Hadoop集群环境搭建
Hadoop集群环境搭建
- 本机基本配置
- 网卡配置
- 配置主机名
- 关闭防火墙
- 安装ssh客户端
- 克隆虚拟机
- 删除一块网卡
- 更改ip
- 修改主机名
- hosts映射
- 免密登陆
- 安装jdk
- 安装Hadoop集群
- 策划,解压
- 配置hadoop-env.sh
- 配置core-site.xml
- 配置hdfs-site.xml
- 配置mapred-site.xml
- 配置yarn-site.xml
- 配置slaves
- Hadoop环境变量
- 把配置好的文件发送给集群的其他节点
- 启动集群
- 初始化集群
- 启动HDFS集群
- 启动yarn集群
- 附录
- 使用到的网站
- 免密登陆脚本
- ssh客户端安装有问题
- 集群启动问题
本机基本配置
网卡配置
编辑如下文件
vi /etc/sysconfig/network-scripts/ifcfg-eth0
内容
DEVICE=eth0
TYPE=Ethernet
ONBOOT=yes
NM_CONTROLLED=yes
BOOTPROTO=static
IPADDR=192.168.200.130
NETMASK=255.255.255.0
GATEWAY=192.168.200.2
DNS1=192.168.200.2
DNS2=114.114.114.114
配置主机名
编辑文件
vi /etc/sysconfig/network
内容为
NETWORKING=yes
HASTNAME=hadoop01
关闭防火墙
单次关闭和永久关闭
service iptables stop
chkconfig iptables off
安装ssh客户端
yum install -y openssh-clients
克隆虚拟机
删除一块网卡
vi /etc/udev/rules.d/70-presistent-net.rules
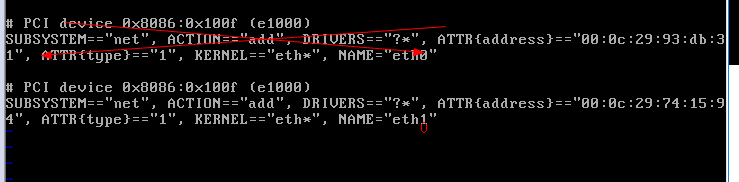
更改ip
编辑如下文件
vi /etc/sysconfig/network-scripts/ifcfg-eth0
更改ip
DEVICE=eth0
TYPE=Ethernet
ONBOOT=yes
NM_CONTROLLED=yes
BOOTPROTO=static
IPADDR=192.168.200.131
NETMASK=255.255.255.0
GATEWAY=192.168.200.2
DNS1=192.168.200.2
DNS2=114.114.114.114
修改主机名
vi /etc/sysconfig/network
内容
NETWORKING=yes
HOSTNAME=hadoop02
重启电脑,使网卡生效
其他需要克隆的机器只需要根据上述操作来来一遍就ok了。
hosts映射
linux必须做,windows为了使用方便也可以配置
192.168.200.160 hadoop01
192.168.200.161 hadoop02
192.168.200.162 hadoop03
免密登陆
可以使用
产生公钥和私钥
ssh-keygen -t rsa
把公钥发送给需要做免密的机器
ssh-copy-id -i /root/.ssh/id_rsa.pub hostname(ip) 需要给自己发一个
ssh-copy-id -i /root/.ssh/id_rsa.pub hostname(ip) 其他的机器发
可以使用免密登陆脚本做免密登陆,免密登陆见附录
安装jdk
- 解压文件到安装目录
tar -zxvf /root/jdk-8u102-linux-x64.tar.gz -C /usr/local/
- 配置环境变量
vi /etc/profile
内容:
export JAVA_HOME=/usr/local/jdk1.8.0_102
export PATH=$PATH:$JAVA_HOME/bin
- 使变量生效
source /etc/profile
安装Hadoop集群
策划,解压
解压:
