Hadoop2.7.5完全分布式集群搭建和测试
[TOC]
1 准备
1.2 版本信息介绍
环境软件:Vmware workstation12
系统:CentOS-7-x86_64-DVD-1708.iso 1GB内存 20GB硬盘
JDK:jdk-8u161-linux-x64.tar.gz
Hadoop:hadoop-2.7.5.tar.gz
| 节点 | IP |
|---|---|
| master | 195.168.95.20 |
| node1 | 192.168.95.21 |
| node2 | 192.168.95.22 |
备注:官网下载软件
1.2 流程介绍
初始化虚拟机
创建虚拟机,修改主机名为master,设置静态IP,修改系统的镜像源为阿里云源,关闭防火墙,建立hadoop用户组和用户名,安装JDK
克隆出node节点
建立SSH
配置master的hadoop
复制hadoop文件到node节点
配置master环境变量,启动,测试
2 初始化工作
安装好Vmware ,创建虚拟机master,设置静态IP为195.168.95.20,修改系统源为阿里源,关闭防火墙....
2.1 设置静态IP
#修改主机名为master
$hostnamectl set-hostname master
#设置IP
$vi /etc/sysconfig/network-scripts/ifcfg-ens33
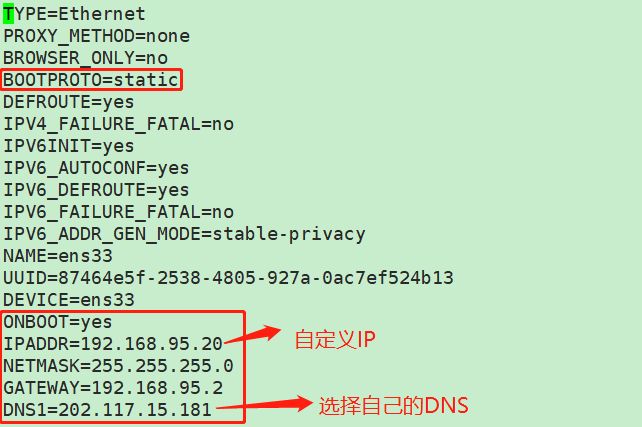
备注:可能需要修改/etc/sysconfig/network文件
$vi /etc/sysconfig/network
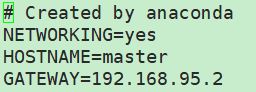
#重启网络
$service network restart
测试看看是否可以联网,若能联网,则进行下一步。
2.2 防火墙和下载源
#停止firewall
systemctl stop firewalld.service
#禁止firewall开机启动
systemctl disable firewalld.service
#更换源
yum install -y wget
mv /etc/yum.repos.d/CentOS-Base.repo /etc/yum.repos.d/CentOS-Base.repo.backup
wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo
yum clean all
rpm --rebuilddb
yum makecache
2.3 新建组和用户
新建Hadoop的分组和用户,后续hadoop的所有的操作都在此分组下操作。
#新建用户组hadoop和用户hadoop (root用户操作)
$groupadd hadoop
$useradd -g hadoop hadoop
$passwd hadoop
#修改/etc/sudoers或者执行visudo命令,在root ALL ... 下添加hadoop的权限

备注:下面全部用hadoop用户操作
2.4 JDK安装
下载JDK1.8(jdk-8u161-linux-x64.tar.gz),解压在自定义目录,然后配置环境变量
#使用hadoop用户
$su hadoop
#解压
$sudo mkdir -p /usr/java
$sudo tar -zxvf jdk-8u161-linux-x64.tar.gz -C /usr/java
$sudo vi /etc/profile
JAVA_HOME=/usr/java/jdk1.8.0_161
CLASSPATH=.:$JAVA_HOME/lib:$CLASSPATH
PATH=$JAVA_HOME/bin:$PATH
export JAVA_HOME CLASSPATH PATH
#更新环境变量
$source /etc/profile
#查看是否安装成功
$java -version
jdk安装成功后,克隆master虚拟机,分别克隆为node1和node2,然后其次启动打开,进行下一步的ssh免密码配置。
3 SSH免密码配置
前提虚拟机需要安装ssh服务,操作都在hadoop用户下
在master、node1、node2的/etc/hosts文件中写入所有节点的ip和主机名,在所有节点均执行如下的操作。
$sudo vi /etc/hosts
192.168.95.20 master
192.168.95.21 node1
192.168.95.22 node2
master节点:
相关参考资料:ssh免密码登陆及其原理
#生成私钥公钥,连续回车
$ssh-keygen -t rsa -P ''
$cd /home/hadoop/.ssh
node1节点:
#生成私钥公钥,连续回车
$ssh-keygen -t rsa -P ''
$cd /home/hadoop/.ssh
$scp id_rsa.pub hadoop@master:~/.ssh/id_rsa.pub.node1
node2节点:
#生成私钥公钥,连续回车
$ssh-keygen -t rsa -P ''
$cd /home/hadoop/.ssh
$scp id_rsa.pub hadoop@master:~/.ssh/id_rsa.pub.node2
master节点:
$cd /home/hadoop/.ssh
$cat id_rsa.pub >> authorized_keys
$cat id_rsa.pub.node1 >> authorized_keys
$cat id_rsa.pub.node2 >> authorized_keys
然后将authorized_keys发送到node1、node2
$scp authorized_keys hadoop@node1:~/.ssh/authorized_keys
$scp authorized_keys hadoop@node2:~/.ssh/authorized_keys
测试ssh免密码是否成功,ssh master/node1/node2,第一次需要输入密码,之后就可以直接登陆,没有问题了就再进行下一步。
