18、Spring Boot——整合Jpa
实际上我们学习Jpa也相当于变相的学习hibernate,我们现在是直接在SpringBoot中使用,如果我们在Spring+SpringMVC中使用就需要自己导Jpa的包,你会发现要导的Jpa的包,全部都是hibernate的包,那么Jpa和hibernate到底是什么关系呢?
什么是Jpa?
1、Java Persistence API:用于对象持久化的API
2、Java EE 5.0平台标准的ORM规范,使得应用程序以统一的方式访问持久层
Jpa和Hibernate的关系
1、Jpa是hibernate的一个抽象(就像JDBC和JDBC驱动的关系);
2、Jpa是规范:Jpa本质上就是一种ORM规范,不是ORM框架,这是因为Jpa并未提供ORM实现,它只是定制了一些规范,提供了一些编程的API接口,但具体实现则由ORM厂商提供实现;
3、hibernate是实现:hibernate除了作为ORM框架之外,它也是一种Jpa实现
4、从功能上来说,Jpa是hibernate功能的一个子集
Jpa的供应商
Jpa的目标之一是制定一个可以由很多供应商实现的API,hibernate3.2+,TopLink 10.1+以及OpenJpa都提供了Jpa的实现,jpa供应商有很多,常见的有如下四种:
1、Hibernate
Jpa的始作俑者就是hibernate的作者,hibernate从3.2开始兼容Jpa
2、OpenJPA
OpenJPA是Apache组织提供的开源项目
3、TopLink
TopLink以前需要收费,如今开源了
4、EclipseLink
JPA的优势
1、标准化:相同的API,这保证了基于Jpa开发的企业应用能够经过少量的修改就能够在不同的JPA框架下运行。
2、简单易用,集成方便:JPA的主要目标之一就是提供更加简单的编程模型,在JPA框架下创建实体和创建Java类一样简单,只需要使用javax.persistence.Entity进行注解;JPA的框架和接口也都非常简单。
3、可媲美JDBC的查询能力:JPA的查询语言是面向对象的,JPA定义了独特的JPQL,而且能够支持批量更新和修改、JOIN、GROUP BY、HAVING等通常只有SQL才能提供的高级查询特性,甚至还能支持子查询。
4、支持面向对象的高级特性:JPA中能够支持面向对象的高级特性,如类之间的继承、多态和类之间复杂关系,最大限度的使用面向对象的模型。
JPA包含的技术
1、ORM映射元数据:JPA支持XML和JDK5.0注解两种元数据的形式,元数据描述对象和表之间的映射关系,框架据此将实体对象持久化到数据库表中。
2、JPA的API:用来操作实体对象,执行CRUD操作,框架
在后台完成所有的事情,开发者从繁琐的JDBC和SQL代码中解脱出来。
3、查询语言(JPQL):这是持久化操作中很重要的一个方面,通过面向对象而非面向数据库的查询语言查询数据,避免程序和具体的SQL紧密耦合。
Spring Data
Spring Data是Spring的一个子项目。用于简化数据库访问,支持NoSQL和关系数据存储。其主要目标是使数据库的访问变得方便快捷,Spring Data具有以下特点:
1、Spring Data项目支持NoSQL存储:
MongoDB(文档数据库)
Neo4j(图形数据库)
Redis(键/值存储)
Hbase(列族数据库)
2、Spring Data项目所支持的关系数据存储技术:
JDBC
JPA
3、Spring Data Jpa致力于减少数据访问层(DAO)的开发量,开发者唯一要做的,就是声明持久层的接口,其他都交给Spring Data JPA来帮你完成
4、框架怎么可能替代开发者实现业务逻辑呢?比如:当有一个UserDao.findUserById()这样一个方法声明,大致应该能判断出这是根据给定条件的ID查询出满足条件的User对象。Spring Data JPA做的便是规范方法的名字,根据符合规范的名字来确定方法需要实现什么样的逻辑。
实例
创建一个工程,添加如下依赖:
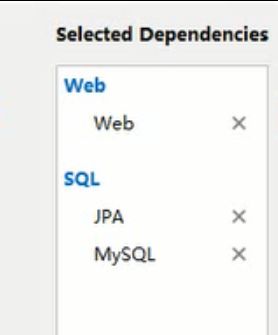
在pom.xml中锁定数据库的版本信息,添加数据库连接池和JPA的依赖:
mysql
mysql-connector-java
runtime
5.1.27
org.springframework.boot
spring-boot-starter-data-jpa
com.alibaba
druid-spring-boot-starter