tar -zxvf hadoop-2.7.3.tgz -C /usr/local/
配置hadoop-env.sh
# The java implementation to use.
export JAVA_HOME=/usr/local/jdk1.8.0_102
配置core-site.xml
配置Namenode在哪里 ,临时文件存储在哪里
<configuration>
<property>
<name>fs.defaultFSname>
<value>hdfs://bigdata3901:9000value>
property>
<property>
<name>hadoop.tmp.dirname>
<value>/usr/local/hadoop-2.7.3/tmpvalue>
property>
configuration>
配置hdfs-site.xml
配置namenode,datanode数据的本地存放位置,副本数量的多少,secondary的http地址
<configuration>
<property>
<name>dfs.namenode.name.dirname>
<value>/usr/local/hadoop-2.7.3/data/namevalue>
property>
<property>
<name>dfs.datanode.data.dirname>
<value>/usr/local/hadoop-2.7.3/data/datavalue>
property>
<property>
<name>dfs.replicationname>
<value>3value>
property>
<property>
<name>dfs.secondary.http.addressname>
<value>bigdata3901:50090value>
property>
configuration>
配置mapred-site.xml
首先把mapred-site.xml.tmp* 这个文件进行改名,改为 mapred-site.xml。
cp mapred-site.xml.tmp* mapred-site.xml
主要配置提交任务的方式,提交到yarn集群,默认是本地运行。
<configuration>
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
property>
configuration>
配置yarn-site.xml
主要是配置了yarn的老大在哪里,和一个map端程序结束的一个辅助服务开启。这里也可以加上每个小弟的资源数量,每个小弟的资源可以配置成不一样的。
<configuration>
<property>
<name>yarn.resourcemanager.hostnamename>
<value>bigdata3901value>
property>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
configuration>
配置slaves
这里是配置小弟有哪些,这里配置域名或者ip,不能都配置
bigdata3901
bigdata3902
bigdata3903
Hadoop环境变量
这个不是必须的,只是为了以后的操作方便。
export HADOOP_HOME=/usr/local/hadoop-2.7.3
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
把配置好的文件发送给集群的其他节点
把第一台安装好的jdk和hadoop以及配置文件发送给另外两台,主要发送的文件有下面几个:
- hosts文件
- jdk安装后的文件夹
- hadoop安装后的文件夹
- /etc/profile 文件
发送的命令如下所示
eg:scp -r /usr/local/jdk1.8.0_102 hadoop02:/usr/local/
启动集群
初始化集群
需要对namenode节点进行格式化,格式化会在配置的namenode目录下产生一些关于集群的id(用于集群的标示)等信息,只需要在namenode上操作一次
命令:
bin/hadoop namenode -format
启动HDFS集群
启动命令:
sbin/start-dfs.sh
启动后可以使用jps查看下相关进程是否启动。
- 在namenode节点上会有namenode进程
- 在datanode节点上会有datanode进程
- secondaryNameNode也会在配置的节点上启动
也可以通过网页来查看是否启动成功(namenode的50070端口的web页面):
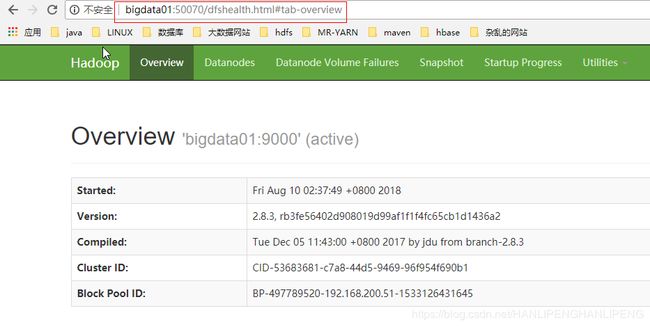
启动yarn集群
启动命令:
sbin/start-yarn.sh
启动后可以使用jps命令来查看相关进程的启动情况,
- yarn老大上启动了ResourceManeger进程
- yarn小弟上启动了NodeManeger进程
可以通过网页查看启动的情况(resourceManeger节点的8088端口的web页面):
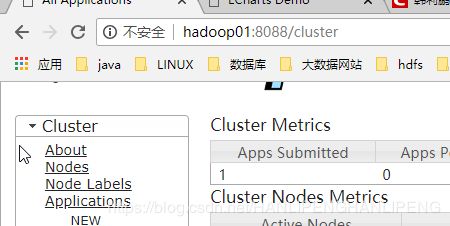
附录
使用到的网站
- hadoop安装包的下载位置是:Hadoop以及生态圈的组件安装下载地址
- jdk下载位置是:jdk所有版本下载地址
免密登陆脚本
#!/bin/bash
#yum安装expect
yum -y install expect
#PWD_1是登陆密码,可以自己设定
PWD_1=123456
ips=$(cat /etc/hosts |grep -v "::" | grep -v "127.0.0.1")
key_generate() {
expect -c "set timeout -1;
spawn ssh-keygen -t rsa;
expect {
{Enter file in which to save the key*} {send -- \r;exp_continue}
{Enter passphrase*} {send -- \r;exp_continue}
{Enter same passphrase again:} {send -- \r;exp_continue}
{Overwrite (y/n)*} {send -- n\r;exp_continue}
eof {exit 0;}
};"
}
auto_ssh_copy_id () {
expect -c "set timeout -1;
spawn ssh-copy-id -i $HOME/.ssh/id_rsa.pub root@$1;
expect {
{Are you sure you want to continue connecting *} {send -- yes\r;exp_continue;}
{*password:} {send -- $2\r;exp_continue;}
eof {exit 0;}
};"
}
# rm -rf ~/.ssh
key_generate
for ip in $ips
do
auto_ssh_copy_id $ip $PWD_1
done
ssh客户端安装有问题
执行免密登陆脚本的时候出现如下问题的:
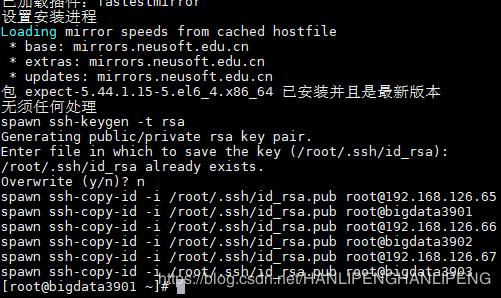
原因:ssh客户端没有安装好,卸载重新安装就可以了(先一出,然后再clean下,然后再安装)。
yum remove -y openssh-clients
yum clean all
yum install -y openssh-clients
集群启动问题
集群启动问题多看log日志,日志的位置在安装目录下面的logs里面,一定要勇于看日志。
本文由鹏鹏出品
更多文章请访问韩利鹏的博客