4 hadoop安装
在官网下载hadoop(hadoop-2.7.5.tar.gz),解压在自定义目录,创建name和data目录,以及tmp目录。
dfs.name.dir:保存namenode元数据的位置,可以指定多个目录,元数据文件会同时写入这几个目录,从而支持冗余备份。最好有一个是NFS网络硬盘
dfs.data.dir:保存datanode数据文件的位置,可以指定多个目录,这多个目录位于不同的磁盘可以提高IO使用率
#解压
$sudo mkdir -p /usr/hadoop
$sudo tar -zxvf hadoop-2.7.5.tar.gz -C /usr/hadoop/
#新建目录name、data、tmp
$sudo mkdir -p /usr/hadoop/data/hdfs/name
$sudo mkdir -p /usr/hadoop/data/hdfs/data
$sudo mkdir -p /usr/hadoop/data/tmp
#授权新建的目录
$sudo chown -R hadoop:hadoop /usr/hadoop/hadoop-2.7.5
$sudo chown -R hadoop:hadoop /usr/hadoop/data
5 hadoop文件配置
都在/usr/hadoop/etc/hadoop文件下,需要配置一下的文件
hadoop-env.sh
yarn-env.sh
slaves
core-site.xml
hdfs-site.xml
mapred-site.xml
yarn-site.xml
5.1 hadoop-env.sh
修改JAVA_HOME值export JAVA_HOME=export JAVA_HOME=/usr/java/jdk1.8.0_161

5.2 yarn-env.sh
修改JAVA_HOME值export JAVA_HOME=export JAVA_HOME=/usr/java/jdk1.8.0_161

5.3 slaves
在slave中写入datanode的hostname/IP
node1
node2
5.4 core-site.xml
fs.defaultFS
hdfs://master:9000
io.file.buffer.size
131072
hadoop.tmp.dir
file:/usr/hadoop/data/tmp
Abase for other temporary directories.
5.5 hdfs-site.xml
dfs.namenode.secondary.http-address
master:9001
dfs.namenode.name.dir
file:/usr/hadoop/data/hdfs/name
dfs.datanode.data.dir
file:/usr/hadoop/data/hdfs/data
dfs.replication
2
dfs.webhdfs.enabled
true
5.6 mapred-site.xml
#创建mapred-site.xml
$sudo cp mapred-site.xml.template mapred-site.xml
$sudo vi mapred-site.xml
mapreduce.framework.name
yarn
mapreduce.jobhistory.address
master:10020
mapreduce.jobhistory.webapp.address
master:19888
5.7 yarn-site.xml
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.nodemanager.aux-services.mapreduce.shuffle.class
org.apache.hadoop.mapred.ShuffleHandler
yarn.resourcemanager.address
master:8032
yarn.resourcemanager.scheduler.address
master:8030
yarn.resourcemanager.resource-tracker.address
master:8031
yarn.resourcemanager.admin.address
master:8033
yarn.resourcemanager.webapp.address
master:8088
6 复制hadoop文件到node
master节点:
#将hadoop文件夹复制到node1 先转存 再存到具体目录
$scp -r /usr/hadoop hadoop@node1:/home/hadoop/
#将hadoop文件夹复制到node2
$scp -r /usr/hadoop hadoop@node2:/home/hadoop/
node1节点:
$cd /home/hadoop
$sudo mv hadoop/ /usr/
node2节点:
$cd /home/hadoop
$sudo mv hadoop/ /usr/
7 配置环境变量
#编辑/etc/profile
sudo vi /etc/profile
#hadoop
export HADOOP_HOME=/usr/hadoop/hadoop-2.7.5
export PATH=$PATH:$HADOOP_HOME/sbin
export PATH=$PATH:$HADOOP_HOME/bin
$source /etc/profile
#设置hadoop的全局命令
$cd
$vi .bashrc
HADOOP_HOME=/usr/hadoop/hadoop-2.7.5
PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
export HADOOP_HOME PATH
#source .bashrc
8 格式化和启动Hadoop
$hdfs namenode -format
备注:出现Storage directory /usr/hadoop/data/hdfs/name has been successfully formatted时,则格式化成功
启动hdfs
$start-dfs.sh
$start-yarn.sh
$mr-jobhistory-daemon.sh start historyserver
$jps
[hadoop@master ~]$ jps
2422 SecondaryNameNode
3034 ResourceManager
9626 Jps
3324 JobHistoryServer
2239 NameNode
[hadoop@node1 hadoop]$ jps
1458 NodeManager
5223 Jps
1343 DataNode
[hadoop@node2 ~]$ jps
5328 Jps
1257 DataNode
1372 NodeManager
查看web端

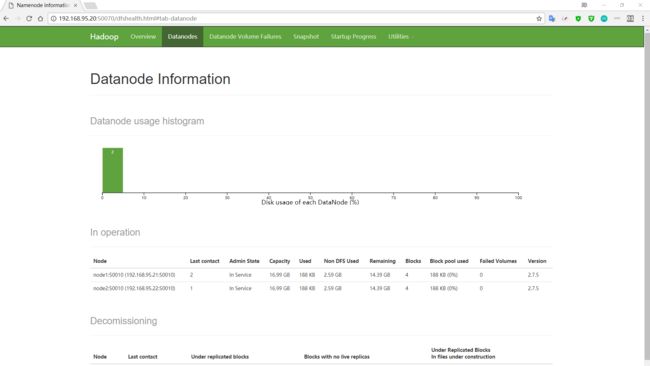
9 测试
执行wordcount
$hdfs dfs -mkdir /wordcount
$hdfs dfs -put wordcount.txt /wordcount
$yarn jar /usr/hadoop/hadoop-2.7.5/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.5.jar wordcount /wordcount/wordcount.txt /wordcount/output
查看结果
$hdfs dfs -cat /wordcount/output/part-r-00000
词频统计正确,至此,hadoop搭建成功。
10 hdfs命令
#关闭hadoop
$mr-jobhistory-daemon.sh stophistoryserver
$stop-yarn.sh
$stop-dfs.sh
#查看hdfs进程
$jps
#创建文件夹
$hdfs dfs -mkdir -p /log/20161001
#上传文件或目录
$hdfs dfs -put log.txt /log/20161001/
$hdfs dfs -copyFromLocal log.txt /log/20161001/
#将文件从HDFS复制到本地(默认当前目录)
$hdfs dfs -get /wordcount/output/part-r-00000 /home/hadoop
$hdfs dfs -copyToLocal /log/20161001/log.txt /home/Hadoop
#连接文件到本地
$hdfs dfs -getmerge /user/hadoop/output/ /home/hadoop/merge --将output目录下的所有文件合并到本地merge文件中
#显示目录下的文件
$hdfs dfs -ls /log/20161001/
#如果是文件,返回文件信息如下:权限 <副本数> 用户ID 组ID 文件大小 修改日期 修改时间 权限 文件名
#如果是目录,返回目录信息如下:权限 用户ID 组ID 修改日期 修改时间 目录名
#递归显示目录下的文件
$hdfs dfs -ls -R /log/20161001/
#查看内容
$hdfs dfs -text /log/20161001/log.txt
#或-cat、-tail命令,但对于压缩文件只能用 -text 参数来查看,否则是乱码
#删除 文件
$hdfs dfs -rm /log/20161001/log.txt
#删除文件夹
$hdfs dfs –rmr /log/20161001/log.txt
#复制文件:将file1文件复制到file2
$hdfs dfs -cp /user/hadoop/file1 /user/hadoop/file2
#将文件file1,file2复制到dir目录下
$hdfs dfs -cp /user/hadoop/file1 /user/hadoop/file2 /user/hadoop/dir
#移动文件:将文件file1移动到file2
$hdfs dfs -mv /user/hadoop/file1 /user/hadoop/file2
#将file1 file2 file3 移动到dir目录下
$hdfs dfs -mv /user/hadoop/file1 /user/hadoop/file2 /user/hadoop/file3 /user/hadoop/dir
#distcp 分布式复制程序,是由 MapReduce 作业来实现的,
#它是通过集群中并行运行的 map 来完成集群之间大量数据的复制
$hadoop distcp hdfs://cloud001:9000/a/b hdfs://cloud002:9000/a #默认情况下 distcp 会跳过目标路径下已经存在的文件
$hadoop distcp -overwrite hdfs://cloud001:9000/a/b hdfs://cloud002:9000/a,覆盖现有文件
$hadoop distcp -update hdfs://cloud001:9000/a/b hdfs://cloud002:9000/a,更新有改动过的文件
#查看正在运行的 Job
$mapred job -list,-list all显示所有job
#关闭正在运行的 Job
$mapred job -kill job_2732108212572_0001
#检查 HDFS 块状态,查看是否损坏
$hdfs fsck /
#检查 HDFS 块状态,并删除损坏的块
$hdfs fsck / -delete
#检查 HDFS 状态,包括 DataNode 信息
$hdfs dfsadmin –report
#Hadoop 进入安全模式
$hdfs dfsadmin -safemode enter
#Hadoop 离开安全模式
$hdfs dfsadmin -safemode leave
#平衡集群中的文件
$sbin/start-balancer.sh
参考资料
1 Hadoop2.7.3完全分布式集群搭建和测试
20180125---Boy