2f}'.format(predicted_class, score)
draw = ImageDraw.Draw(image)
label_size = draw.textsize(label, font)
top, left, bottom, right = box
top = max(0, np.floor(top + 0.5).astype('int32'))
left = max(0, np.floor(left + 0.5).astype('int32'))
bottom = min(image.size[1], np.floor(bottom + 0.5).astype('int32'))
right = min(image.size[0], np.floor(right + 0.5).astype('int32'))
print(label, (left, top), (right, bottom))
if top - label_size[1] >= 0:
text_origin = np.array([left, top - label_size[1]])
else:
text_origin = np.array([left, top + 1])
for i in range(thickness):
draw.rectangle(
[left + i, top + i, right - i, bottom - i],
outline=225)
draw.rectangle(
[tuple(text_origin), tuple(text_origin + label_size)],
fill=225)
draw.text(text_origin, label, fill=(0, 0, 0), font=font)
del draw运行代码后页面如下:
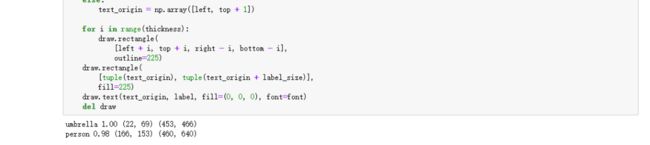
输入“image”可以看到标注好的图片:
测试1
利用步骤5进行其它图片测试:

测试2

测试3

测试4

测试5
至此实验全部完成。
大家使用的云端资源记得全部删除如ModelArts创建的Notebook开发环境需要删除,并停用访问密钥,以免造成不必要的花费。
通过对实验结果的比对,可以看出利用
[华为云ModelArts]训练出来的物体检测模型是很棒的,六个字总结就是-高效,快捷,省心。
如您对本系列的实验感兴趣,点击底部阅读原文可体验于4月20日开始的
[华为云开发者青年班第二期 AI实战营],现进行到打卡第五天,每天一天实战演练,让你足不出户免费体验[华为云]高级技术专家亲自指导,学、练、赛的全流程内容,让你轻松Get AI技能。
心动不如行动,快来学习吧。

正因我们国家有许多像华为这样强大的民族企业在国家背后默默做支撑,做奉献。我们国家才能屹立于世界民族之林。
华为,中国骄傲!中华有为!

往期回顾
【玩转华为云】Modelarts基于海量数据训练猫狗分类模型
【玩转华为云】Modelarts实现猫狗数据集的智能标注
【玩转华为云】ModelArts基于海量数据训练美食分类模型
【玩转华为云】ModelArts零代码开发美食分类模型
【玩转华为云】ModelArts实现垃圾的智能分类
【玩转华为云】ModelArts实现数据集的图片标注
【玩转华为云】ModelArts实现一键目标物体检测
【玩转华为云】ModelArts实现一键行人车辆检测
【Python3+OpenCV】实现图像处理—灰度变换篇
【Python3+OpenCV】实现图像处理—基本操作篇
武汉加油,中国加油!
欢迎各位读者在下方进行提问留言
☆ END ☆

你与世界
只差一个
公众号
扫描上方二维码,获取千元“编程学习资料”大礼包