1.1.10
application.properties配置文件的内容如下:
spring.datasource.username=root
spring.datasource.password=123456
spring.datasource.url=jdbc:mysql:///test
spring.datasource.type=com.alibaba.druid.pool.DruidDataSource
spring.datasource.driver-class-name=com.mysql.jdbc.Driver
#JPA相关:
#配置数据库平台
spring.jpa.properties.database-platform=mysql
#项目启动事更新数据库中的表,如果没有就创建,如果有就更新
spring.jpa.properties.hibernate.ddl-auto=update
#是否打印sql
spring.jpa.properties.show-sql=true
#数据库使用的方言
spring.jpa.properties.hibernate.dialect=org.hibernate.dialect.MySQL57Dialect
创建Book实体类:
//指定表名 项目启动的时候创建表,如果不指定表名,表名就是类名
@Entity(name = "t_book")
public class Book {
//所有的对象都要有id,没有id就创建不成功
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Integer id;
//指定数据表的字段名,并且该字段不能为null
@Column(name = "book_name",nullable = false)
private String name;
private String author;
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getAuthor() {
return author;
}
public void setAuthor(String author) {
this.author = author;
}
@Override
public String toString() {
return "Book{" +
"id=" + id +
", name='" + name + '\'' +
", author='" + author + '\'' +
'}';
}
}
注意:MYSQL的表名,在Windows里面是不区分大小写的,在Linux里面是区分大小写的,在开发中大部分都是在Windows下开发,在Linux下部署,所以以后写表名的时候,还是统一按照区分大小写来对待。
启动项目就可以在数据库中生成t_book表:
![]()

操作数据库
创建一个BookDao接口继承JpaRepository:
//接收两个泛型,第一个泛型是要操作的对象Book,第二个泛型是要操作的对象的主键的数据类型Integer
public interface BookDao extends JpaRepository {
}
测试
在单元测试中注解注入BookDao进行测试:
插入
@Autowired
BookDao bookDao;
@Test
public void contextLoads() {
Book book=new Book();
book.setAuthor("罗贯中");
book.setName("三国演义");
bookDao.save(book);
}
执行后就会在数据表中插入这条数据:
 修改
修改
@Test
public void test1(){
Book book = bookDao.findById(1).get();
book.setAuthor("罗贯中222");
bookDao.saveAndFlush(book);
//saveAndFlush方法,能更新就更新,不能更新就插入,视情况而定
}
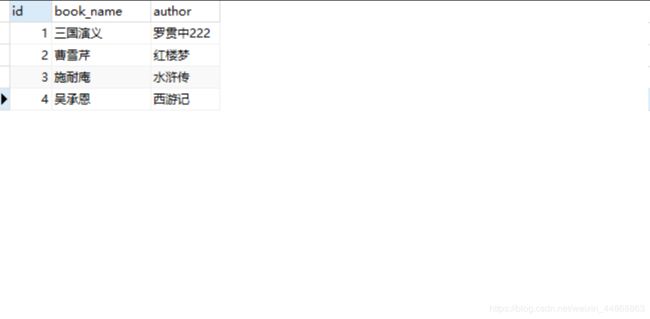
运行结果如下:
 排序查询
排序查询
在表中添加如下数据:
@Test
public void test2(){
//排序查询
List all = bookDao.findAll(Sort.by(new Sort.Order(Sort.Direction.DESC,"id")));
System.out.println(all);
}