C语言:探讨一下结构体大小及其成员分布
基础成员大小
在不同机器上,编译器处理基础类型占用内存字节不尽相同,如表所示:

更正: 评论区指出LP32和ILP32之间的区别。上面表格是常用的系统环境下的数据类型,但是不同的系统环境有不同的数据模型,见下表。(注:后续的测试都是建立在ILP32数据模型的,其实想知道数据类型大小可以直接使用操作符sizeof即可。)

为什么要内存对齐?
简单YY一下,CPU不是一个字节一个字节的访问内存的,而是按n(>1)个字节为整体访问,称为内存访问粒度,为的是提高CPU执行效率,也就是我们经常听到的32位、64位CPU。举个例子,当要访问一个4字节的int型变量数据,32位的CPU以4字节为单位访问一次内存即可(事实上CPU访问一个地址时会把该地址附近的内容一起拷贝到比内存速度快得多的内部高速缓存cache中,而不是每次访问都需要读取一次内存,CPU大部分时间是与高速缓存cahce交互),而当int型数据放在奇数地址处,它必定会占用到下一个“4字节”的地址区间,而CPU以4个字节作为整体对齐地访问就需要访问2次,所以如果将数据进行内存对齐就有利于提高CPU的效率,是空间换时间的一种方式。内存对齐是编译器做的事情,但我们使用内存的时候也最好知道内存对齐有可能会影响到数据的正确性,尤其是在接下来探讨的联合体与结构体成员的内存分布。
联合体的大小
联合体也称共用体,顾名思义,它的大小不是所有成员的和,而是满足(或者说大于等于)最大成员的大小且满足最宽基础类型成员大小的整数倍。
例如32位机器中以下类型只占用4个字节而不是5个字节:
union u{
int i;
char c;
};
再看一种情况:
union u{
int i;
char c[10];
};
此时大小就不是10而是12,因为这里最大基础成员的大小是4(即int类型)。
32位环境下的结构体大小
① 成员的起始地址偏移
#include 输出结果为:
sizeof a : 20
a.c1 addr: 0xbee3ed4c
a.s1 addr: 0xbee3ed4e
a.i1 addr: 0xbee3ed50
a.c2 addr: 0xbee3ed54
a.pc addr: 0xbee3ed58
a.u1 addr: 0xbee3ed5c
sizeof b : 20
b.c1 addr: 0xbee3ed38
b.s1 addr: 0xbee3ed3a
b.c2 addr: 0xbee3ed3c
b.i1 addr: 0xbee3ed40
b.pc addr: 0xbee3ed44
b.u1 addr: 0xbee3ed48
sizeof c : 16
c.c1 addr: 0xbee3ed28
c.c2 addr: 0xbee3ed29
c.s1 addr: 0xbee3ed2a
c.i1 addr: 0xbee3ed2c
c.pc addr: 0xbee3ed30
c.u1 addr: 0xbee3ed34
根据输出结果画出内存分布图进行对比:

对比一下以上三种情况,虽然成员都相同,但是由于内存需要对齐,所以在内存的分布是不一样的,也就会导致结构体的尺寸不一样。
另外需要注意的是,结构体B的c1、s1、c2三个成员:s1的起始地址需要能将它大小整除,所以会偏移,这点很容易算错,如图所示分布图:

② 以最宽基础成员大小对齐
#include 输出结果为:
sizeof D: 24
d.c1 addr: 0xbec5cd48
d.s1 addr: 0xbec5cd4a
d.d1 addr: 0xbec5cd50
d.c2 addr: 0xbec5cd58
sizeof E: 6
e.ch1 addr: 0xbec5cd42
e.ch2 addr: 0xbec5cd43
e.ch3 addr: 0xbec5cd45
由于结构体D中最宽基础类型成员的宽度是8,对齐值就是8,所以大小是24。而结构体E中包含数组,但是以最宽基础类型而不是以数组大小对齐。内存分布图如下:

③ 同样地以最宽基础成员对齐:结构体包含结构体
#include 输出结果:
sizeof F : 16
sizeof G : 24
g.c1 addr: 0xbeaced48
g.f1.i1 addr: 0xbeaced50
g.f1.d1 addr: 0xbeaced58
结合输出的地址画出内存地址分布图:
 结构体F的最宽基础类型是double,所以内部以8字节对齐;将F作为G的一个成员之后,结构体G最宽基础类型是double(它的成员f结构体不是基础类型),所以也变成8字节对齐。
结构体F的最宽基础类型是double,所以内部以8字节对齐;将F作为G的一个成员之后,结构体G最宽基础类型是double(它的成员f结构体不是基础类型),所以也变成8字节对齐。
重点在于i1在内存中的位置:考虑对齐时结构体F作为一个整体不能拆分,它原本内部的分布已经是固定的了,不会因为位置的变化而变化,例如以下结构体G的分布是错误的:

只要将以下3点结合即可计算出结构体大小:
- 结构体成员偏移地址需满足:该成员大小的整数倍。比如结构体B的s1不能在c1末尾的奇数地址上,而只能偏移到能够将s1本身大小整除的下一个偶数地址上;
- 结构体大小需满足:最大基础类型成员的整数倍,换句话说就是以它的大小为对齐值,而不是默认的字节对齐。另外注意的是,数组、结构体、联合体、枚举都不是基础类型,也就是说不能以它们大小为内存对齐值,比如结构体G的大小就不是F的整数倍,而是以“退化”后的double类型大小进行对齐。
- 结构体起始地址需满足:最宽成员大小的整数倍。这点与讨论结构体的尺寸大小关系不是特别大。
④ 自定义内存对齐值#pragma pack(n)
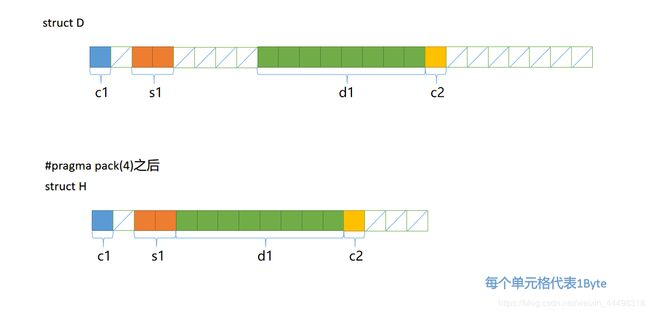
前面讨论的都是编译器默认的方式,现在我们探讨一下自定义内存对齐值。#pragma pack(n)可以根据自己需求设定内存对齐值,n的合法的取值可以是1、2、4、8、16。前面我们所讲的结构体D最宽基础成员是double的8字节,所以编译器默认以8字节对齐,那么我们现在复制一份下来对比一下两种方式:
#include 输出结果:
sizeof D: 24
d.c1 addr: 0xbebc8d48
d.s1 addr: 0xbebc8d4a
d.d1 addr: 0xbebc8d50
d.c2 addr: 0xbebc8d58
sizeof H: 16
h.c1 addr: 0xbebc8d38
h.s1 addr: 0xbebc8d3a
h.d1 addr: 0xbebc8d3c
h.c2 addr: 0xbebc8d44
结合输出结果画出内存分布,可以看到,内存不是以8字节对齐了,而是以我们设定的4字节对齐,#pragma pack(push)与pack(pop)这两句宏定义不是必须的,但加上就只限定该区间为自定义的内存对齐值而不是整个程序:
⑤ 位域
它不是以字节为单位存储,而是以位来存储,看下面程序:
#include 运行结果:
sizeof I = 4
位域的用法一般用在低级编程中,平时我们可以用按位运算符(&、|)来代替这种用法。
在C++中,结构体(struct)是一个特殊的类(class),C++增强了结构体的功能,里面可以定义“成员函数”,会稍微有些不同,要以类的形式去讨论。