操作系统 --- 虚拟文件系统
文章目录
- 1、虚拟文件系统的分层结构
- 2、数据块缓存
- 3、打开文件的数据结构
- 4、文件分配
- (1)连续分配
- (2)链式分配
- (3)索引分配
- 5、空间列表
1、虚拟文件系统的分层结构
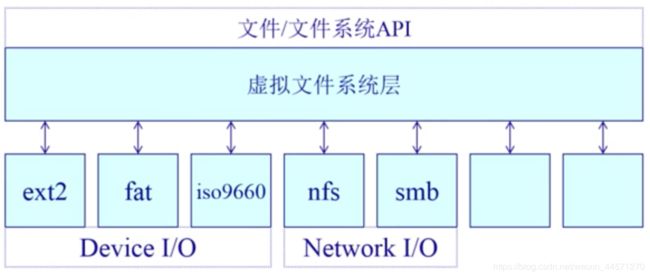
上层:虚拟文件系统
底层:特定文件系统模块,例如:网络文件系统(nfs、smb)等其他类型文件系统
虚拟文件系统的目的:将接口暴露给用户,屏蔽底层文件系统的差异性,它是对所有不同文件系统的抽象
虚拟文件系统的功能:
- 提供一致的文件和文件系统接口
- 管理所有文件和文件系统关联的数据结构
- 高效查询例程,遍历文件系统
- 与特定文件系统模块的交互
基本数据结构:
- 卷控制块,总的,superblock,每个文件系统一个,块,块大小,空余块,计数/指针等
- 文件控制块:VNODE/INODE, 单个文件一个,文件的详细信息
- 目录节点:dentry(dictionary entry),每个目录项一个,将目录项数据结构及属性布局编码成树型数据结构
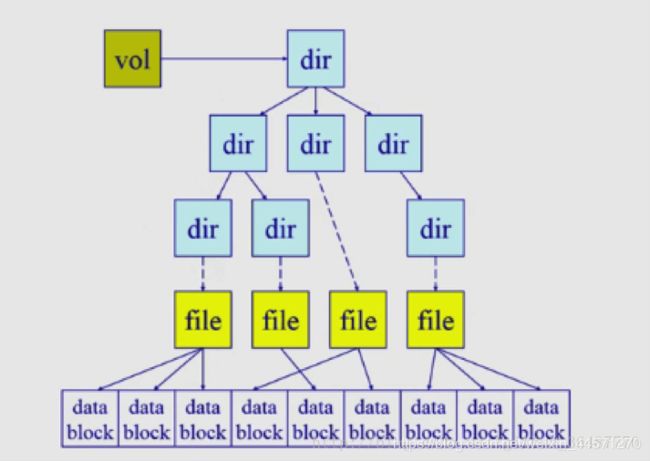 数据持续存储在
数据持续存储在二级存储中,当需要时加载进内存。
二级存储(secondary storage,auxiliary storage)是计算机主存储器或内存之外的所有可访问数据存储器。即为硬盘、磁带、光盘等非易失性存储。
- 卷控制块:文件系统挂载时进入内存
- 文件控制块:文件被访问时进入内存
- 目录节点: 在遍历一个文件路径时进入内存
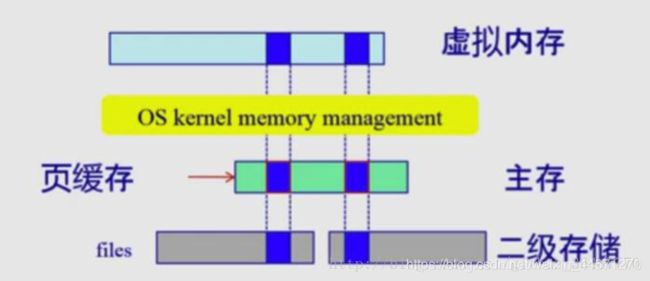
2、数据块缓存
如今缓存的概念已被扩充,不仅在CPU和主内存之间有Cache(L1 cache、L2 cache),而且在内存和硬盘之间也有Cache(磁盘缓存),乃至在硬盘与网络之间也有某种意义上的Cache──称为Internet临时文件夹或网络内容缓存等。凡是位于速度相差较大的两种硬件之间,用于协调两者数据传输速度差异的结构,均可称之为Cache。
我们这里说的数据块缓存是磁盘缓存!
