【社区发现/图聚类算法】ppSCAN:Parallelizing Pruning-based Graph Structural Clustering
【社区发现/图聚类算法】ppSCAN:Parallelizing Pruning-based Graph Structural Clustering
- 一、论文地址:
- 二、摘要:
- 三、问题阐述:
- 四、基础算法:
- 五、分析和讨论:
- 5.1 性能瓶颈:
- 5.2 并行化的挑战:
- 六、并行化算法:
- 6.1 优化方法:
- 6.2 程序伪代码:
- Role Computing:
- Core and Non-Core Clustering:
- Degree-Based Dynamic Task Scheduling:
- Vectorized Pivot-based CompSim(u,v):
- 七、实验结果:
一、论文地址:
https://dl.acm.org/doi/10.1145/3225058.3225063
二、摘要:
SCAN算法是一种常见的图结构聚类算法,它不仅可以在顶点之间找到集群,还可以将顶点分类为核心顶点、桥顶点和离群点。但是,由于顶点之间的结构相似性需要大量的计算,这些算法存在效率问题。
基于剪枝的SCAN算法(即pSCAN算法)通过减少计算量来提高效率。然而,这种结构相似性计算仍然是性能瓶颈,特别是在有数十亿条边的大图上。
因此本文提出了在多核cpu和Intel Xeon Phi处理器(KNL)上并行化基于剪枝的SCAN算法。具体来说,这篇文章的作者设计了基于多相位(multi-phase)顶点计算的并行算法ppSCAN,以避免冗余计算,实现可扩展性。
此外,作者还提出了一种基于数据轴的向量集交算法(a pivot-based vectorized set intersection algorithm)来进行结构相似性计算。
实验结果表明,就线程数量而言,ppSCAN在CPU和KNL上都是可扩展的。在18亿个边的图friendster上,ppSCAN在KNL(64个超线程物理核心)上在65秒内完成。这种性能比单线程版本快100x-130x,在同一平台上比法pSCAN快250x。
三、问题阐述:
现有的算法(指的是2017年)都不支持对大图进行在线结构聚类。
为了解决性能问题,作者提出了一种基于多相位顶点计算的并行算法。pSCAN算法由于存在数据和顺序依赖性,不能直接对其进行并行化。相反,作者将SCAN的计算分解为两个步骤,即角色计算( role computing)和核心和非核心聚类(core and non-core clustering)。为了应用修剪技术,作者进一步将每个步骤分成多个阶段,并以无锁的方式并行化每个阶段。
作者将顶点计算捆绑到任务中,并使用基于顶点度的任务调度程序动态调度任务。调度器根据顶点角色和顶点度数的总和估计工作负载。当累计总数超过阈值时,就会提交任务,这有助于以可忽略的成本实现负载平衡。
为了提高集交的相似度计算速度,提出了一种基于数据轴的集交矢量化算法。该算法减少了条件比较,并使用向量化指令。此外,该集交算法保持了pSCAN引入的提前终止的优化方法。
四、基础算法:
SCAN算法:

pSCAN算法:

五、分析和讨论:
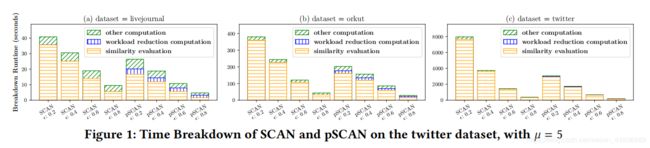
5.1 性能瓶颈:
相似度计算是性能瓶颈。在pSCAN中,即使相似计算量有所降低,在代表情况下(ϵ= 0.2,µ= 5),相似性计算仍然是费时的。
5.2 并行化的挑战:
研究pSCAN任务并行性的挑战是由依赖关系和并发问题引起的。并且现实网络中节点度数的倾斜给任务调度带来了挑战。此外,相似度计算的提前终止条件也使得数据并行性难以得到充分利用。
六、并行化算法:
为了解耦pSCAN的依赖关系,作者将核心检查和聚类分解为以下两大步骤:
(1)角色计算(核心顶点的检查和合并);
(2)核心集群和非核心集群最终生成集群。
此外,受相似谓词剪枝技术的启发,作者增加了一个预处理阶段,在此阶段,一些相似值和角色的确定不需要设置交集。
6.1 优化方法:
sd、ed依赖解耦:
(1)作者删除了基于ed[u]的最大优先级队列,因为它会导致严重的同步。
(2)用每个顶点的局部变量替换sd和ed数组,以消除数据竞争。
顶点顺序约束:
作者在核心顶点检测聚类中增加了约束u < v,以保证每个无向边(u,v)的相似度值最多计算一次,核心顶点聚类最多使用一次。
线程安全的聚类:
(1)核心集群操作采用wait-free union-find实现。
(2)对集群id的初始化采用比较和交换操作。
(3)在非核心顶点聚类中采用管线式设计,通过重叠计算局部非核id和聚类id对并复制回全局对数组。
多阶计算:
作者进一步将大步骤分解为应用剪枝技术和避免来自并发的工作负载冗余的阶段。
(1)为了应用相似值重用和最小最大修剪技术,作者将核心检查分为两个阶段:第一个阶段只在u < v时进行相似度计算,第二个阶段整合所有顶点的角色。
(2)为了充分利用union-find剪枝技术,作者将核心聚类分为两个阶段:第一个阶段是没有设置交叉点的核心聚类,第二个阶段是产生设置交叉点的核心聚类。
任务调度:
作者将一组顶点计算捆绑到一个任务中,并根据任务中顶点的度数和当前角色动态地将它们提交到线程池中。
6.2 程序伪代码:
Role Computing:

Core and Non-Core Clustering:

Degree-Based Dynamic Task Scheduling:

Vectorized Pivot-based CompSim(u,v):

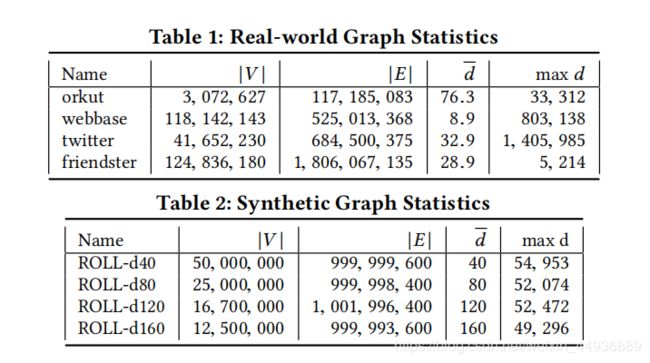
七、实验结果: