python运用sklearn进行数据拟合和回归
在上一篇讲了最小二乘法实现线性回归的原理,实现方面用的是python的static.optimize中的leastsq求出拟合函数。本篇通过sklearn库中的模块来进行拟合和线性回归,并计算拟合误差。
对于线性回归来说,无论是用什么工具实现,步骤都是大同小异的:
- 初始化多项式方程
- 对多项式方程进行多次迭代,通过最小二乘法求出使平方损失函数最小情况下的拟合方程。
- 对模型预测结果进行评估
- 调整参数修正模型
生成多项式方程
from sklearn.pipeline import Pipeline
clf = PolynomialFeatures(degree=3)
其中,degree参数为多项式的阶数
线性回归
from sklearn import linear_model
clf = linear_model.LinearRegression()
评估模型预测结果(误差分析)
- 标准误差(Standard Error),也称为均方根误差(Root Mean Square Error)。 S t d E r r o r ( y p r e d i c t , y t r u e ) = ∑ 1 n ( y p r e d i c t i − y t r u e i ) 2 n , i ∈ ( 1 , n ) StdError(y_{predict}, y_{true}) =\sqrt{\frac{\sum_{1}^{n}(y_{predict_i} - y_{true_i})^2}{n}}, i∈(1,n) StdError(ypredict,ytrue)=n∑1n(ypredicti−ytruei)2,i∈(1,n)
- R2方法,比较用该模型进行预测与用均值进行预测的效果,所得结果在[0,1]之间,0表示不如均值,1表示完美预测。此处R2有两种算法:
- 对比该模型预测与均值预测跟实际值的标准误差,即均方根误差的比值 R 2 = 1 − s t d E r r o r ( y p r e d i c t , y t r u e ) s t d E r r o r ( y t r u e M e a n , y t r u e ) R2=1-\frac{stdError(y_{predict}, y_{true})}{stdError(y_{trueMean}, y_{true})} R2=1−stdError(ytrueMean,ytrue)stdError(ypredict,ytrue)
- 对比该模型预测与均值预测跟实际值的差距平方和,即均方误差的比值 R 2 = 1 − ∑ 1 n ( y p r e d i c t i − y t r u e i ) 2 ∑ 1 n ( y t r u e M e a n i − y t r u e i ) 2 , i ∈ ( 1 , n ) R2=1-\frac{\sum_{1}^{n}{(y_{predict_i} - y_{true_i}})^2}{\sum_{1}^{n}{(y_{trueMean_i} - y_{true_i}})^2}, i∈(1,n) R2=1−∑1n(ytrueMeani−ytruei)2∑1n(ypredicti−ytruei)2,i∈(1,n)
调整参数修正模型
在线性回归预测过程中,可能会出现过拟合、欠拟合等现象,使模型预测效果或表现效果下降,此时需要调整参数,常见的做法是在损失函数后加上惩罚项。
- Lasso法:使用L1正则化, alpha参数用于指定惩罚项权重。当alpha=0时相当于调用LinearRegression。因此选择合适的alpha参数非常重要。sklearn还提供了Lassocv模块,可对多个alpha参数进行交叉验证,并选择最合适的进行拟合。
lasso = linear_model.Lasso(alpha=0.0001)
lassocv = linear_model.LassoCV(alphas=[0.0001, 0.01, 0.1, 1])
- 岭回归:使用L2正则化,使用方法与Lasso相同
ridge = linear_model.Ridge(alpha=0.0001)
ridgecv= linear_model.RidgeCV (alphas=[0.0001, 0.01, 0.1, 1])
- 弹性网:结合使用L1正则化和L2正则化
elasticNet = linear_model.ElasticNet()
elasticNetcv = linear_model.ElasticNetCV()
构建工作流
在本次拟合中,还用到了Pipeline构建工作流,对模型进行统一封装管理。
from sklearn.pipeline import Pipeline
clf = Pipeline(steps=[('name1': transform1), ('name2': transform2)
用sklearn的LinearRegression对数据进行拟合
import numpy as np
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import PolynomialFeatures
from sklearn import linear_model
import scipy as sp
from scipy.stats import norm
import matplotlib.pyplot as plt
""" 标准误差 """
def stdError_func(y_test, y):
return np.sqrt(np.mean((y_test-y)**2))
def R2_1_func(y_test, y):
return 1-((y_test-y)**2).sum() / ((y.mean() - y)**2).sum()
def R2_2_func(y_test, y):
y_mean = np.array(y)
y_mean[:] = y.mean()
return 1 - stdError_func(y_test, y) / stdError_func(y_mean, y)
x = np.linspace(0, 1, 500)
y = norm.rvs(loc=0, size=500, scale=0.1) ##生成随机分布, 增加抖动(噪声)
y = y + x**6
plt.scatter(x, y, s=5, color='black', alpha=0.8)
degrees = [2, 10, 200, 400]
for degree in degrees:
clf = Pipeline([('poly', PolynomialFeatures(degree=degree)),
('linear', linear_model.LinearRegression(fit_intercept=False))])
clf.fit(x[:, np.newaxis], y) ## 自变量需要二维数组
predict_y = clf.predict(x[:, np.newaxis])
strError = stdError_func(predict_y, y)
R2_1 = R2_1_func(predict_y, y)
R2_2 = R2_2_func(predict_y, y)
score = clf.score(x[:, np.newaxis], y) ##sklearn中自带的模型评估,与R2_1逻辑相同
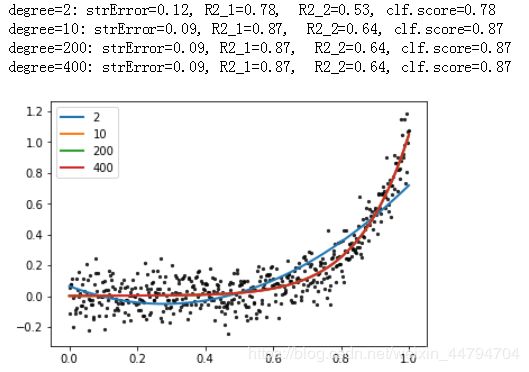
print 'degree={}: strError={:.2f}, R2_1={:.2f}, R2_2={:.2f}, clf.score={:.2f}'.format(
degree, strError,R2_1,R2_2,score)
plt.plot(x, predict_y, linewidth=2, label=degree)
plt.legend()
plt.show()

由结果可知,当多项式的阶数逐渐增加时,模型的效果也逐渐增加。但当到达一定阶数时,再增加阶数对模型的提升效果不大,甚至会出现过拟合现象(如degree=400)。此时统计拟合函数中有效阶数:
sum(clf.named_steps['linear'].coef_ != 0)
输出结果为401,即一些畸形系数导致拟合曲线畸形化。
接下来分别通过Lasso法和岭回归对模型进行纠正,改写PileLine的工作流为:
clf = Pipeline([('poly', PolynomialFeatures(degree=degree)), ('linear', linear_model.Lasso())]) ##Lasso法
clf = Pipeline([('poly', PolynomialFeatures(degree=degree)), ('linear', linear_model.RidgeCV())]) ##岭回归
- Lasso法结果:
- 岭回归结果

- 通过加入L1正则化或L2正则化作为惩罚项很好改善了过拟合的情况。此时拟合函数阶数项个数分别为8和400。
- 虽然加入惩罚项前后对比R2有所降低,但能更好地保证模型的表达性和预测性。