数据块就是block块,它是主存和外存传输数据的单位,文件存取的最小单位。
#缓存过程:
数据块按需读入内存,数据块使用后被缓存
#两种数据块缓存方式,缓存的粒度不同
普通缓冲区缓存
页缓存:统一缓存数据块和内存页
文件数据块的页缓存
在虚拟内存中文件数据块被映射成页
文件的读/写操作被转换成对内存的访问
可能导致缺页、脏页
相应算法,尽量减少对硬盘的读写次数,类似之前的算法
3、打开文件的数据结构
我们先看一段python代码:
fd = open('db.txt',mode='rt',encoding='utf-8')
res = fd.read()
print(res)
fd.close()
上述代码是一段用于文件操作的代码。
打开文件的过程:fd是文件描述符(又叫文件句柄、文件对象),open一个文件,就会产生一个文件描述符,然后将该文件描述符存入打开该文件的进程的打开文件表。
#文件描述符
每个被打开的文件一个
文件状态信息
目录,当前文件指针。。。。
#打开文件表
一个进程一个(进程打开文件表又叫文件描述符表)
一个系统级的(系统打开文件表)
每个超级区块也会保存一个列表,进程打开文件的基本信息 #这个不是很明白!我猜测前面的系统打开文件表应该是虚拟文件系统的打开文件表,不论nfs、smb、ext2所有的打开文件的情况里面都有。每个superblock的文件打开表,例如nfs,应该就只是nfs文件系统的打开文件表。
文件描述符表、系统打开文件表、inode之间的关系如图所示:
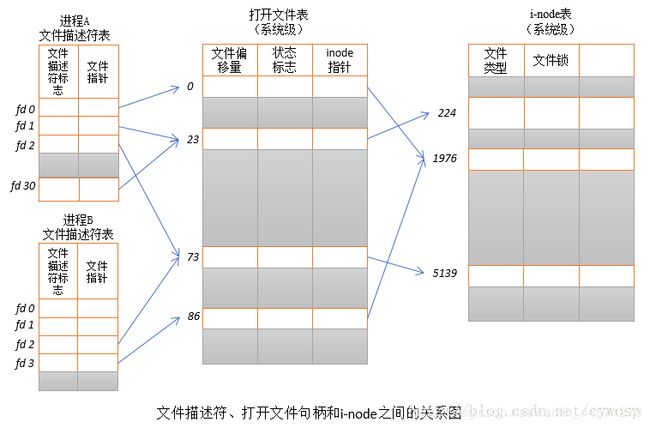
文件偏移量:即为文件指针的偏移量,每一个文件被打开之后,内核都维护一个所谓的当前文件位置偏移量,读和写操作都会对这个偏移量产生影响。
如果不懂文件指针就看这个博客:https://blog.csdn.net/weixin_44571270/article/details/105891195
inode和文件描述符之间的关系:
在linux中,内核通过inode来找到每个文件,但一个文件可以被许多用户同时打开或一个用户同时打开多次。这就有一个问题,如何管理文件的当前位移量,因为可能每个用户打开文件后进行的操作都不一样,这样文件位移量也不同,当然还有其他的一些问题。所以linux又搞了一个文件描述符(file descriptor)这个东西,来分别为每一个用户服务。每个用户每次打开一个文件,就产生一个文件描述符,多次打开就产生多个文件描述符,一一对应,不管是同一个用户,还是多个用户。该文件描述符就记录了当前打开的文件的偏移量等数据。
#所以一个i节点可以有0个或多个文件描述符与之对应。可以看成文件描述符是对i节点的索引。
4、文件分配
为应对不同大小的文件,如何为一个文件分配数据块呢?
#分配方式
连续分配
链式分配
索引分配
#评价指标:
时间高效
空间高效
(1)连续分配
I:文件头
 上图中数据块的分配都是连续的。
上图中数据块的分配都是连续的。因为是连续的,如果再往文件写内容,那么我们看A文件内容还能加多少?所以它一般用于写文件。
优点:文件读取表现好,高效的顺序和随机访问
劣势:碎片,文件增长问题(预分配,按需分配),类似数组 (长度不可变)
注意这种模式:最好用于只读文件
(2)链式分配
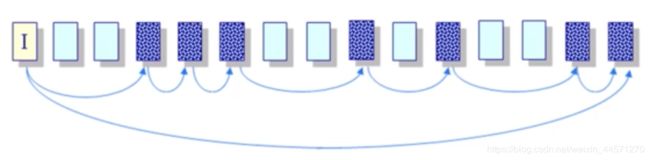 以数据块链表方式存储,文件头包含了到第一块和最后一块的指针
以数据块链表方式存储,文件头包含了到第一块和最后一块的指针
访问链表中间一个数,是需要对链表进行遍历的,所以不可随机访问。
优点:创建,增大缩小容易,没有碎片
缺点:不可随机访问,可靠性(破坏一个链然后整个文件都崩了)
(3)索引分配
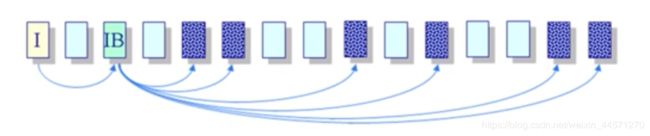
IB:索引数据块
每个磁盘块(索引项),为每个文件创建一个名为索引数据块的非数据数据块(到文件数据块的指针列表)
文件头包含了索引数据块
优点:创建,增大缩小都很容易,没有碎片,支持直接访问
缺点:当文件很小时,存储索引的开销,如何处理大文件?
释意:文件大,占用数据块就多,那么相对的索引数据就变大了,我们一个索引数据块就不够用了,所以我们需要多个索引数据块
大文件采用分层的方式,类似内存管理的思想:
- 链式索引块
- 多级索引块,文件头包含多个指针 #类似多级页表

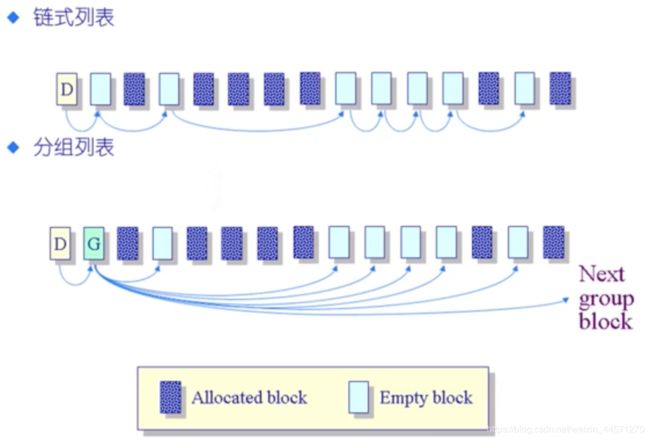
5、空间列表
空间列表的作用:跟踪在存储中的所有未分配的数据块,为了更好的分配空闲块。
用位图代表空闲数据块列表
11111001111,如果i = 0 代表数据块为空闲
假设空闲空间在磁盘中均匀分布,那么找到空闲数据块前需要扫描n/r
n —-磁盘上数据块的总数
r —- 空闲块的总数
为了保护空间列表和实际空闲块的位置的一致性:
位图必须保存在磁盘上
不允许block在内存中的状态为1而在磁盘中为0 ,这种不一致情况发生,因此需要在硬盘中完成把位图中的相应空闲块置为1之后再真正为文件分配数据块,文件内容写入数据块
空间列表的实现方式: