融云高性能消息数据存储引擎的设计解析
2018年10月22日,QCon全球软件开发大会上海站成功落下帷幕。融云联合创始人兼首席架构师李淼再次受邀出席大会,并进行《高性能消息数据存储引擎的设计解析》的主题演讲,为参会者深入剖析了融云首次公开的最新技术研究成果“数据存储引擎设计”。

融云消息存储历程
首先是融云在开始时的原型产品验证阶段,大概是在2013年初创阶段,为了验证融云的即时通信业务模式,此时的消息都是存储在MySQL中,其特点是开发简单,可以满足各种产品需求。
在原型验证通过后,正式上线前融云将离线消息迁移到了Redis中以满足性能需求,而历史消息则继续保存在MySQL中。
融云经过一年多业务飞速的发展,要存储的消息越来越多,而Redis集群也几乎每1-2个月就要进行扩容。当时处于对成本的考量,融云决定采用相对低廉的磁盘存储方案。此时融云做了很多选型,最终决定采用基于levelDB作为存储引擎并自研DB。但是当时的由于levelDB数据归并消耗高,数据淘汰困难等问题,运行两个月后替换了原来的Redis存储方案。
目前融云的线上情况是Redis存储离线消息,levelDB存储历史消息,而融云的业务也相对进入了平稳期,Redis最近一次扩容是在2018年的5、6月份,根据业务增速情况可以支持到2018年底。
存储架构相对稳定, 为什么融云还要启动自研存储项目呢?
- 满足一些复杂的业务场景需求
基于目前的存储方案,一些需求实现起来非常困难,而这些需求都是来自客户,从而制约产品的演进,所以融云急需一个替代方案;
- 降低整体的成本投入
融云线上的Redis集群成本是所有设备投入的一半以上,对于存储的优化,显然是可以持续降低公司运营成本;
- 简化部署模型
对于Redis的部署不是很复杂,但是融云除了公有云的业务以外还有私有云项目,继续使用Redis对客户侧的运维部署成本就会变的很高;
- 源码可控
之前融云使用过很多的开源产品,当这些产品不能满足业务需求时,融云又急需某些特性时,这就需要和作者联系,但是大部分时候作者都不能及时响应或者根本不在其计划内,而这时融云只能等或者自己改,自己改的又回馈不了开源产品的主干上,或者当开源产品更新没办法合并,这样就迫使融云必须启动自研存储项目。
即时通信类产品, 自研存储需具备哪些特点?
- 快速的数据淘汰能力
数据淘汰的过程不能对系统产生任何的影响;
- 避免数据合并
相对于levelDB来讲,当写入很多操作的时候levelDB的数据合并经常会发生CPU报警,导致写入查询响应速度慢等情况;
- 读写性能要求高
至少不能比融云现有使用的Redis速度慢;
- 开发使用灵活
在融云存储引擎设计过程中,不仅只是存储数据,而是当作开发框架来进行设计的,在各操作点上都提供Hook,从而能够满足各种业务场景需求。
站在前人的肩膀上远眺
融云在存储引擎设计过程中借鉴很多已有的成熟方案,并将这些方案进行优化整合,最终完成了自有的引擎设计。下面将罗列一些方案,并向前人致敬。
- 数据写入采用WAL模式
数据在写入内存时同时记录,当服务宕机或重启的时候可以根据这些恢复内存数据。这些都是按照磁盘顺序写入,可以变相的提高存储引擎性能。一般主流的数据库都会采用这种模式完成数据写入。
- 借鉴InfluxDB中的LSM数据结构
LSM数据结构是目前一些新兴数据库采用的数据结构,像LevelDB、RocksDB、HBase、Cassandra等。即时通讯消息具备时序数据的特点,而InfluxDB更是时序数据库中的佼佼者,融云对InfulxDB做了一些改造,使其更适合存储一些时序数据。
- 借鉴whiskey 的 K / V 分离存储设计
whiskey 是2016年发表的一篇论文,主要解决了LSM中大数量写入后频繁数据归并的问题,在LSM这种数据结构中,数据的Key和Value值都是要写入内存的,当数据到达内存设定的阈值时进行归档处理。对于value值较大的数据来说,这个归档就会变得特变频繁,而whiskey的理念是将value单独保存至另外的文件位置,LSM结构内保存的是Key以及这个Value所在文件的偏移量和长度,以此来降低归档频。按照论文上的介绍,归档频率可以降低一个数量级。
- 借鉴MyISAM的存储文件设计
在文件设计这块融云一共经历四版改动,最终殊途同归。融云发现Mysql中MyISAM引擎的文件设计很有类似之处。
融云消息存储引擎设计
- 存储逻辑划分
2.
- 存储文件规划
关于Table文件分为三种文件进行组织存储:
xxx.data 数据存储文件;
xxx.index 数据索引文件;
xxx.info table信息文件。
文件并没有按照Table文件进行划分存储,是按照序号字段进行排序,为的是在设计过程中解决主从复制,提高便捷性。
- 数据写入逻辑

4.数据文件设计
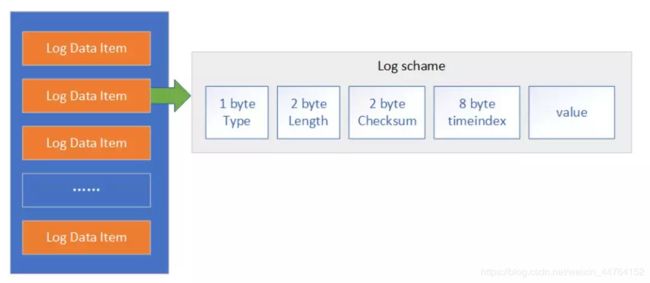
5.日志文件设计

6.索引文件设计
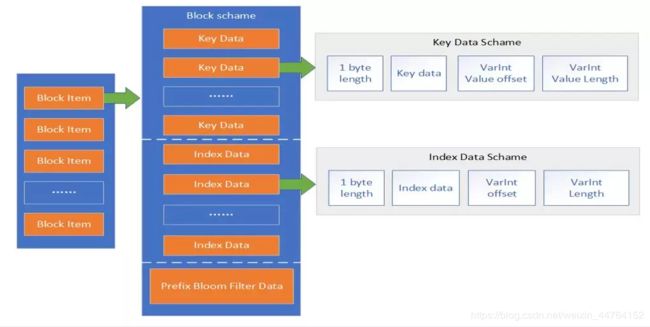
7.信息文件设计

内存优化
-
在M_block中融云重度依赖跳表这种数据结构,融云的存储引擎是用java写的,主要考虑是后面可移植的问题。起初融云采用了java里面内置的ConcurrentSkipList,但是其内存消耗很高,这个主要是java的中对象内存分配的规则导致的。所以融云重写了SkipList,放弃了java中的对象模式。重新造的轮子其内存消耗只有原始 1/4,同时也牺牲了一些东西,例如:删除跳表内的数据时,其删除的数据所占的内存无法释放,但是对于即时通信消息来讲基本上不存在删除的场景,同样一些时序数据也极少存在删除场景;
-
索引数据融云进行了一系列紧凑处理。优化后40亿级的索引数据,只消耗内存400MB。放弃java对象模式,直接采用byte数值的方式进行数据组织;
-
对很多的对象又做了一些细节处理,想办法把Java本身的一些内存模型给抹平掉,通过这种方式来降低内存利用率;
-
最后融云做了LIRS的缓存机制。
存储优化
-
索引数据前缀压缩,降低磁盘的写入量;
-
数值数据采用VarInt编码;
-
业务数据QuickLZ压缩,平衡了存储及CPU的使用率;
-
数据写入采用双循环可变长度Buffer,使数据写入过程中是没有直接操作的,有效降低延迟的产生;
-
重复数据引用写入,该优化对于即时通信场景有显著成效。
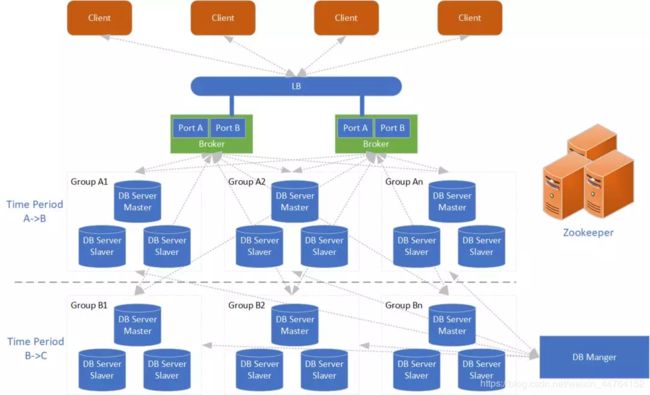
服务端架构
该架构主要包含Broker,以及一些数据的分组Master、Slaver,这些数据是根据ZooKeeper进行管理,同时向Broker进行汇报。在Broker上会开设不同的端口去设置各种不同的协议。最后是DB manger,主要是用于管理引擎的各种数据查询的插件,就像前文提到的该引擎除了是用于数据存储外还是开发框架,程序员在架构上可以灵活按照熟悉的开发语言去直接操作这些数据。
数据存储引擎项目将在年底开源
李淼在会上表示,为了促进产业内的技术交流,融云会在未来两个月时间对数据存储引擎项目进行开源,开源前除了对引擎做一些优化以外,还会补充一些相关的文档,同时为了方便开发者集成参考还会对代码增加一些注释。项目开源后意味着融云是国内首家将自研的消息存储引擎开源的云通信厂商,也正在为中国的开源环境贡献自己应尽的力量。